
誰不想從他們的文件中得到即時答案?這正是 RAG 聊天機器人所做的事——將檢索與人工智慧生成相結合,以實現快速、準確的回應!
在本指南中,我將向您展示如何使用 檢索增強生成 (RAG) 以及 LangChain 和 Streamlit 創建聊天機器人。該聊天機器人將從知識庫中提取相關資訊並使用語言模型產生回應。
我將引導您完成每個步驟,提供多種回應產生選項,無論您使用OpenAI、Gemini 或Fireworks — 確保靈活且具有成本效益的解決方案。
RAG 是一種結合了檢索和產生的方法,以提供更準確和上下文感知的聊天機器人回應。檢索過程從知識庫中提取相關文檔,而生成過程則使用語言模型根據檢索到的內容創建連貫的回應。這可確保您的聊天機器人可以使用最新資料回答問題,即使語言模型本身尚未針對該資訊進行專門訓練。
想像一下您有一位私人助理,但他並不總是知道您問題的答案。因此,當你提出問題時,他們會翻閱書籍並找到相關資訊(檢索),然後他們總結這些資訊並用自己的話告訴你(產生)。這本質上就是 RAG 的工作原理,結合了兩全其美的優點。
在流程圖中,RAG 流程有點像這樣:
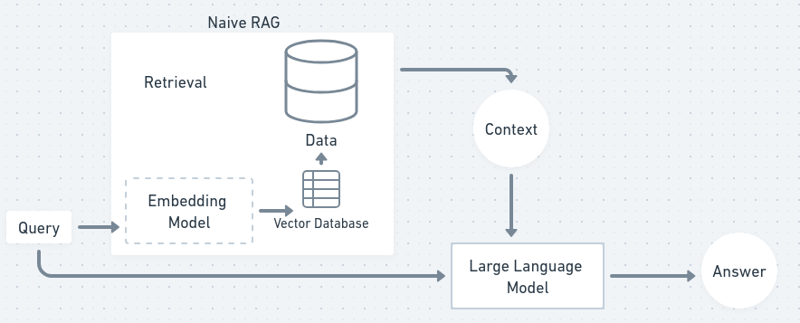
現在,讓我們開始吧,建立我們自己的聊天機器人!
本教學中我們將主要使用 Python,如果您是 JS 頭,您可以按照說明並瀏覽 langchain js 的文檔。
首先,我們需要設定專案環境。這包括建立專案目錄、安裝依賴項以及為不同語言模型設定 API 金鑰。
先建立專案資料夾與虛擬環境:
mkdir rag-chatbot cd rag-chatbot python -m venv venv source venv/bin/activate
接下來,建立一個requirements.txt 檔案來列出所有必要的依賴項:
langchain==0.0.329 streamlit==1.27.2 faiss-cpu==1.7.4 python-dotenv==1.0.0 tiktoken==0.5.1 openai==0.27.10 gemini==0.3.1 fireworks==0.4.0 sentence_transformers==2.2.2
現在,安裝這些相依性:
pip install -r requirements.txt
我們將使用 OpenAI、Gemini 或 Fireworks 來產生聊天機器人的回應。您可以根據自己的喜好選擇其中任何一個。
如果您正在嘗試,請不要擔心,Fireworks 免費提供價值 1 美元的 API 金鑰,gemini-1.5-flash 型號在一定程度上也是免費的!
設定 .env 檔案來儲存您首選模型的 API 金鑰:
mkdir rag-chatbot cd rag-chatbot python -m venv venv source venv/bin/activate
請務必註冊這些服務並取得您的 API 金鑰。 Gemini 和 Fireworks 皆提供免費套餐,而 OpenAI 依使用情況收費。
為了提供聊天機器人上下文,我們需要處理文件並將它們分成可管理的區塊。這很重要,因為需要分解大文本以進行嵌入和索引。
建立一個名為 document_processor.py 的新 Python 腳本來處理文件處理:
langchain==0.0.329 streamlit==1.27.2 faiss-cpu==1.7.4 python-dotenv==1.0.0 tiktoken==0.5.1 openai==0.27.10 gemini==0.3.1 fireworks==0.4.0 sentence_transformers==2.2.2
此腳本載入一個文字文件,並將其分割成約 1000 個字元的較小區塊,並有少量重疊,以確保區塊之間不會遺失上下文。處理完成後,文件就可以嵌入並建立索引了。
現在我們已經對文件進行了分塊,下一步是將它們轉換為嵌入(文字的數字表示)並為它們建立索引以便快速檢索。 (因為機器理解數字比理解單字更容易)
建立另一個名為 embedding_indexer.py 的腳本:
pip install -r requirements.txt
在此腳本中,嵌入是使用 Hugging Face 模型(all-MiniLM-L6-v2)建立的。然後,我們將這些嵌入儲存在 FAISS 向量儲存中,這使我們能夠根據查詢快速檢索相似的文字區塊。
令人興奮的部分來了:將檢索與語言生成結合!現在,您將建立一個 RAG 鏈 ,它從向量儲存中取得相關區塊並使用語言模型產生回應。 (向量儲存是一個資料庫,我們儲存轉換為數字作為向量的資料)
讓我們建立檔案 rag_chain.py:
# Uncomment your API key # OPENAI_API_KEY=your_openai_api_key_here # GEMINI_API_KEY=your_gemini_api_key_here # FIREWORKS_API_KEY=your_fireworks_api_key_here
在這裡,我們根據您提供的 API 金鑰在 OpenAI、Gemini 或 Fireworks 之間進行選擇。 RAG 鏈將檢索前 3 個最相關的文檔,並使用語言模型產生回應。
您可以根據自己的預算或使用偏好在模型之間切換 - Gemini 和 Fireworks 是免費的,而 OpenAI 根據使用情況收費。
現在,我們將建立一個簡單的聊天機器人介面,以使用我們的 RAG 鏈獲取用戶輸入並產生回應。
建立一個名為chatbot.py的新檔案:
mkdir rag-chatbot cd rag-chatbot python -m venv venv source venv/bin/activate
此腳本建立一個命令列聊天機器人介面,持續偵聽使用者輸入,透過 RAG 鏈對其進行處理,並傳回產生的回應。
是時候使用 Streamlit 建立 Web 介面,讓您的聊天機器人更加用戶友好。這將允許用戶透過瀏覽器與您的聊天機器人互動。
建立app.py:
langchain==0.0.329 streamlit==1.27.2 faiss-cpu==1.7.4 python-dotenv==1.0.0 tiktoken==0.5.1 openai==0.27.10 gemini==0.3.1 fireworks==0.4.0 sentence_transformers==2.2.2
要運行您的 Streamlit 應用程序,只需使用:
pip install -r requirements.txt
這將啟動一個網頁介面,您可以在其中上傳文字檔案、提出問題並從聊天機器人接收答案。
為了獲得更好的效能,您可以在分割文字時嘗試區塊大小和重疊。較大的區塊提供更多上下文,但較小的區塊可能使檢索速度更快。您也可以使用 Streamlit 快取 來避免重複產生嵌入等昂貴的操作。
如果您想要最佳化成本,可以依照查詢複雜度在OpenAI、Gemini 或Fireworks 之間切換— 使用OpenAI對於複雜的問題,Gemini 或Fireworks 對於更簡單的問題以降低成本。
以上是創建您自己的 AI RAG 聊天機器人:LangChain 的 Python 指南的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















