
抓取 Google 搜尋可提供基本的 SERP 分析、SEO 最佳化和資料收集功能。現代抓取工具使這個過程更快、更可靠。
我們的一位社群成員撰寫了此博客,作為對 Crawlee 博客的貢獻。如果您想向 Crawlee 博客貢獻此類博客,請透過我們的 Discord 頻道與我們聯繫。
在本指南中,我們將使用 Crawlee for Python 建立一個 Google 搜尋抓取工具,可以處理結果排名和分頁。
我們將建立一個抓取工具:
安裝 Crawlee 所需的依賴:
pipx install crawlee[beautifulsoup,curl-impersonate]
使用 Crawlee CLI 建立一個新專案:
pipx run crawlee create crawlee-google-search
出現提示時,選擇 Beautifulsoup 作為您的範本類型。
導覽至專案目錄並完成安裝:
cd crawlee-google-search poetry install
首先,讓我們先定義提取範圍。谷歌的搜尋結果現在包括地圖、名人、公司詳細資訊、影片、常見問題和許多其他元素。我們將重點分析帶有排名的標準搜尋結果。
這是我們要提取的內容:

我們來驗證是否可以從頁面的HTML程式碼中提取必要的數據,或者是否需要更深入的分析或JS渲染。請注意,此驗證對 HTML 標籤敏感:

根據從頁面取得的數據,所有必要的資訊都存在於 HTML 程式碼中。因此,我們可以使用beautifulsoup_crawler。
我們將提取的欄位:
首先,讓我們建立爬蟲配置。
我們將使用 CurlImpersonateHttpClient 作為預設標頭的 http_client,並模擬與 Chrome 瀏覽器相關的內容。
我們也會配置 ConcurrencySettings 來控制抓取攻擊性。這對於避免被 Google 封鎖至關重要。
如果您需要更集中地提取數據,請考慮設定ProxyConfiguration。
pipx install crawlee[beautifulsoup,curl-impersonate]
首先我們來分析一下需要擷取的元素的HTML程式碼:

可讀 ID 屬性和產生 類別名稱和其他屬性之間有明顯差異。建立用於資料擷取的選擇器時,您應該忽略任何產生的屬性。即使您已經了解到 Google 已經使用特定的生成標籤 N 年了,您也不應該依賴它 - 這反映了您編寫健壯程式碼的經驗。
現在我們了解了 HTML 結構,讓我們來實作擷取。由於我們的爬蟲只處理一種類型的頁面,因此我們可以使用 router.default_handler 來處理它。在處理程序中,我們將使用 BeautifulSoup 迭代每個搜尋結果,在儲存結果時提取標題、url 和 text_widget 等資料。
pipx run crawlee create crawlee-google-search
由於 Google 結果取決於搜尋請求的 IP 地理位置,因此我們不能依賴連結文字進行分頁。我們需要創建一個更複雜的 CSS 選擇器,無論地理位置和語言設定如何,它都可以工作。
max_crawl_depth 參數控制我們的爬蟲應該掃描多少頁面。一旦我們有了強大的選擇器,我們只需獲取下一頁連結並將其添加到爬蟲隊列中即可。
要編寫更有效率的選擇器,請學習 CSS 和 XPath 語法的基礎知識。
cd crawlee-google-search poetry install
由於我們希望以方便的表格格式(例如 CSV)保存所有搜尋結果數據,因此我們可以在運行爬蟲後立即添加 export_data 方法呼叫:
from crawlee.beautifulsoup_crawler import BeautifulSoupCrawler
from crawlee.http_clients.curl_impersonate import CurlImpersonateHttpClient
from crawlee import ConcurrencySettings, HttpHeaders
async def main() -> None:
concurrency_settings = ConcurrencySettings(max_concurrency=5, max_tasks_per_minute=200)
http_client = CurlImpersonateHttpClient(impersonate="chrome124",
headers=HttpHeaders({"referer": "https://www.google.com/",
"accept-language": "en",
"accept-encoding": "gzip, deflate, br, zstd",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
}))
crawler = BeautifulSoupCrawler(
max_request_retries=1,
concurrency_settings=concurrency_settings,
http_client=http_client,
max_requests_per_crawl=10,
max_crawl_depth=5
)
await crawler.run(['https://www.google.com/search?q=Apify'])
雖然我們的核心爬蟲邏輯有效,但您可能已經注意到我們的結果目前缺乏排名位置資訊。為了完成我們的抓取工具,我們需要透過使用請求中的 user_data 在請求之間傳遞資料來實現正確的排名位置追蹤。
讓我們修改腳本來處理多個查詢並追蹤搜尋結果分析的排名位置。我們還將爬行深度設定為頂級變數。讓我們將 router.default_handler 移至 paths.py 以符合專案結構:
@crawler.router.default_handler
async def default_handler(context: BeautifulSoupCrawlingContext) -> None:
"""Default request handler."""
context.log.info(f'Processing {context.request} ...')
for item in context.soup.select("div#search div#rso div[data-hveid][lang]"):
data = {
'title': item.select_one("h3").get_text(),
"url": item.select_one("a").get("href"),
"text_widget": item.select_one("div[style*='line']").get_text(),
}
await context.push_data(data)
我們也可以修改處理程序以新增 query 和 order_no 欄位以及基本錯誤處理:
await context.enqueue_links(selector="div[role='navigation'] td[role='heading']:last-of-type > a")
我們就完成了!
我們的 Google 搜尋抓取工具已準備就緒。讓我們來看看 google_ranked.csv 檔案中的結果:
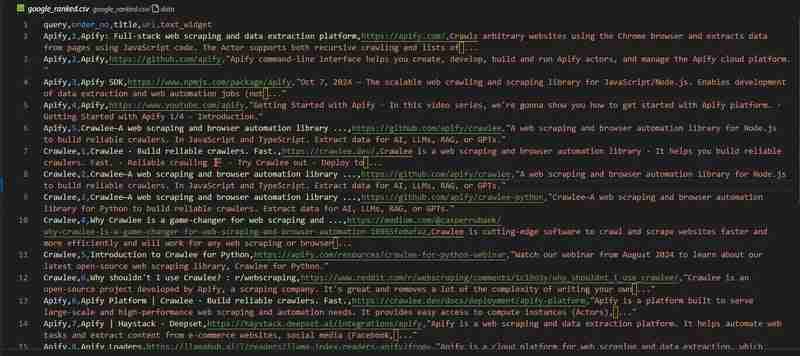
程式碼儲存庫可在 GitHub 上取得
如果您正在從事需要數百萬個數據點的大型項目,例如本文中有關 Google 排名分析的項目 - 您可能需要一個現成的解決方案。
考慮使用 Apify 團隊開發的 Google 搜尋結果抓取工具。
它提供了重要的功能,例如:
您可以在 Apify 部落格中了解更多
在本部落格中,我們逐步探索如何建立收集排名資料的 Google 搜尋抓取工具。如何分析此數據集取決於您!
溫馨提示,您可以在 GitHub 上找到完整的專案代碼。
我想 5 年後我需要寫一篇關於「如何從 LLM 的最佳搜尋引擎中提取資料」的文章,但我懷疑 5 年後這篇文章仍然具有相關性。
以上是如何使用 Python 抓取 Google 搜尋結果的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















