

我的第一個開源貢獻

提交問題
對於我的第一個貢獻,我提交了一個問題以向另一個項目添加新功能,即添加一個新的標誌選項來顯示用於提示和完成生成的令牌。
 功能:聊天完成令牌資訊標誌選項
#8
功能:聊天完成令牌資訊標誌選項
#8
 功能:聊天完成令牌資訊標誌選項
#8
功能:聊天完成令牌資訊標誌選項
#8

描述
一個標誌選項,為使用者提供發送和接收的令牌計數。 我認為這是一個重要的功能,可以引導用戶在發出聊天完成請求時保持在代幣預算之內!
實作
為此,我們需要添加另一個選項標誌,可以是 -t 和 --token-usage。當使用者在命令中包含此標誌時,它應該清楚地詳細顯示在生成完成過程中使用了多少個令牌,以及在提示中使用了多少個令牌。
我選擇為fadingNA 的開源專案chat-minal 做出貢獻,這是一個用Python 編寫的CLI 工具,允許您利用OpenAI 來做各種事情,例如使用它生成程式碼審查、檔案轉換、產生Markdown文本和摘要文本。
我的拉取請求
我以前用Python寫過程式碼,但這不是我最強的技能。因此,為這個專案做出貢獻為我提供了具有挑戰性但良好的學習經驗。
挑戰在於我必須閱讀和理解別人的程式碼,並以不破壞程式碼設計的方式提供正確的解決方案。理解流程至關重要,這樣我就可以有效地添加功能,而無需對程式碼進行大的更改並保持程式碼一致。
FEAT:代幣使用標誌
#9
功能
新增了為使用者新增 --token_usage 標誌選項的功能。 此選項向使用者提供用於提示和產生完成的令牌數量的資訊。
實作
我根據程式碼設計提出的解決方案是檢查 token_usage 標誌是否存在。 如果未使用 token_usage 標誌,我不希望程式碼檢查任何不必要的 if 語句,因此我製作了兩個單獨的相同循環邏輯,不同之處在於檢查區塊內是否存在 use_metadata。
if token_usage:
for chunk in runnable.stream({"input_text": input_text}):
print(chunk.content, end="", flush=True)
answer.append(chunk.content)
if chunk.usage_metadata:
completion_tokens = chunk.usage_metadata.get('output_tokens')
prompt_tokens = chunk.usage_metadata.get('input_tokens')
else:
for chunk in runnable.stream({"input_text": input_text}):
print(chunk.content, end="", flush=True)
answer.append(chunk.content)顯示
At the end of the execution of get_completions() method, a check for the flag token_usage is added, which then displays the token usage details to stderr if the flag was used.
if token_usage:
logger.error(f"Tokens used for completion: <span class="pl-s1"><span class="pl-kos">{completion_tokens}</span>"</span>)
logger.error(f"Tokens used for prompt: <span class="pl-s1"><span class="pl-kos">{prompt_tokens}</span>"</span>)My solution
Retrieving the token usage
if token_usage:
for chunk in runnable.stream({"input_text": input_text}):
print(chunk.content, end="", flush=True)
answer.append(chunk.content)
if chunk.usage_metadata:
completion_tokens = chunk.usage_metadata.get('output_tokens')
prompt_tokens = chunk.usage_metadata.get('input_tokens')
else:
for chunk in runnable.stream({"input_text": input_text}):
print(chunk.content, end="", flush=True)
answer.append(chunk.content)
Originally, the code only had one for loop which retrieves the content from a stream and appends it to an array which forms the response of the completion.
Why did I write it this way?
My reasoning behind duplicating the for while adding the distinct if block is to prevent the code from repeatedly checking the if block even if the user is not using the newly added --token_usage flag. So instead, I check for the existence of the flag firstly, and then decide which for loop to execute.
Realization
Even though my pull request has been accepted by the project owner, I realized late that this way adds complexity to the code's maintainability. For example, if there are changes required in the for loop for processing the stream, that means modifying the code twice since there are two identical for loops.
What I think I could do as an improvement for it is to make it into a function so that any changes required can be done in one function only, keeping the maintainability of the code. This just proves that even if I wrote the code with optimization in mind, there are still other things that I can miss which is crucial to a project, which in this case, is maintainability.
Receiving a pull request
My tool, genereadme, also received a contribution. I received a PR from Mounayer, which is to add the same feature to my project.
feat: added a new flag that displays the number of tokens sent in prompt and received in completion
#13

Description
Closes #12.
- Added a new flag --token-usage which when given, prints the number of tokens that were sent in the prompt and the number of tokens that were returned in the completion to `stderr.
This simply required the addition for another flag check --token-usage:
.option("--token-usage", "Show prompt and completion token usage")I've also made sure to keep your naming conventions/formatting style consistent, in the for loop that does the chat completion for each file processed, I have accumulated the total tokens sent and received:
promptTokens += response.usage.prompt_tokens;
completionTokens += response.usage.completion_tokens;which I then display at the end of program run-time if the --token-usage flag is provided as such:
if (program.opts().tokenUsage) {
console.error(`Prompt tokens: <span class="pl-s1"><span class="pl-kos">${promptTokens}</span>`</span>);
console.error(`Completion tokens: <span class="pl-s1"><span class="pl-kos">${completionTokens}</span>`</span>);
}- Updated README.md to explain the new flag.
Testing
Test 1
genereadme examples/sum.js --token-usage
This should display something like:
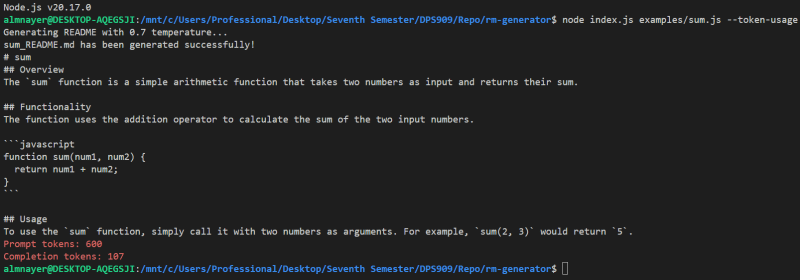
Test 2
You can try it out with multiple files too, i.e.:
genereadme examples/sum.js examples/createUser.js --token-usage
This time, instead of having to read someone else's code, someone had to read mine and contribute to it. It is nice knowing that someone is able to contribute to my project. To me, it means that they understood how my code works, so they were able to add the feature without breaking anything or adding any complexity to the code base.
With that being mentioned, reading code is also a skill that is not to be underestimated. My code is nowhere near perfect and I know there are still places I can improve on, so credit is also due to being able to read and understand code.
This specific pull request did not really require any back and forth changes as the code that was written by Mounayer is what I would have written myself.
以上是我的第一個開源貢獻的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 Python vs.C:申請和用例
Apr 12, 2025 am 12:01 AM
Python vs.C:申請和用例
Apr 12, 2025 am 12:01 AM
Python适合数据科学、Web开发和自动化任务,而C 适用于系统编程、游戏开发和嵌入式系统。Python以简洁和强大的生态系统著称,C 则以高性能和底层控制能力闻名。
 您可以在2小時內學到多少python?
Apr 09, 2025 pm 04:33 PM
您可以在2小時內學到多少python?
Apr 09, 2025 pm 04:33 PM
兩小時內可以學到Python的基礎知識。 1.學習變量和數據類型,2.掌握控制結構如if語句和循環,3.了解函數的定義和使用。這些將幫助你開始編寫簡單的Python程序。
 2小時的Python計劃:一種現實的方法
Apr 11, 2025 am 12:04 AM
2小時的Python計劃:一種現實的方法
Apr 11, 2025 am 12:04 AM
2小時內可以學會Python的基本編程概念和技能。 1.學習變量和數據類型,2.掌握控制流(條件語句和循環),3.理解函數的定義和使用,4.通過簡單示例和代碼片段快速上手Python編程。
 Python:遊戲,Guis等
Apr 13, 2025 am 12:14 AM
Python:遊戲,Guis等
Apr 13, 2025 am 12:14 AM
Python在遊戲和GUI開發中表現出色。 1)遊戲開發使用Pygame,提供繪圖、音頻等功能,適合創建2D遊戲。 2)GUI開發可選擇Tkinter或PyQt,Tkinter簡單易用,PyQt功能豐富,適合專業開發。
 Python與C:學習曲線和易用性
Apr 19, 2025 am 12:20 AM
Python與C:學習曲線和易用性
Apr 19, 2025 am 12:20 AM
Python更易學且易用,C 則更強大但複雜。 1.Python語法簡潔,適合初學者,動態類型和自動內存管理使其易用,但可能導致運行時錯誤。 2.C 提供低級控制和高級特性,適合高性能應用,但學習門檻高,需手動管理內存和類型安全。
 Python和時間:充分利用您的學習時間
Apr 14, 2025 am 12:02 AM
Python和時間:充分利用您的學習時間
Apr 14, 2025 am 12:02 AM
要在有限的時間內最大化學習Python的效率,可以使用Python的datetime、time和schedule模塊。 1.datetime模塊用於記錄和規劃學習時間。 2.time模塊幫助設置學習和休息時間。 3.schedule模塊自動化安排每週學習任務。
 Python:探索其主要應用程序
Apr 10, 2025 am 09:41 AM
Python:探索其主要應用程序
Apr 10, 2025 am 09:41 AM
Python在web開發、數據科學、機器學習、自動化和腳本編寫等領域有廣泛應用。 1)在web開發中,Django和Flask框架簡化了開發過程。 2)數據科學和機器學習領域,NumPy、Pandas、Scikit-learn和TensorFlow庫提供了強大支持。 3)自動化和腳本編寫方面,Python適用於自動化測試和系統管理等任務。
 Python:自動化,腳本和任務管理
Apr 16, 2025 am 12:14 AM
Python:自動化,腳本和任務管理
Apr 16, 2025 am 12:14 AM
Python在自動化、腳本編寫和任務管理中表現出色。 1)自動化:通過標準庫如os、shutil實現文件備份。 2)腳本編寫:使用psutil庫監控系統資源。 3)任務管理:利用schedule庫調度任務。 Python的易用性和豐富庫支持使其在這些領域中成為首選工具。
