
在開始實現 Agent 本身之前,我必須熟悉將要使用的環境,並在其之上製作一個自訂包裝器,以便它可以在訓練期間與 Agent 互動。
我使用了 kaggle_environments 函式庫中的西洋棋環境。
from kaggle_environments import make
env = make("chess", debug=True)
我還使用了 Chessnut,這是一個輕量級的 Python 函式庫,可以幫助解析和驗證西洋棋遊戲。
from Chessnut import Game initial_fen = env.state[0]['observation']['board'] game=Game(env.state[0]['observation']['board'])

它提供了一種緊湊的方式來表示棋盤上的所有棋子和當前活躍的玩家。但是,由於我計劃將輸入提供給神經網絡,因此我必須修改狀態的表示。
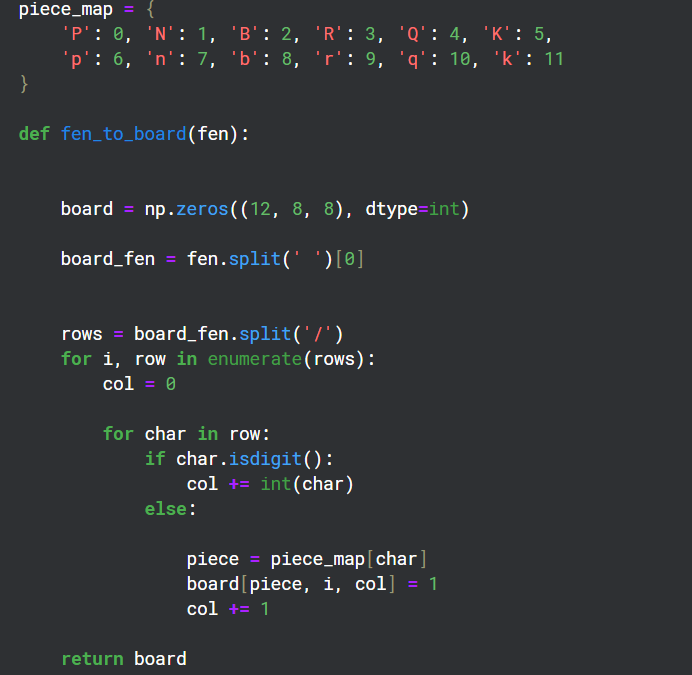
由於棋盤上有 12 種不同類型的棋子,因此我創建了 12 個 8x8 網格通道來表示棋盤上每種類型的狀態。
class EnvCust:
def __init__(self):
self.env = make("chess", debug=True)
self.game=Game(env.state[0]['observation']['board'])
print(self.env.state[0]['observation']['board'])
self.action_space=game.get_moves();
self.obs_space=(self.env.state[0]['observation']['board'])
def get_action(self):
return Game(self.env.state[0]['observation']['board']).get_moves();
def get_obs_space(self):
return fen_to_board(self.env.state[0]['observation']['board'])
def step(self,action):
reward=0
g=Game(self.env.state[0]['observation']['board']);
if(g.board.get_piece(Game.xy2i(action[2:4]))=='q'):
reward=7
elif g.board.get_piece(Game.xy2i(action[2:4]))=='n' or g.board.get_piece(Game.xy2i(action[2:4]))=='b' or g.board.get_piece(Game.xy2i(action[2:4]))=='r':
reward=4
elif g.board.get_piece(Game.xy2i(action[2:4]))=='P':
reward=2
g=Game(self.env.state[0]['observation']['board']);
g.apply_move(action)
done=False
if(g.status==2):
done=True
reward=10
elif g.status == 1:
done = True
reward = -5
self.env.step([action,'None'])
self.action_space=list(self.get_action())
if(self.action_space==[]):
done=True
else:
self.env.step(['None',random.choice(self.action_space)])
g=Game(self.env.state[0]['observation']['board']);
if g.status==2:
reward=-10
done=True
self.action_space=list(self.get_action())
return self.env.state[0]['observation']['board'],reward,done
這個包裝器的目的是為代理提供獎勵策略以及用於在訓練期間與環境交互的步驟函數。
Chessnut 有助於獲取信息,例如當前棋盤狀態下可能的合法走法,以及在遊戲過程中識別將死者。
我嘗試制定獎勵政策,為將死並消滅敵方棋子給予正分,而為輸掉比賽給予負分。
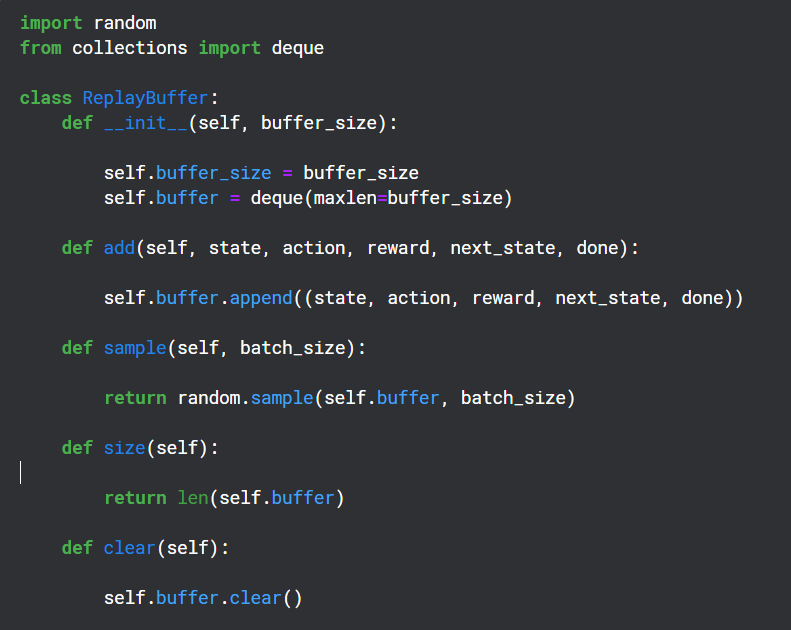
重播緩衝區在訓練期間用於保存 Q 網路輸出的(狀態、動作、獎勵、下一個狀態),並在以後隨機用於目標網路的反向傳播


Chessnut 以 UCI 格式返回合法動作,看起來像“a2a3”,但是為了與神經網路交互,我使用基本模式將每個動作轉換為不同的索引。總共有 64 個方塊,所以我決定為每個動作設定 64*64 個唯一索引。
我知道並非所有 64*64 的棋步都是合法的,但我可以使用 Chessnut 來處理合法性,而且模式足夠簡單。
from kaggle_environments import make
env = make("chess", debug=True)
此神經網路使用卷積層接收 12 個通道輸入,並使用有效的動作索引來過濾獎勵輸出預測。
from Chessnut import Game initial_fen = env.state[0]['observation']['board'] game=Game(env.state[0]['observation']['board'])
這顯然是一個非常基本的模型,實際上不可能表現良好(而且也沒有),但它確實幫助我理解了 DQN 如何更好地工作。

以上是使用 DQN 建立國際象棋代理的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















