
Introduction
Practice makes perfect.
Something that has a lot in common with being a data scientist. Theory is only one aspect of the equation; the most crucial aspect is putting theory into practice. I will make an effort to record today's entire process of developing my capstone project, which will involve studying a movie dataset.
These are the objectives:
Objective:
1. Data Collection
I decided to use Kaggle to find my dataset.It is crucial to keep in mind the crucial variables you will want for the dataset you are working with. Importantly, my dataset ought to include the following: trends in release year, popularity of directors, ratings, and movie genres. As a result, I must make sure the dataset I choose has the following, at the very least.
My dataset was located on Kaggle, and I'll provide the link below. You can obtain the CSV version of the file by downloading the dataset, unzipping it, and extracting it. You can look over it to comprehend what you already have and to truly realize what kinds of insights you hope to obtain from the data you will be examining.
2. Describing the data
First, we must import the required libraries and load the necessary data. I'm using the Python programming language and Jupyter Notebooks for my project so that I can write and see my code more efficiently.
You will import the libraries that we will be using and load the data as shown below.
We will then run the following command to get more details about our dataset.
data.head() # dispalys the first rows of the dataset. data.tail() # displays the last rows of the dataset. data.shape # Shows the total number of rows and columns. len(data.columns) # Shows the total number of columns. data.columns # Describes different column names. data.dtypes # Describes different data types.
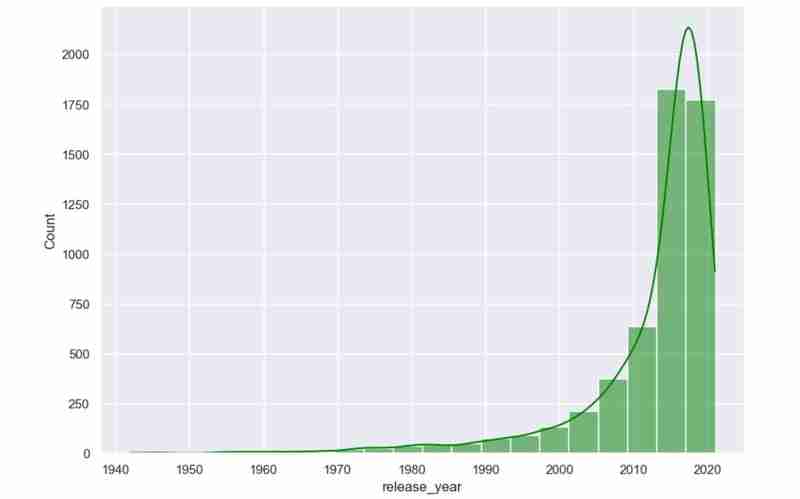
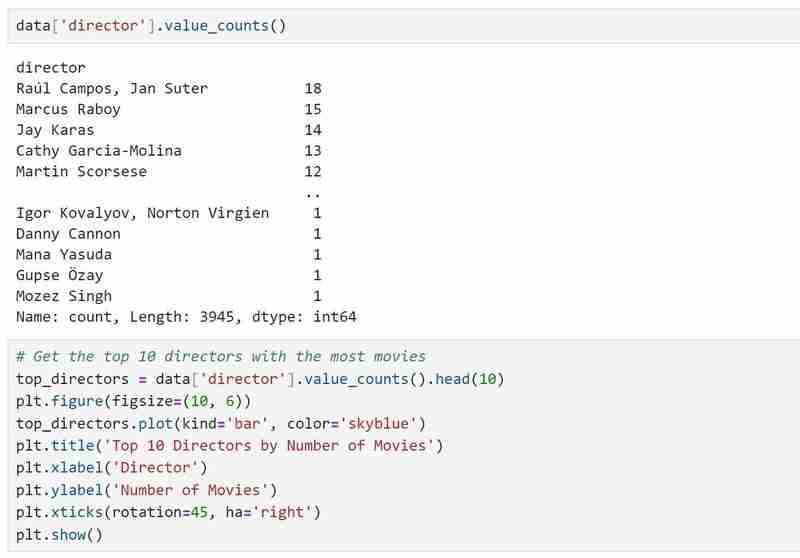
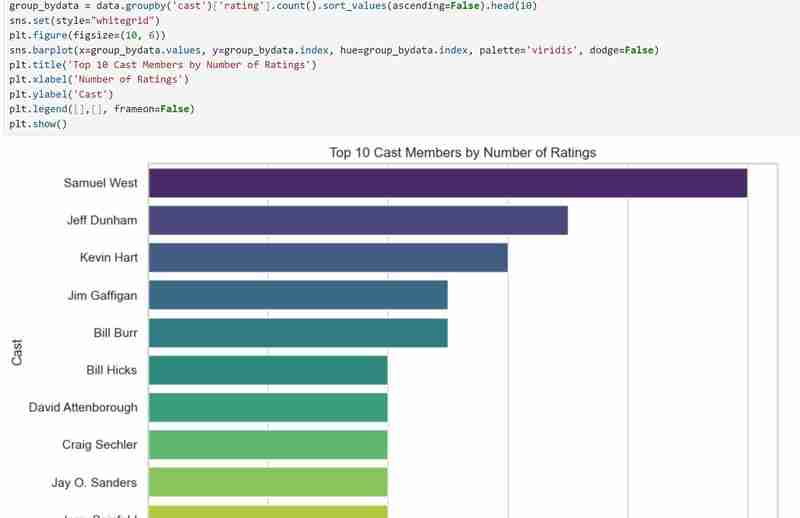
We now know what the dataset comprises and the insights we hope to extract after obtaining all the descriptions we require. Example: Using my dataset, I wish to investigate patterns in the popularity of directors, ratings distribution, and movie genres. I also want to suggest movies depending on user-selected preferences, such as preferred directors and genres.
3. Data Cleaning
This phase involves finding any null values and removing them. In order to move on with data visualization, we will also examine our dataset for duplicates and remove any that we find. To do this, we'll run the code that follows:
1. data['show_id'].value_counts().sum() # Checks for the total number of rows in my dataset 2. data.isna().sum() # Checks for null values(I found null values in director, cast and country columns) 3. data[['director', 'cast', 'country']] = data[['director', 'cast', 'country']].replace(np.nan, "Unknown ") # Fill null values with unknown.
We will then drop the rows with unknown values and confirm we have dropped all of them. We will also check the number of rows remaining that have cleaned data.
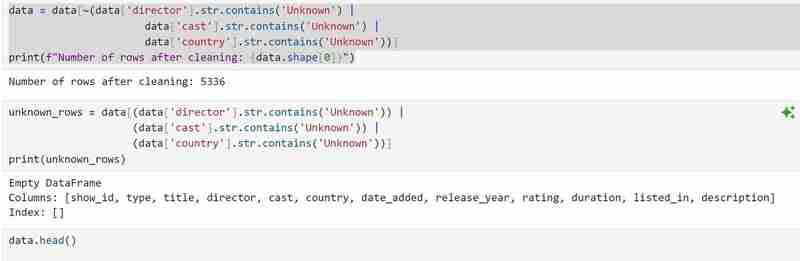
The code that follows looks for unique characteristics and duplicates. Although there are no duplicates in my dataset, you might still need to utilize it in case future datasets do.
data.duplicated().sum() # Checks for duplicates data.nunique() # Checks for unique features data.info # Confirms if nan values are present and also shows datatypes.
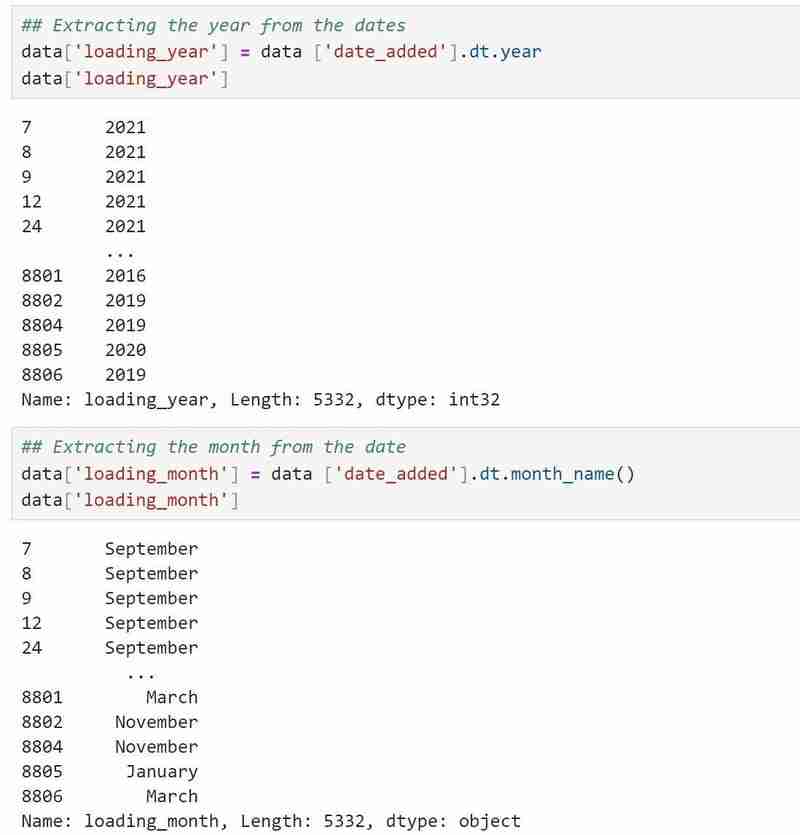
My date/time data type is an object and I would like for it to be in the proper date/time format so I used
data['date_added']=data['date_added'].astype('datetime64[ms]')to convert it to the proper format.
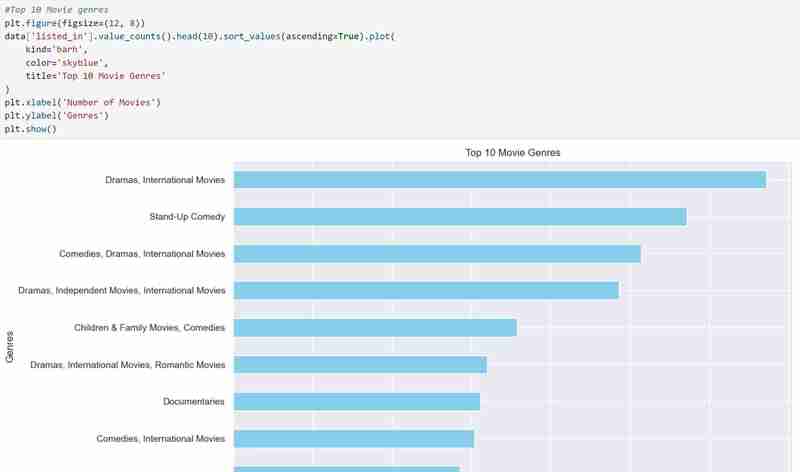
4. Data Visualization
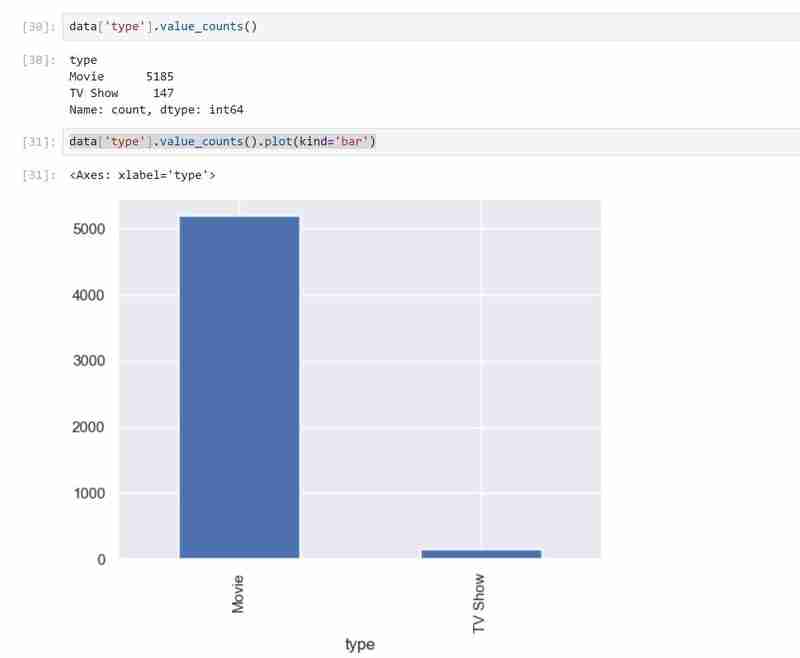
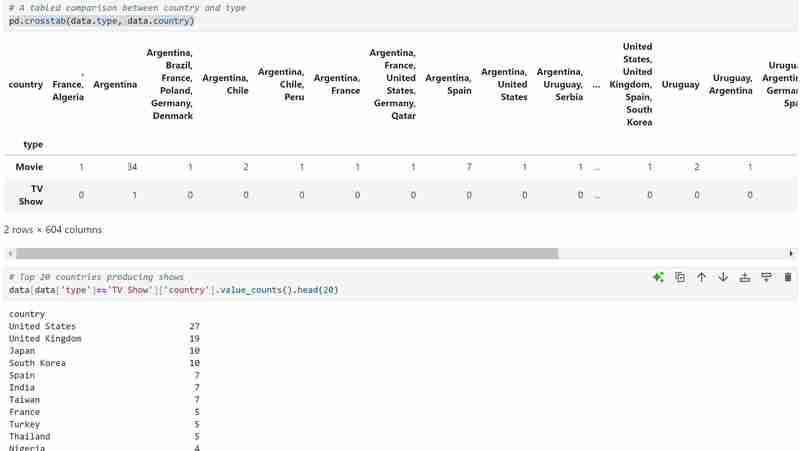
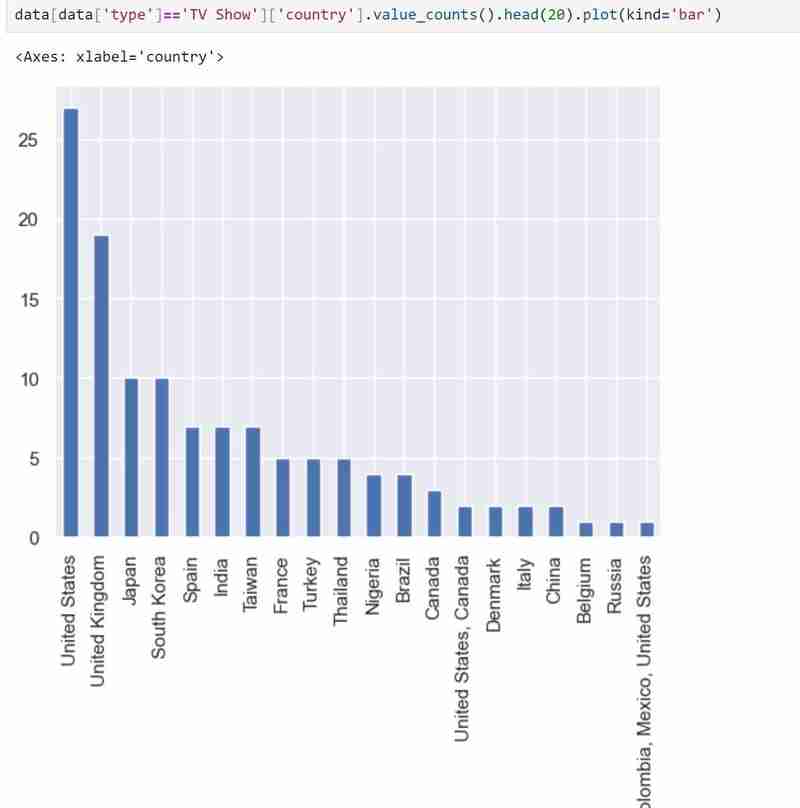
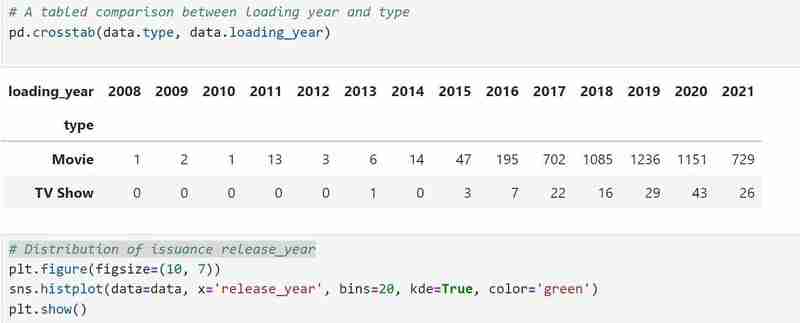
My dataset has two types of variables namely the TV shows and Movies in the types and I used a bar graph to present the categorical data with the values that they represent.
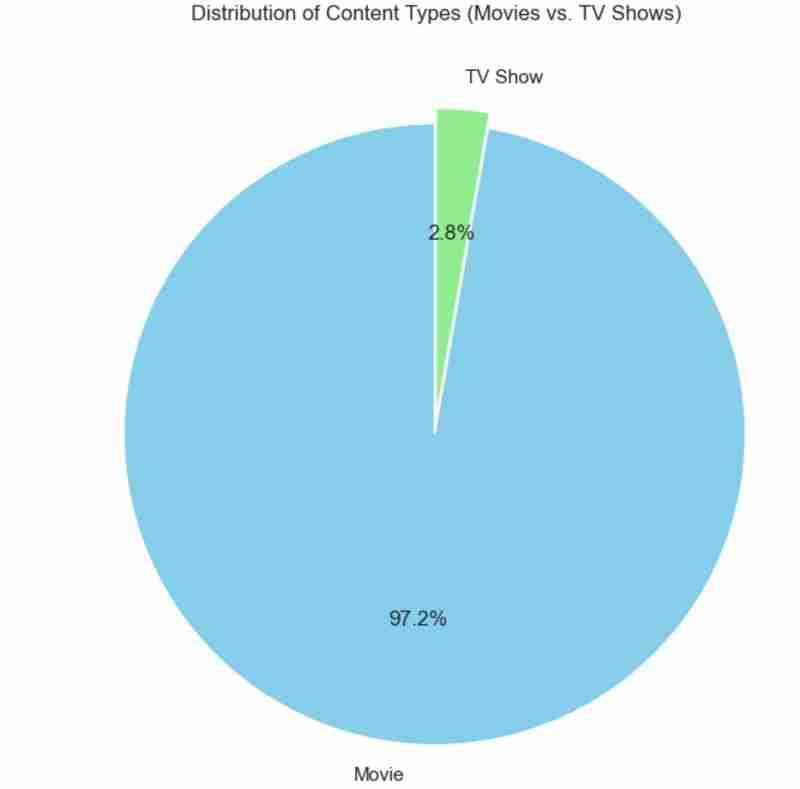
I also used a pie chart to represent the same as above. The code used is as follows and the outcome expected shown below.
## Pie chart display
plt.figure(figsize=(8, 8))
data['type'].value_counts().plot(
kind='pie',
autopct='%1.1f%%',
colors=['skyblue', 'lightgreen'],
startangle=90,
explode=(0.05, 0)
)
plt.title('Distribution of Content Types (Movies vs. TV Shows)')
plt.ylabel('')
plt.show()
5. Recommendation System
I then built a recommendation system that takes in genre or director's name as input and produces a list of movies as per the user's preference. If the input cannot be matched by the algorithm then the user is notified.

The code for the above is as follows:
def recommend_movies(genre=None, director=None):
recommendations = data
if genre:
recommendations = recommendations[recommendations['listed_in'].str.contains(genre, case=False, na=False)]
if director:
recommendations = recommendations[recommendations['director'].str.contains(director, case=False, na=False)]
if not recommendations.empty:
return recommendations[['title', 'director', 'listed_in', 'release_year', 'rating']].head(10)
else:
return "No movies found matching your preferences."
print("Welcome to the Movie Recommendation System!")
print("You can filter movies by Genre or Director (or both).")
user_genre = input("Enter your preferred genre (or press Enter to skip): ")
user_director = input("Enter your preferred director (or press Enter to skip): ")
recommendations = recommend_movies(genre=user_genre, director=user_director)
print("\nRecommended Movies:")
print(recommendations)
Conclusion
My goals were achieved, and I had a great time taking on this challenge since it helped me realize that, even though learning is a process, there are days when I succeed and fail. This was definitely a success. Here, we celebrate victories as well as defeats since, in the end, each teach us something. Do let me know if you attempt this.
Till next time!
Note!!
The code is in my GitHub:
https://github.com/MichelleNjeri-scientist/Movie-Dataset-Exploration-and-Visualization
The Kaggle dataset is:
https://www.kaggle.com/datasets/shivamb/netflix-shows
以上是電影資料集探索與視覺化的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















