

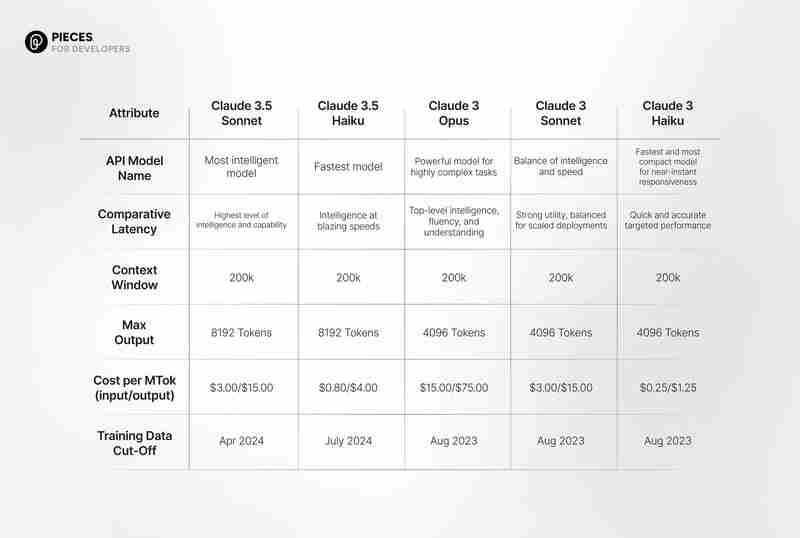
克勞德十四行詩 vs. GPT-4o

在本案例研究中,我將根據這兩種人工智慧模型的效能、定價和具體用例,對這兩種模型進行詳細比較,並從社群回饋、基準測試和個人經驗中汲取見解。
克勞德 3.5 十四行詩:聰明且類人
克勞德是什麼?
Claude 是 Anthropic 開發的人工智慧助手,強調道德和類人互動。它由大型語言模型提供支持,其開發受到前 OpenAI 成員的影響。克勞德的「憲法人工智慧」方法旨在提供更符合人類價值的人工智慧。
克勞德的主要特點:
- Claude 3.5 Sonnet 被認為是 Claude 3.5 家族中最聰明的,擅長邏輯推理和處理創意任務。
- 模型是為總結、研究、寫作和決策等任務而設計的。
- Claude 3.5 可免費使用,但功能有限,但用戶可以升級到付費方案以獲得擴展功能。
使用見解:
Claude 3.5 Sonnet 在需要類人互動和創意解決方案的領域中大放異彩。例如,在個人測試中,它對提示產生了高度創造性和非通用的回應。
但是,它在數學問題解決和複雜推理等專業領域稍微落後,其準確率低於 GPT-4o。

GPT-4o:全能且快速
GPT-4o 是什麼?
GPT-4o 是 OpenAI 的最新人工智慧模型,提供了一種處理各種類型輸入(文字、音訊、圖像和視訊)的通用方法。 GPT-4o 中的“o”代表“omni”,強調其多模式功能。該模型經過訓練可以處理複雜的任務,從高級推理到跨不同領域解決問題。

GPT-4o 的主要特徵:
- GPT-4o 擅長跨不同媒體類型(包括音訊和視訊)提供快速、準確的回應。
- 它支援數學、科學和編碼等領域的複雜問題解決,非常適合需要深度分析思維的任務。
- 可透過 OpenAI 的 ChatGPT 訂閱服務獲取,價格為每月 20 美元,API 訪問價格為每百萬代幣 2.50 美元。
使用見解:
對於複雜任務,GPT-4o 的表現優於許多競爭對手。在基準測試中,GPT-4o 在數學問題解決、推理和速度等領域得分更高。對於需要快速回應和多輸入輸出功能的使用者來說特別有用。
對模型進行基準測試:主要比較
1。研究生程度推理(GPQA、鑽石基準):
GPQA 基準評估人工智慧處理研究生水平推理的能力。
- Claude 3.5 Sonnet:零樣本 CoT 任務的準確率達到 59.4%。
- GPT-4o:零樣本 CoT 任務的準確率達到 53.6%。
結論:Claude 3.5 Sonnet 在研究生程度推理方面表現出色。
2。數學問題解決(數學基準):
在解決複雜的數學問題時,GPT-4o 表現得更好。
- Claude 3.5 Sonnet:零樣本 CoT 準確率 71.1%。
- GPT-4o:零樣本 CoT 準確率 76.6%。
結論:GPT-4o 比較適合數學繁重的任務。
3。延遲與速度:
速度和延遲對於即時應用至關重要。
- GPT-4o:平均延遲比 Claude 3.5 Sonnet 快 24%。
- Claude 3.5 Sonnet:稍慢,第一個 token 的時間較長,輸出 token 較少。
結論:GPT-4o 在速度和反應能力方面領先。
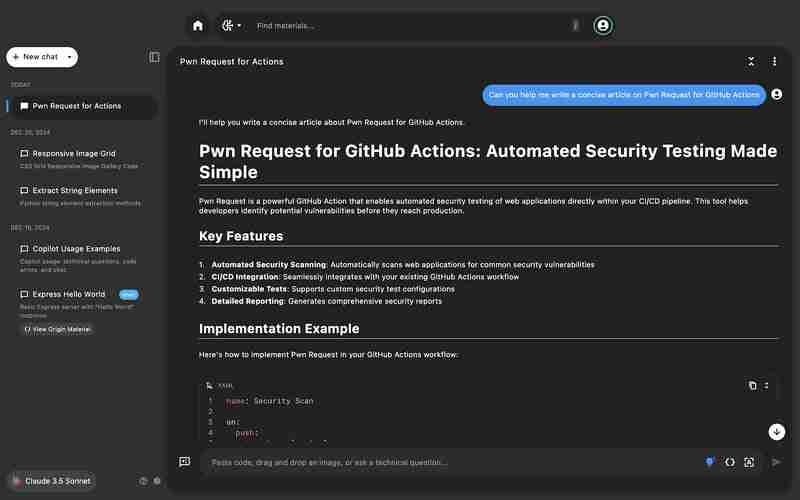
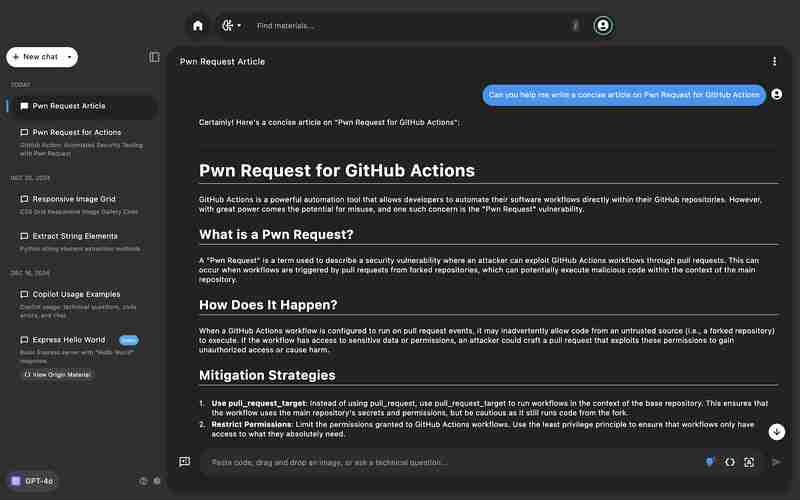
4。上下文理解的準確性:
為了測試上下文準確性,我比較了模型回應有關「Pwn Request for GitHub Actions」提示的能力。
- Claude 3.5 Sonnet:提供了錯誤的回應。
- GPT-4o:正確地將其識別為漏洞。
結論:GPT-4o 在提供上下文相關答案方面更準確。
定價比較
克勞德 3.5 十四行詩:
- 免費版本有使用限制(約 10 個提示)。
- 付費 API 定價:每百萬代幣輸入 3 美元,每百萬代幣輸出 15 美元。
- Claude Pro 方案:每月 18 美元的附加功能。
GPT-4o(透過 OpenAI):
- ChatGPT Plus:完全存取權限每月 20 美元。
- API 定價:每百萬輸入代幣 2.50 美元。
結論:
Claude 在基本使用成本方面提供了更大的靈活性,而 GPT-4o 更適合需要高水準能力和快速輸出的專業人士。
最後的想法:選擇哪一種模型?
選擇 Claude 3.5 Sonnet if:
您需要一個能夠提供創造性和類人響應的人工智慧。它非常適合需要同理心、對話和邏輯解決問題的任務,例如寫作、腦力激盪和總結內容。選 GPT-4o 如果:
您需要高效能 AI 來執行涉及數學、編碼和高階推理的複雜任務。對於處理複雜、多模式任務和即時應用程式的專業人員來說,GPT-4o 更加強大。
在這裡閱讀全文
以上是克勞德十四行詩 vs. GPT-4o的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)




 神秘的JavaScript:它的作用以及為什麼重要
Apr 09, 2025 am 12:07 AM
神秘的JavaScript:它的作用以及為什麼重要
Apr 09, 2025 am 12:07 AM
JavaScript是現代Web開發的基石,它的主要功能包括事件驅動編程、動態內容生成和異步編程。 1)事件驅動編程允許網頁根據用戶操作動態變化。 2)動態內容生成使得頁面內容可以根據條件調整。 3)異步編程確保用戶界面不被阻塞。 JavaScript廣泛應用於網頁交互、單頁面應用和服務器端開發,極大地提升了用戶體驗和跨平台開發的靈活性。
 誰得到更多的Python或JavaScript?
Apr 04, 2025 am 12:09 AM
誰得到更多的Python或JavaScript?
Apr 04, 2025 am 12:09 AM
Python和JavaScript開發者的薪資沒有絕對的高低,具體取決於技能和行業需求。 1.Python在數據科學和機器學習領域可能薪資更高。 2.JavaScript在前端和全棧開發中需求大,薪資也可觀。 3.影響因素包括經驗、地理位置、公司規模和特定技能。
 如何實現視差滾動和元素動畫效果,像資生堂官網那樣?
或者:
怎樣才能像資生堂官網一樣,實現頁面滾動伴隨的動畫效果?
Apr 04, 2025 pm 05:36 PM
如何實現視差滾動和元素動畫效果,像資生堂官網那樣?
或者:
怎樣才能像資生堂官網一樣,實現頁面滾動伴隨的動畫效果?
Apr 04, 2025 pm 05:36 PM
實現視差滾動和元素動畫效果的探討本文將探討如何實現類似資生堂官網(https://www.shiseido.co.jp/sb/wonderland/)中�...
 JavaScript難以學習嗎?
Apr 03, 2025 am 12:20 AM
JavaScript難以學習嗎?
Apr 03, 2025 am 12:20 AM
學習JavaScript不難,但有挑戰。 1)理解基礎概念如變量、數據類型、函數等。 2)掌握異步編程,通過事件循環實現。 3)使用DOM操作和Promise處理異步請求。 4)避免常見錯誤,使用調試技巧。 5)優化性能,遵循最佳實踐。
 JavaScript的演變:當前的趨勢和未來前景
Apr 10, 2025 am 09:33 AM
JavaScript的演變:當前的趨勢和未來前景
Apr 10, 2025 am 09:33 AM
JavaScript的最新趨勢包括TypeScript的崛起、現代框架和庫的流行以及WebAssembly的應用。未來前景涵蓋更強大的類型系統、服務器端JavaScript的發展、人工智能和機器學習的擴展以及物聯網和邊緣計算的潛力。
 如何使用JavaScript將具有相同ID的數組元素合併到一個對像中?
Apr 04, 2025 pm 05:09 PM
如何使用JavaScript將具有相同ID的數組元素合併到一個對像中?
Apr 04, 2025 pm 05:09 PM
如何在JavaScript中將具有相同ID的數組元素合併到一個對像中?在處理數據時,我們常常會遇到需要將具有相同ID�...
 前端開發中如何實現類似 VSCode 的面板拖拽調整功能?
Apr 04, 2025 pm 02:06 PM
前端開發中如何實現類似 VSCode 的面板拖拽調整功能?
Apr 04, 2025 pm 02:06 PM
探索前端中類似VSCode的面板拖拽調整功能的實現在前端開發中,如何實現類似於VSCode...
