
本教學示範使用 LLMOps 最佳實務建構可用於生產的 AI 拉取請求審核器。 最終應用程式可在此處訪問,接受公共 PR URL 並返回人工智慧生成的評論。
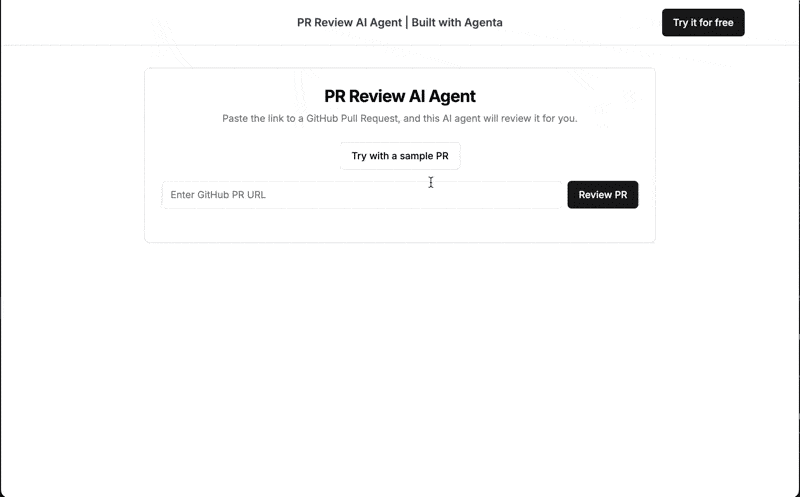
應用概述
本教學涵蓋:
核心邏輯
AI 助理的工作流程很簡單:給定 PR URL,它從 GitHub 檢索差異並將其提交給 LLM 進行審核。
GitHub 差異可透過以下方式存取:
<code>https://patch-diff.githubusercontent.com/raw/{owner}/{repo}/pull/{pr_number}.diff</code>這個 Python 函數取得差異:
def get_pr_diff(pr_url):
# ... (Code remains the same)
return response.textLiteLLM 促進了 LLM 交互,在不同提供者之間提供一致的介面。
prompt_system = """
You are an expert Python developer performing a file-by-file review of a pull request. You have access to the full diff of the file to understand the overall context and structure. However, focus on reviewing only the specific hunk provided.
"""
prompt_user = """
Here is the diff for the file:
{diff}
Please provide a critique of the changes made in this file.
"""
def generate_critique(pr_url: str):
diff = get_pr_diff(pr_url)
response = litellm.completion(
model=config.model,
messages=[
{"content": config.system_prompt, "role": "system"},
{"content": config.user_prompt.format(diff=diff), "role": "user"},
],
)
return response.choices[0].message.content使用 Agenta 實現可觀察性
Agenta 增強了可觀察性,追蹤輸入、輸出和資料流,以便於偵錯。
初始化 Agenta 並配置 LiteLLM 回呼:
import agenta as ag ag.init() litellm.callbacks = [ag.callbacks.litellm_handler()]
帶有 Agenta 裝飾器的儀器函數:
@ag.instrument()
def generate_critique(pr_url: str):
# ... (Code remains the same)
return response.choices[0].message.content設定AGENTA_API_KEY環境變數(從Agenta取得)和可選的AGENTA_HOST用於自架。

創建法學碩士遊樂場
Agenta 的自訂工作流程功能為迭代開發提供了類似 IDE 的遊樂場。 以下程式碼片段演示了與 Agenta 的配置和整合:
from pydantic import BaseModel, Field
from typing import Annotated
import agenta as ag
import litellm
from agenta.sdk.assets import supported_llm_models
# ... (previous code)
class Config(BaseModel):
system_prompt: str = prompt_system
user_prompt: str = prompt_user
model: Annotated[str, ag.MultipleChoice(choices=supported_llm_models)] = Field(default="gpt-3.5-turbo")
@ag.route("/", config_schema=Config)
@ag.instrument()
def generate_critique(pr_url:str):
diff = get_pr_diff(pr_url)
config = ag.ConfigManager.get_from_route(schema=Config)
response = litellm.completion(
model=config.model,
messages=[
{"content": config.system_prompt, "role": "system"},
{"content": config.user_prompt.format(diff=diff), "role": "user"},
],
)
return response.choices[0].message.content使用 Agenta 進行服務和評估
agenta init 並指定應用程式名稱和 API 金鑰。 agenta variant serve app.py。 這使得應用程式可以透過 Agenta 的遊樂場進行存取以進行端到端測試。 LLM-as-a-judge用於評估。 評估者提示為:
<code>You are an evaluator grading the quality of a PR review. CRITERIA: ... (criteria remain the same) ANSWER ONLY THE SCORE. DO NOT USE MARKDOWN. DO NOT PROVIDE ANYTHING OTHER THAN THE NUMBER</code>
評估器的使用者提示:
<code>https://patch-diff.githubusercontent.com/raw/{owner}/{repo}/pull/{pr_number}.diff</code>
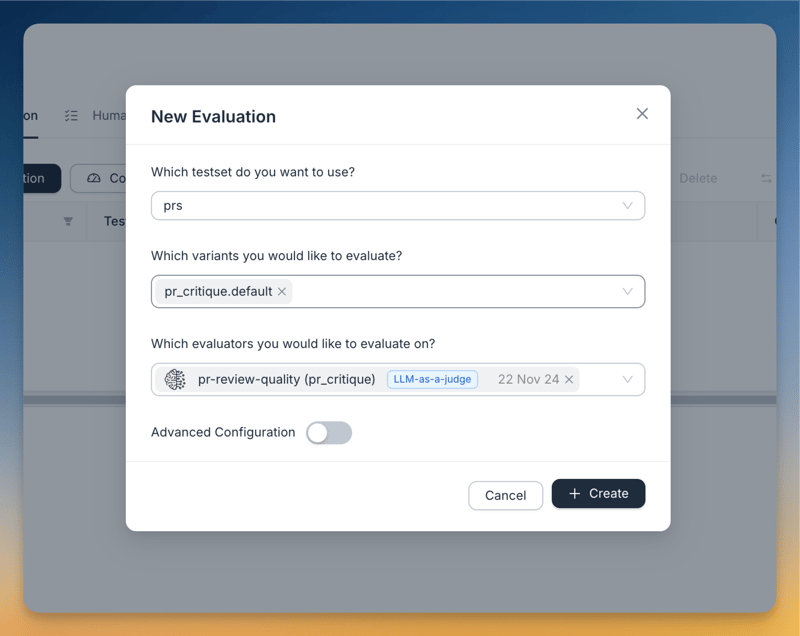
部署與前端
部署是透過 Agenta 的 UI 完成的:

v0.dev 前端用於快速 UI 建立。
後續步驟與結論
未來的改進包括及時細化、合併完整的程式碼上下文以及處理大的差異。 本教學成功示範了使用 Agenta 和 LiteLLM 建置、評估和部署生產就緒的 AI 拉取請求審閱器。

以上是使用 vev、litellm 和 Agenta 建立 AI 程式碼審查助手的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















