

2024年編碼的LLM:價格,性能和爭取最佳的戰鬥

用於編碼的大語言模型(LLM)的快速發展的景觀
提供了豐富的選擇的開發人員。 該分析比較了可以通過公共API訪問的頂級LLM,重點是通過HumaneVal和Real-Word Elo Scores等基準測量的編碼實力。 無論您是構建個人項目還是將AI集成到工作流程中,了解這些模型的優勢和劣勢對於明智的決策至關重要。
> LLM比較的挑戰> 由於頻繁的模型更新(即使是次要的表現),LLMS的固有隨機性導致結果不一致以及基准設計和報告的潛在偏見,因此很難進行直接比較。 該分析代表了基於當前可用數據的最佳及時比較。
>
評估指標:HumaneVal和Elo分數:
- HumaneVal:
-
ELO分數(Chatbot Arena-僅編碼):
來自人類所判斷的頭對頭LLM比較。 較高的ELO分數表明相對性能出色。 100分的差異表明高評分模型的獲勝率約為64%。 - 性能概述:
OpenAI的模型始終在人道主義和ELO排名中均始終如一,展示了出色的編碼功能。 o1-mini模型令人驚訝地超過了兩個指標中較大的
o1模型。 其他公司的最佳模型表現出可比的性能,儘管落後於Openai。

>基準與現實世界的性能差異:

Mistral大型,在人類事件上的表現要比現實世界中的使用情況更好(潛在的過度擬合),而其他模型(例如Google的 平衡性能和價格: > Pareto Front(最佳性能和價格平衡)主要具有OpenAI(高性能)和Google(貨幣價值)模型。 META的開源美洲駝模型,基於雲提供商平均價格,也顯示出競爭價值。 其他洞察力:
編碼LLM景觀是動態的。 開發人員應定期評估最新模型,考慮性能和成本。 了解基準的局限性和優先考慮多樣化的評估指標對於做出明智的選擇至關重要。 該分析提供了當前狀態的快照,並且連續監測對於在這個快速發展的領域保持領先地位至關重要。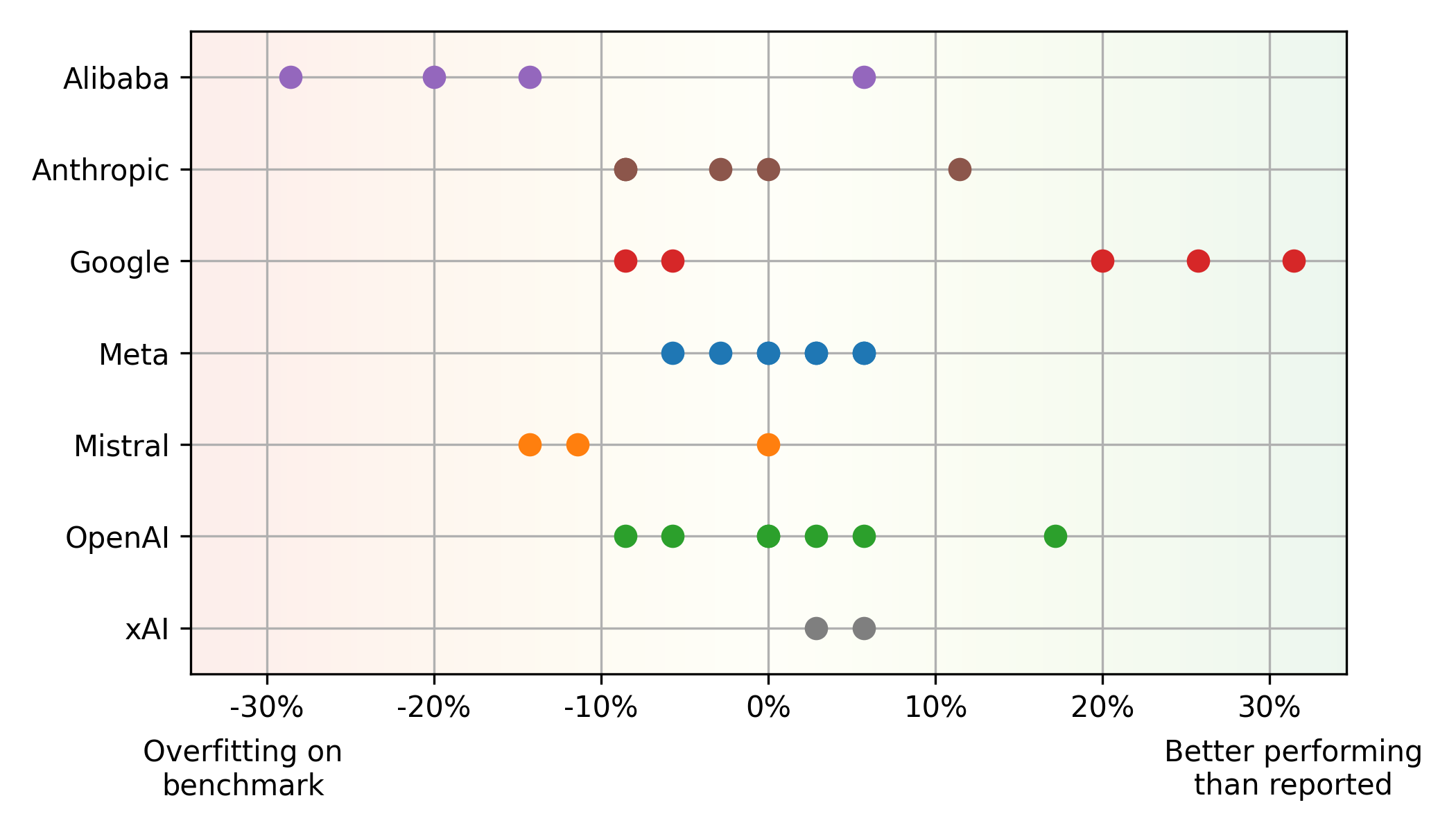




 LLM始終提高性能和成本降低。儘管開源模型正在趕上,但專有模型仍保持優勢。 即使是較小的更新也會顯著影響性能和/或定價。
LLM始終提高性能和成本降低。儘管開源模型正在趕上,但專有模型仍保持優勢。 即使是較小的更新也會顯著影響性能和/或定價。
以上是2024年編碼的LLM:價格,性能和爭取最佳的戰鬥的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 如何使用AGNO框架構建多模式AI代理?
Apr 23, 2025 am 11:30 AM
如何使用AGNO框架構建多模式AI代理?
Apr 23, 2025 am 11:30 AM
在從事代理AI時,開發人員經常發現自己在速度,靈活性和資源效率之間進行權衡。我一直在探索代理AI框架,並遇到了Agno(以前是Phi-
 如何在SQL中添加列? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
如何在SQL中添加列? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
SQL的Alter表語句:動態地將列添加到數據庫 在數據管理中,SQL的適應性至關重要。 需要即時調整數據庫結構嗎? Alter表語句是您的解決方案。本指南的詳細信息添加了Colu
 OpenAI以GPT-4.1的重點轉移,將編碼和成本效率優先考慮
Apr 16, 2025 am 11:37 AM
OpenAI以GPT-4.1的重點轉移,將編碼和成本效率優先考慮
Apr 16, 2025 am 11:37 AM
該版本包括三種不同的型號,GPT-4.1,GPT-4.1 MINI和GPT-4.1 NANO,標誌著向大語言模型景觀內的特定任務優化邁進。這些模型並未立即替換諸如
 Andrew Ng的新簡短課程
Apr 15, 2025 am 11:32 AM
Andrew Ng的新簡短課程
Apr 15, 2025 am 11:32 AM
解鎖嵌入模型的力量:深入研究安德魯·NG的新課程 想像一個未來,機器可以完全準確地理解和回答您的問題。 這不是科幻小說;多虧了AI的進步,它已成為R
 火箭發射模擬和分析使用Rocketpy -Analytics Vidhya
Apr 19, 2025 am 11:12 AM
火箭發射模擬和分析使用Rocketpy -Analytics Vidhya
Apr 19, 2025 am 11:12 AM
模擬火箭發射的火箭發射:綜合指南 本文指導您使用強大的Python庫Rocketpy模擬高功率火箭發射。 我們將介紹從定義火箭組件到分析模擬的所有內容
 Google揭示了下一個2025年雲上最全面的代理策略
Apr 15, 2025 am 11:14 AM
Google揭示了下一個2025年雲上最全面的代理策略
Apr 15, 2025 am 11:14 AM
雙子座是Google AI策略的基礎 雙子座是Google AI代理策略的基石,它利用其先進的多模式功能來處理和生成跨文本,圖像,音頻,視頻和代碼的響應。由DeepM開發
 您可以自己3D打印的開源人形機器人:擁抱面孔購買花粉機器人技術
Apr 15, 2025 am 11:25 AM
您可以自己3D打印的開源人形機器人:擁抱面孔購買花粉機器人技術
Apr 15, 2025 am 11:25 AM
“超級樂於宣布,我們正在購買花粉機器人,以將開源機器人帶到世界上,” Hugging Face在X上說:“自從Remi Cadene從Tesla加入我們以來,我們已成為開放機器人的最廣泛使用的軟件平台。
 DeepCoder-14b:O3-Mini和O1的開源競賽
Apr 26, 2025 am 09:07 AM
DeepCoder-14b:O3-Mini和O1的開源競賽
Apr 26, 2025 am 09:07 AM
在AI社區的重大發展中,Agentica和AI共同發布了一個名為DeepCoder-14B的開源AI編碼模型。與OpenAI等封閉源競爭對手提供代碼生成功能
