

在基於Ampere Altra的實例上運行時的10個關鍵問題

Ampere 系統性能分析:十個關鍵問題及解答

(本文最初由 Ampere Computing 發布)
您的應用程序運行在新的雲實例或服務器(或 SUT,被測系統)上,您發現存在性能問題,或者您希望確保在可用的系統資源前提下獲得最佳性能。本文討論了一些您應該提出的基本問題以及解答這些問題的方法。
前提條件:了解您的虛擬機或服務器
在開始故障排除或進行性能分析練習之前,您需要了解可用的系統資源。系統級性能通常歸結為四個組件及其相互作用方式——CPU、內存、網絡、磁盤。另請參閱 Brendan Gregg 的優秀文章《Linux 性能分析:60000 毫秒速成指南》,這篇文章是快速評估性能問題的絕佳起點。
本文解釋瞭如何更深入地了解性能問題。
確定 CPU 類型
運行 $lscpu 命令,它將顯示 CPU 類型、CPU 頻率、核心數量和其他 CPU 相關信息:
<code>ampere@colo1:~$ lscpu
Architecture: aarch64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 160
On-line CPU(s) list: 0-159
Thread(s) per core: 1
Core(s) per socket: 80
Socket(s): 2
NUMA node(s): 2
Vendor ID: ARM
Model: 1
Model name: Neoverse-N1
Stepping: r3p1
CPU max MHz: 3000.0000
CPU min MHz: 1000.0000
BogoMIPS: 50.00
L1d cache: 10 MiB
L1i cache: 10 MiB
L2 cache: 160 MiB
NUMA node0 CPU(s): 0-79
NUMA node1 CPU(s): 80-159
Vulnerability Itlb multibit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; __user pointer sanitization
Vulnerability Spectre v2: Mitigation; CSV2, BHB
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid
asimdrdm lrcpc dcpop asimddp ssbs </code>確定內存配置
運行 $free 命令,它將提供有關物理內存和交換內存總量的信息(包括內存利用率的細分)。運行 Multichase 基準測試以確定實例/SUT 的延遲、內存帶寬和負載延遲:
<code>ampere@colo1:~$ free
total used free shared buff/cache available
Mem: 130256992 3422844 120742736 4208 6091412 125852984
Swap: 8388604 0 8388604
</code>評估網絡能力
運行 $ethtool 命令,它將提供有關 NIC 卡硬件設置的信息。它還用於控製網絡設備驅動程序和硬件設置。如果您正在客戶端-服務器模型中運行工作負載,則最好了解客戶端和服務器之間的帶寬和延遲。為了確定帶寬,簡單的 iperf3 測試就足夠了,而對於延遲,簡單的 ping 測試就能提供該值。在客戶端-服務器設置中,還建議將網絡跳數保持在最低限度。 traceroute 是一個網絡診斷命令,用於顯示路由並測量數據包跨網絡的傳輸延遲:
<code>ampere@colo1:~$ ethtool -i enp1s0np0 driver: mlx5_core version: 5.7-1.0.2 firmware-version: 16.32.1010 (RCP0000000001) expansion-rom-version: bus-info: 0000:01:00.0 supports-statistics: yes supports-test: yes supports-eeprom-access: no supports-register-dump: no supports-priv-flags: yes> </code>
了解存儲基礎架構
在開始運行工作負載之前,了解磁盤功能至關重要。了解磁盤和文件系統的吞吐量和延遲將有助於您有效地規劃和設計工作負載。靈活 I/O(或“fio”)是確定這些值的理想工具。
現在進入十大問題
1. 我的 CPU 使用情況良好嗎?
總擁有成本的主要組成部分之一是 CPU。因此,值得了解 CPU 的使用效率。空閒的 CPU 通常意味著存在外部依賴項,例如等待磁盤或網絡訪問。始終建議監控 CPU 利用率並檢查核心使用情況是否均勻。
下圖顯示了 $top -1 命令的一個示例輸出。

2. 我的 CPU 是否以可能的最高頻率運行?
現代 CPU 使用 p 狀態來調整其運行的頻率和電壓,以便在不需要更高頻率時降低 CPU 的功耗。這稱為動態電壓和頻率縮放 (DVFS),由操作系統管理。在 Linux 中,p 狀態由 CPUFreq 子系統管理,該子系統使用不同的算法(稱為調控器)來確定 CPU 的運行頻率。通常,對於對性能敏感的應用程序,最好確保使用性能調控器,以下命令使用 cpupower 實用程序來實現這一點。請記住,CPU 應運行的頻率利用率取決於工作負載:
<code>ampere@colo1:~$ lscpu
Architecture: aarch64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 160
On-line CPU(s) list: 0-159
Thread(s) per core: 1
Core(s) per socket: 80
Socket(s): 2
NUMA node(s): 2
Vendor ID: ARM
Model: 1
Model name: Neoverse-N1
Stepping: r3p1
CPU max MHz: 3000.0000
CPU min MHz: 1000.0000
BogoMIPS: 50.00
L1d cache: 10 MiB
L1i cache: 10 MiB
L2 cache: 160 MiB
NUMA node0 CPU(s): 0-79
NUMA node1 CPU(s): 80-159
Vulnerability Itlb multibit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; __user pointer sanitization
Vulnerability Spectre v2: Mitigation; CSV2, BHB
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid
asimdrdm lrcpc dcpop asimddp ssbs </code>要檢查運行應用程序時 CPU 的頻率,請運行以下命令:
<code>ampere@colo1:~$ free
total used free shared buff/cache available
Mem: 130256992 3422844 120742736 4208 6091412 125852984
Swap: 8388604 0 8388604
</code>3. 我在應用程序中花費的時間與內核時間相比如何?
有時需要找出 CPU 時間的百分比是在用戶空間消耗的還是在特權時間(即內核空間)消耗的。對於某些類別的工作負載(例如網絡綁定工作負載),較高的內核時間可能是合理的,但也可能表明存在問題。
Linux 應用程序 top 可用於找出用戶與內核時間的消耗情況,如下所示。
-
mpstat——檢查每個 CPU 的統計信息,並檢查各個熱點/繁忙的 CPU。這是一個多處理器統計工具,可以報告每個 CPU 的統計信息(-P 選項)
- CPU:邏輯 CPU ID,或所有 CPU 的匯總信息
- %usr:用戶時間,不包括 %nice
- %nice:具有優先級較低的進程的用戶時間
- %sys:系統時間
- %iowait:IO 等待
- %irq:硬件中斷 CPU 使用率
- %soft:軟件中斷 CPU 使用率
- %steal:用於服務其他租戶的時間
- %guest:在客戶虛擬機中花費的 CPU 時間
- %gnice:運行優先級較低的客戶機的 CPU 時間
- %idle:空閒時間

要識別每個 CPU 的 CPU 使用情況並顯示用戶時間/內核時間的比率,%usr、%sys 和 %idle 是關鍵值。這些關鍵值還可以幫助識別可能由單線程應用程序或中斷映射引起的“熱點”CPU。
4. 我的應用程序有足夠的內存嗎?
當您管理服務器時,您可能必須安裝新的應用程序,或者您可能注意到應用程序已開始變慢。為了管理系統資源並了解系統已安裝的系統內存和系統內存利用率,$free 命令是一個有價值的工具。 $vmstat 也是監控內存利用率的有價值的工具,如果您正在主動將內存與虛擬內存交換,則尤其如此。
-
free。 Linuxfree命令顯示內存和交換統計信息。輸出顯示系統的總內存、已用內存和可用內存。一個重要的列是可用值,它顯示應用程序可用的內存,需要交換。它還考慮了無法立即回收的內存。
-
vmstat。此命令提供系統內存、運行狀況的高級視圖,包括當前可用內存和分頁統計信息。$vmstat命令顯示正在交換的活動內存(分頁)。


這些命令打印當前狀態的摘要。列默認為千字節,分別是:
- Swpd:交換出的內存量
- Free:可用內存
- Buff:緩衝區緩存中的內存
- Cache:頁面緩存中的內存
- Si:交換進來的內存(分頁)
- So:交換出去的內存(分頁)
如果 si 和 so 非零,則係統處於內存壓力下,並且正在將內存交換到交換設備。
5. 我是否獲得了足夠的內存帶寬?
要了解足夠的內存帶寬,首先獲取系統的“最大內存帶寬”值。 “最大內存帶寬”值可以通過以下方式找到:
- 基本 DRAM 時鐘頻率
- 每個時鐘的數據傳輸次數:如果使用“雙倍數據速率”(DDR*)內存,則為兩次
- 內存總線(接口)寬度:例如,DDR 3 的寬度為 64 位(也稱為行)
- 接口數量:現代個人電腦通常使用兩個內存接口(雙通道模式)來實現有效的 128 位總線寬度
- 最大內存帶寬 = 基本 DRAM 時鐘頻率 * 每個時鐘的數據傳輸次數 * 內存基準寬度 * 接口數量
此值表示系統的理論最大帶寬,也稱為“突發速率”。您現在可以對系統運行 Multichase 或帶寬基準測試並驗證這些值。
注意:已經發現突發速率可能無法維持,並且實現的值可能略小於計算值。
6. 我的工作負載是否以平衡的方式使用所有 CPU?
在服務器上運行工作負載時,作為性能調整或故障排除的一部分,您可能想知道特定進程當前在哪個 CPU 核心上調度,以及在該 CPU 核心上運行的進程的資源利用情況。第一步是找到在 CPU 核心上運行的進程。這可以使用 htop 來完成。 CPU 值不會反映在 htop 的默認顯示中。要獲取 CPU 核心值,請從命令行啟動 $htop,按 F2 鍵,轉到“列”,然後在“可用列”下添加“處理器”。每個進程當前使用的“CPU ID”將出現在“CPU”列下。
-
如何配置
$htop以顯示 CPU/核心: -
顯示核心 4-6 達到最大值的
$htop命令(htop 核心計數從“1”而不是“0”開始): -
用於檢查統計信息的選定核心的
$mpstat命令:



一旦您確定了 CPU 核心,就可以運行 $mpstat 命令來檢查每個 CPU 的統計信息並檢查各個熱點/繁忙的 CPU。這是一個多處理器統計工具,可以報告每個 CPU(或核心)的統計信息。有關 $mpstat 的更多信息,請參見上面的“我在應用程序中花費的時間與內核時間相比如何?”部分。
7. 我的網絡是我的應用程序的瓶頸嗎?
即使在您飽和服務器上的其他資源之前,也可能發生網絡瓶頸。當在客戶端-服務器模型中運行工作負載時,就會發現此問題。您需要做的第一件事是確定您的網絡外觀。客戶端和服務器之間的延遲和帶寬尤其重要。像 iperf3、ping 和 traceroute 這樣的工具是簡單的工具,可以幫助您確定網絡的限制。一旦確定了網絡的限制,像 $dstat 和 $nicstat 這樣的工具就可以幫助您監控網絡利用率並確定由於網絡而導致的任何系統瓶頸。
-
dstat。此命令用於監控系統資源,包括 CPU 統計信息、磁盤統計信息、網絡統計信息、分頁統計信息和系統統計信息。要監控網絡利用率,請使用 -n 選項。該命令將提供系統接收和發送的數據包的吞吐量。
-
nicstat。此命令打印網絡接口統計信息,包括吞吐量和利用率。


列包括:
- Int:接口名稱
- %util:最大利用率
- Sat:反映接口飽和統計信息的數值
- 值前綴“r”= 讀取/接收
- 值前綴“w”= 寫入/傳輸
- 1- KB/s:每秒千字節
- 2- Pk/s:每秒數據包
- 3- Avs/s:平均數據包大小(字節)
8. 我的磁盤是瓶頸嗎?
與網絡一樣,磁盤也可能是應用程序性能低下的原因。在衡量磁盤性能時,我們會查看以下指標:
- 利用率
- 飽和度
- IOPS(每秒輸入/輸出)
- 吞吐量
- 響應時間
一個好的規則是,當您為應用程序選擇服務器/實例時,必須首先對磁盤的I/O 性能進行基準測試,以便您可以獲得磁盤性能的峰值或“上限”,並且能夠確定磁盤性能是否滿足應用程序的需求。靈活 I/O 是確定這些值的理想工具。
應用程序運行後,您可以使用 $iostat 和 $dstat 實時監控磁盤資源利用率。
iostat 命令顯示每個磁盤的 I/O 統計信息,提供用於工作負載表徵、利用率和飽和度的指標。

第一行輸出顯示系統的摘要,包括內核版本、主機名、數據架構和 CPU 計數。第二行顯示自啟動以來系統的 CPU 摘要。
對於後續行中顯示的每個磁盤設備,它在列中顯示基本詳細信息:
- Tps:每秒事務數
- kB_read/s:每秒讀取的千字節數
- kB_wrtn/s:每秒寫入的千字節數
- kB_read:讀取的千字節總數
- KB_write:寫入的千字節總數
dstat 命令用於監控系統資源,包括 CPU 統計信息、磁盤統計信息、網絡統計信息、分頁統計信息和系統統計信息。要監控磁盤利用率,請使用 -d 選項。該選項將顯示磁盤上讀取 (read) 和寫入 (writ) 操作的總數。
下圖演示了寫入密集型工作負載。

9. 我是否在為 NUMA 性能損失付費?
非一致性內存訪問 (NUMA) 是一種用於多處理的計算機內存設計,其中內存訪問時間取決於相對於處理器的內存位置。在 NUMA 下,處理器可以比非本地內存(另一個處理器的本地內存或處理器之間共享的內存)更快地訪問其自己的本地內存。 NUMA 的好處僅限於工作負載,尤其是在服務器上,數據通常與某些任務或用戶緊密相關。
在 NUMA 系統上,處理器與其內存庫之間的距離越大,處理器訪問該內存庫的速度就越慢。對於對性能敏感的應用程序,系統操作系統應從最接近的內存庫分配內存。要實時監控系統或進程的內存分配,$numastat 是一個很好的工具。
numastat 命令提供非一致性內存訪問 (NUMA) 系統的統計信息。這些系統通常是具有多個 CPU 插槽的系統。

Linux 操作系統嘗試在最近的 NUMA 節點上分配內存,$numastat 顯示內存分配的當前統計信息。
- Numa_hit:在預期的 NUMA 節點上分配內存
- Numa_miss:顯示應該在其他地方的本地分配
- Numa_foreign:顯示應該在本地分配的遠程分配
- Other_node:在該節點上分配內存,而進程在其他地方運行
Numa_miss 和 Numa_foreign 都顯示不在首選 NUMA 節點上的內存分配。理想情況下,numa_miss 和 numa_foreign 的值應保持在最小值,因為較高的值會導致較差的內存 I/O 性能。
$numastat -p <process></process> 命令也可用於查看進程的 NUMA 分佈。
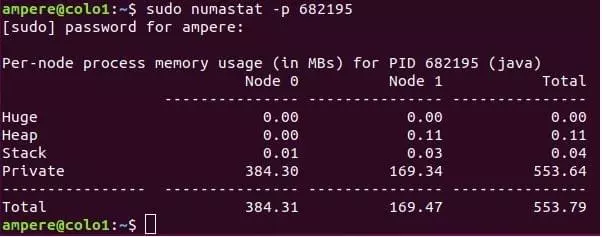
10. 運行應用程序時,我的 CPU 正在做什麼?
在系統/實例上運行應用程序時,您將有興趣了解應用程序正在做什麼以及應用程序在 CPU 上使用的資源。 $pidstat 是一個命令行工具,可以監控系統上運行的每個單獨進程。
pidstat 將把主要的 CPU 使用者分解為用戶時間和系統時間。
此 Linux 工具按進程或線程細分 CPU 使用情況,包括用戶時間和系統時間。此命令還可以報告進程的 IO 統計信息(-d 選項)。

- UID:正在監控的任務的真實用戶標識號
- PID:正在監控的任務的標識號
- %usr:任務在用戶級別(應用程序)執行時使用的 CPU 百分比,不帶優先級。
- %system:任務在系統級別(內核)執行時使用的 CPU 百分比
- %wait:任務等待運行時使用的 CPU 百分比
- %CPU:任務使用的 CPU 時間的總百分比。
- CPU:任務附加到的處理器/核心編號
$pidstat -p 也可以運行以收集有關特定進程的數據。

請與我們的專家銷售團隊聯繫,了解合作夥伴關係或通過我們的開發者訪問計劃了解如何訪問 Ampere 系統。
以上是在基於Ampere Altra的實例上運行時的10個關鍵問題的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 CNCF ARM64飛行員:影響和見解
Apr 15, 2025 am 08:27 AM
CNCF ARM64飛行員:影響和見解
Apr 15, 2025 am 08:27 AM
該試點程序是CNCF(雲本機計算基礎),安培計算,Equinix金屬和驅動的合作,簡化了CNCF GitHub項目的ARM64 CI/CD。 該計劃解決了安全問題和績效
 使用AWS ECS和LAMBDA的無服務器圖像處理管道
Apr 18, 2025 am 08:28 AM
使用AWS ECS和LAMBDA的無服務器圖像處理管道
Apr 18, 2025 am 08:28 AM
該教程通過使用AWS服務來指導您通過構建無服務器圖像處理管道。 我們將創建一個部署在ECS Fargate群集上的next.js前端,與API網關,Lambda函數,S3桶和DynamoDB進行交互。 Th
 21個開發人員新聞通訊將在2025年訂閱
Apr 24, 2025 am 08:28 AM
21個開發人員新聞通訊將在2025年訂閱
Apr 24, 2025 am 08:28 AM
與這些頂級開發人員新聞通訊有關最新技術趨勢的了解! 這個精選的清單為每個人提供了一些東西,從AI愛好者到經驗豐富的後端和前端開發人員。 選擇您的收藏夾並節省時間搜索REL
