
>本文深入研究大型語言模型(LLMS)的實際方面,重點介紹了Codex和Constractgpt作為主要示例。 這是探索GPT模型的系列中的第三個,基於先前關於預訓練和縮放的討論。
。
>微調至關重要,因為雖然預訓練的LLM是用途廣泛,但它們通常不屬於針對特定任務的專業模型。 此外,即使像GPT-3這樣的強大模型也可能在復雜的說明中掙扎,並保持安全和道德標準。 這需要進行微調策略。
>本文重點介紹了兩個關鍵的微調挑戰:適應新的模式(例如Codex對代碼生成的改編),並將模型與人類偏好相結合(如《指南》所示)。 兩者都需要仔細考慮數據收集,模型體系結構,目標功能和評估指標。
>codex:代碼生成的微調
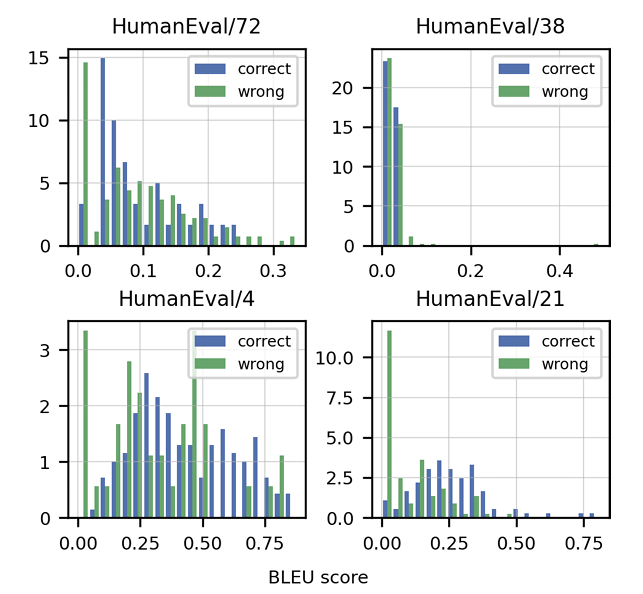
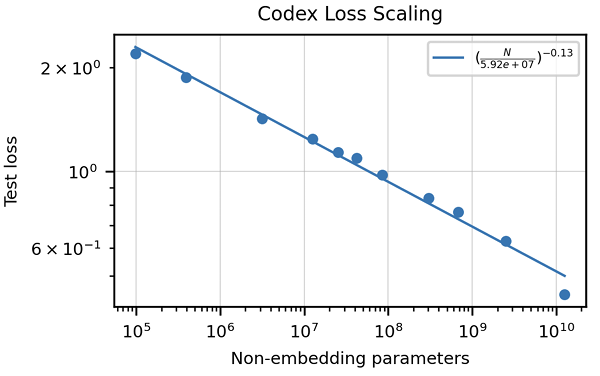
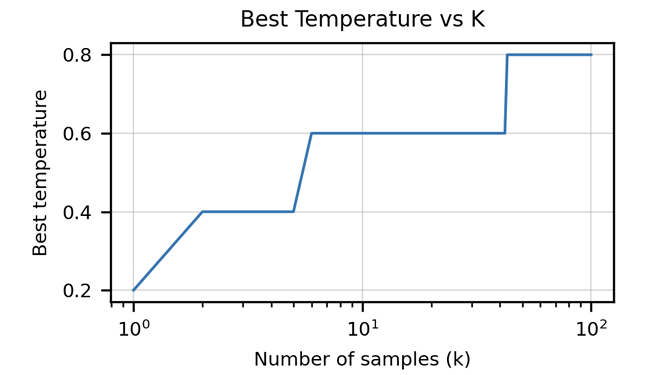
>>該文章強調了傳統指標(例如BLEU得分)的不足來評估代碼生成。 它引入了“功能正確性”和pass@k 公制,提供了更強大的評估方法。 還突出顯示了由單位測試組成手寫編程問題的人道數據集的創建。 討論了特定代碼的數據清潔策略,以及適應代幣器以處理編程語言的獨特特徵(例如Whitespace編碼)的重要性。 本文介紹了與HOMANEVAL的GPT-3相比,Codex表現出色的結果,並探討了模型大小和溫度對性能的影響。


> consendgpt and chatgpt:與人類偏好對齊>
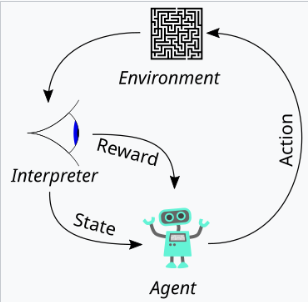
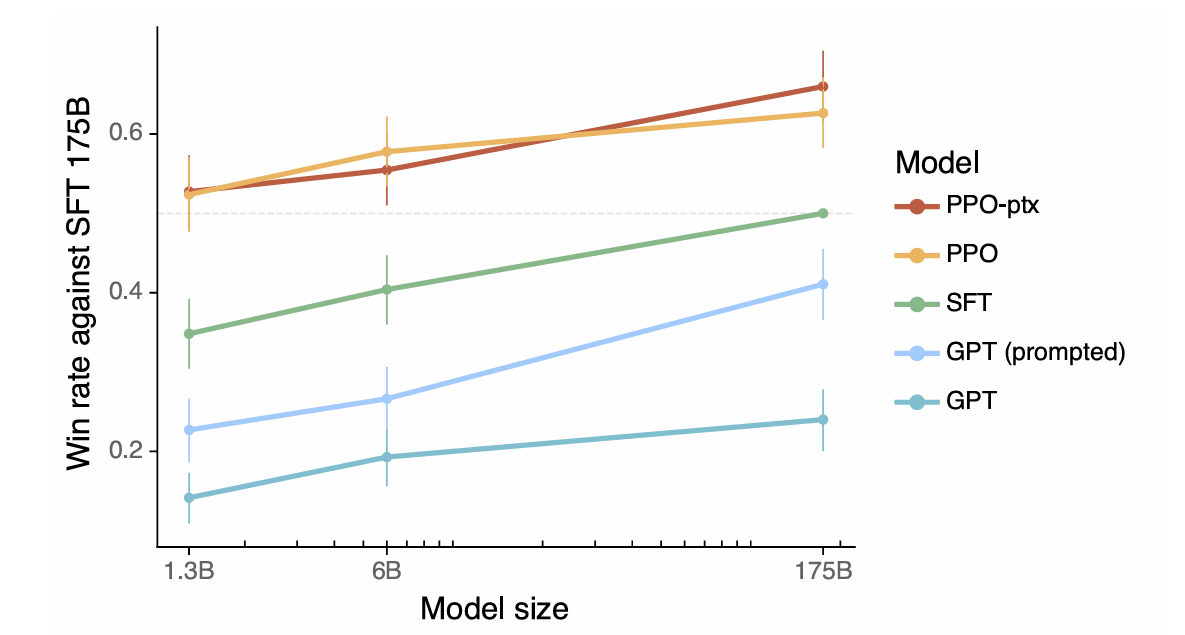
>本文將一致性定義為表現出樂於助人,誠實和無害性的模型。 它解釋瞭如何將這些品質轉化為可測量的方面,例如以下教學,幻覺率和偏見/毒性。 從人類反饋(RLHF)中使用強化學習的使用是詳細的,概述了這三個階段:收集人類反饋,培訓獎勵模型,並使用近端政策優化(PPO)優化政策。 文章強調了數據質量控制在人類反饋收集過程中的重要性。 結果展示了指令示威的改進對齊,減少幻覺和緩解性能回歸的措施。
>

摘要和最佳實踐
>>通過總結微調LLM的關鍵注意事項,包括定義所需的行為,評估績效,收集和清潔數據,調整模型體系結構以及減輕潛在的負面後果。 它鼓勵仔細考慮超參數調整,並強調微調過程的迭代性質。
以上是了解chatgpt的演變:第3部分 - Codex和Consendgpt的見解的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















