
請我喝杯咖啡☕
*備忘錄:
有批次梯度下降(BGD)、小批量梯度下降(MBGD)和隨機梯度下降(SGD),它們是如何從資料集中取得資料使用梯度下降的方法最佳化器,例如Adam ()、SGD()、RMSprop()、Adadelta()、Adagrad() 等PyTorch。
*備忘錄:
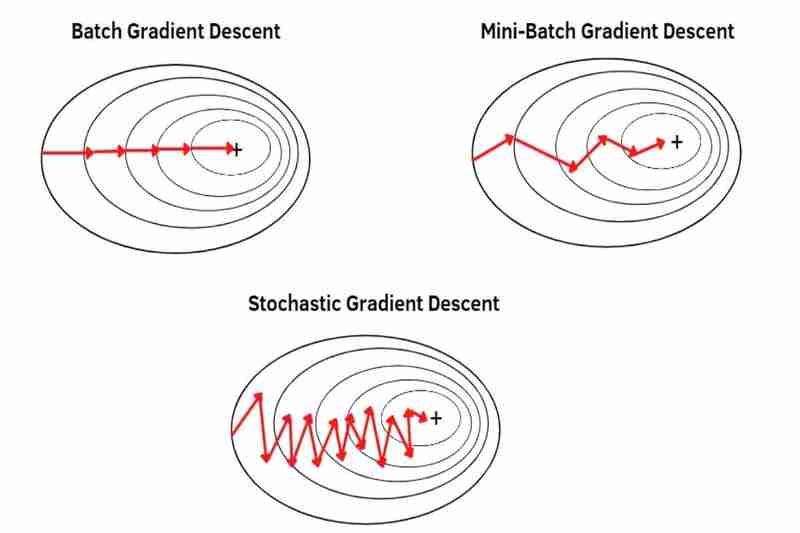
(1) 批次梯度下降(BGD):
(2)小批量梯度下降(MBGD):
使用從整個資料集中分割出來的每個小批次的平均值,因此每個樣本比 BDG 更突出(更強調)。 *將整個資料集分成更小的批次可以使每個樣本越來越突出(越來越強調)。因此,收斂比BGD 更不穩定(波動更大),且雜訊(雜訊資料)也比BGD 弱,比BGD 更容易導致過衝,並且即使沒有陷入局部極小值,也會創造比BGD 更不準確的模型,但MBGD 比BGD 更容易逃脫局部最小值或鞍點,因為正如我之前所說,收斂比BGD 更不穩定(波動更大),MBGD 比BGD更不容易導致過擬合,因為每個樣本都更穩定正如我之前所說,out(更強調)比 BGD 更重要。
的優點:
的缺點:
(3) 隨機梯度下降(SGD):
使用整個資料集的每一個樣本逐個樣本而不是平均值,因此每個樣本比 MBGD 更突出(更強調)。因此,收斂比MBGD 更不穩定(更波動),而且雜訊(雜訊資料)也比MBGD 弱,比MBGD 更容易導致過衝,並且即使沒有陷入局部極小值,也會創造比MBGD 更不準確的模型,但SGD 比MBGD 更容易逃脫局部極小值或鞍點,因為正如我之前所說,收斂比MBGD 更不穩定(波動更大),而且SGD 比MBGD更不容易導致過擬合,因為每個樣本都更穩定正如我之前所說,out(更強調)比MBGD。
的優點:
的缺點:
以上是批量、小批量和隨機梯度下降的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















