
>在此博客中,我們將構建一個多語言代碼說明應用程序,以展示Llama 3.3的功能,尤其是其在推理,按照說明,編碼和多語言支持方面的優勢。
>此應用程序將允許用戶:
llama 3.3從擁抱臉上進行處理。
設置Llama 3.3
>在擁抱臉上訪問駱駝3.3>
>訪問美洲駝3.3的一種方法是通過擁抱面孔,這是託管機器學習模型最受歡迎的平台之一。要通過擁抱Face的推理API使用Llama 3.3,您將需要:
>現在已經準備好了,讓我們安裝必要的庫。確保您正在運行Python 3.8。在終端中,運行以下命令以安裝簡化,請求和擁抱面部庫:
mkdir multilingual-code-explanation cd multilingual-code-explanation
到現在,您應該有:
寫後端
>導入所需庫
設置API Access
mkdir multilingual-code-explanation cd multilingual-code-explanation
api端點(託管模型的URL)。
>python3 -m venv venv source venv/bin/activate’
>用您之前生成的令牌替換“ hf_your_api_key_here”。
>構建一個提示,告訴模型該怎麼做。
pip install streamlit requests transformers huggingface-hub
接下來,定義了有效載荷。對於輸入,我們指定提示發送到模型。在參數中,max_new_tokens控制響應長度,而溫度調整了輸出的創造力級別。
> requests.post()函數將數據發送到擁抱面。如果響應成功(status_code == 200),則提取生成的文本。如果有錯誤,則返回描述性消息。>
>最後,有一些步驟可以正確清潔和格式化輸出。這樣可以確保它整齊地展示,從而大大改善了用戶體驗。構建精簡前端
前端是用戶與應用程序進行交互的地方。簡化是一個僅使用Python代碼創建交互式Web應用程序的庫,並使此過程變得簡單而直觀。這就是我們將用來構建應用程序前端的方法。我真的很喜歡簡化來構建演示和POC!
>>導入流lit
mkdir multilingual-code-explanation cd multilingual-code-explanation
>我們將使用set_page_config()來定義應用標題和佈局。在下面的代碼中:
python3 -m venv venv source venv/bin/activate’
> st.sidebar.title():為側邊欄創建標題。
pip install streamlit requests transformers huggingface-hub
> text_area():為粘貼代碼創建一個大盒子。
import requests
text_input():允許用戶輸入語言。
HUGGINGFACE_API_KEY = "hf_your_api_key_here" # Replace with your actual API key
API_URL = "https://api-inference.huggingface.co/models/meta-llama/Llama-3.3-70B-Instruct"
HEADERS = {"Authorization": f"Bearer {HUGGINGFACE_API_KEY}"}在查詢API時顯示旋轉器。
def query_llama3(input_text, language):
# Create the prompt
prompt = (
f"Provide a simple explanation of this code in {language}:\n\n{input_text}\n"
f"Only output the explanation and nothing else. Make sure that the output is written in {language} and only in {language}"
)
# Payload for the API
payload = {
"inputs": prompt,
"parameters": {"max_new_tokens": 500, "temperature": 0.3},
}
# Make the API request
response = requests.post(API_URL, headers=HEADERS, json=payload)
if response.status_code == 200:
result = response.json()
# Extract the response text
full_response = result[0]["generated_text"] if isinstance(result, list) else result.get("generated_text", "")
# Clean up: Remove the prompt itself from the response
clean_response = full_response.replace(prompt, "").strip()
# Further clean any leading colons or formatting
if ":" in clean_response:
clean_response = clean_response.split(":", 1)[-1].strip()
return clean_response or "No explanation available."
else:
return f"Error: {response.status_code} - {response.text}"顯示如果缺少輸入,則顯示生成的解釋或警告。
該應用程序將在您的瀏覽器中打開,您可以開始使用它!
>import streamlit as st
測試Llama 3.3行動
st.set_page_config(page_title="Multilingual Code Explanation Assistant", layout="wide")
測試1:python中的階乘功能
對於我們的第一個測試,讓我們從一個Python腳本開始,該腳本可以使用遞歸計算數字的階乘。這是我們將使用的代碼:
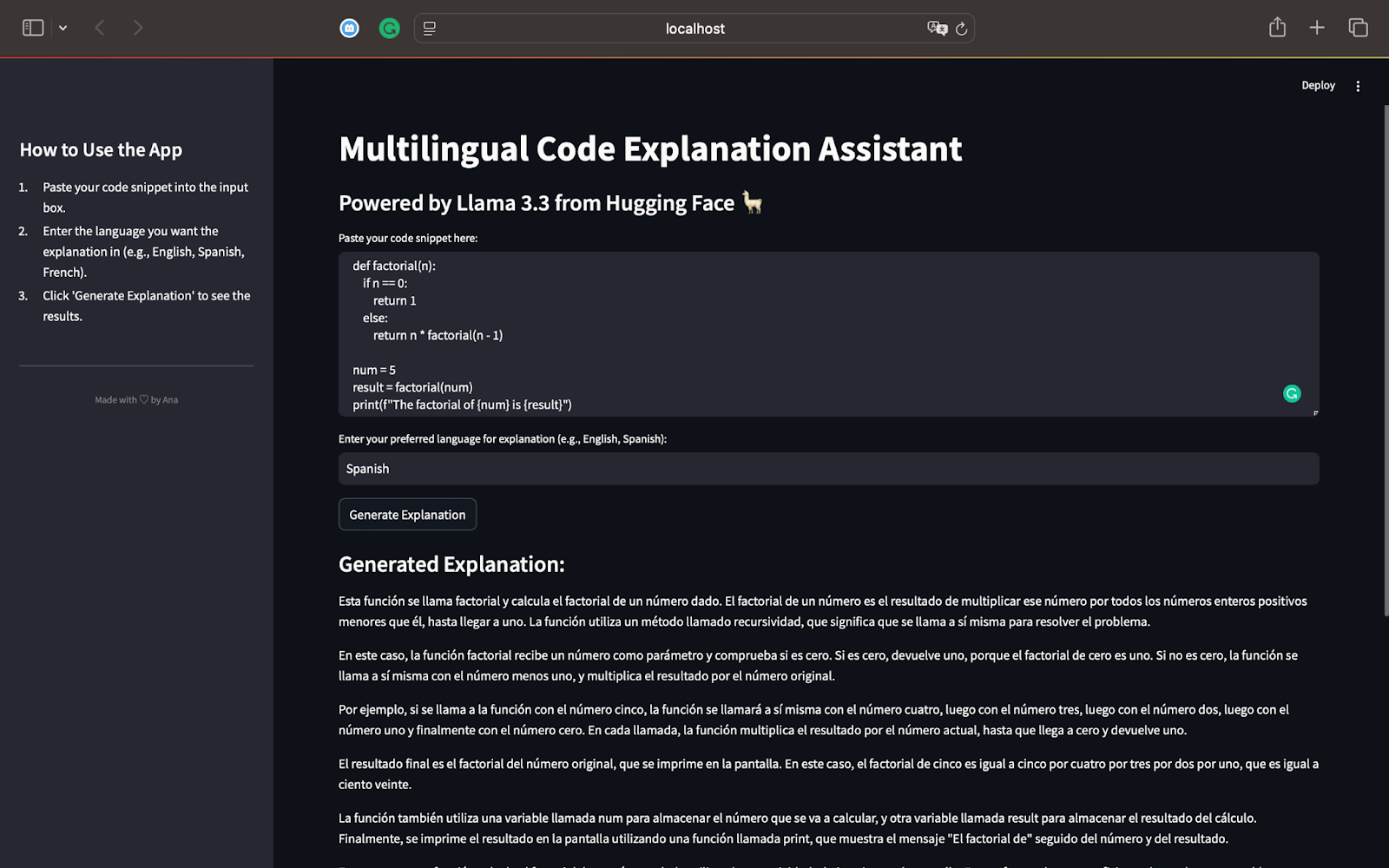

>該模型解釋了遞歸過程,並顯示了該函數如何以n值的降低為直到達到0。
的解釋完全按照要求,展示了Llama 3.3的多語言能力。的使用簡單短語使遞歸的概念易於遵循,即使對於不熟悉編程的讀者也很容易遵循。
>總結並提到了遞歸如何適用於其他輸入,以及遞歸作為編程中有效解決問題的概念的重要性。
>該第一次測試突出了駱駝3.3的力量:
它以逐步的方式準確地解釋了代碼。
>>解釋適用於請求的語言(在這種情況下為西班牙語)。
此代碼段定義遞歸函數x(a),該函數計算給定數字a的階乘。基本條件檢查是否=== 1。如果是,則返回1。否則,該函數用-1調用自身,並將結果乘以a。常數y設置為6,因此函數x計算6×5×4×3×2×1。 fnally,結果存儲在變量z中,並使用console.log顯示。這是英文的輸出和翻譯:
>注意:您可以看到它看起來像是突然裁剪了響應,但這是因為我們將輸出限制為500個令牌!
>翻譯此內容後,我得出的結論是,解釋正確地識別了函數x(a)是遞歸的。它分解了遞歸的工作原理,解釋了基本情況(a === 1)和遞歸情況(a * x(a -1))。該解釋明確顯示了該函數如何計算6的階乘,並提及Y(輸入值)和Z(結果)的作用。它還指出了console.log用於顯示結果的方式。> 根據要求,
的解釋完全用法語。正確使用了諸如“Récursive”(遞歸),“ Factorielle”(階乘)和“ Produit”(產品)之類的技術術語。不僅如此,它還標識了此代碼以遞歸方式計算數字的階乘。>
>解釋避免了過度技術術語並簡化了遞歸,使得剛接觸編程的讀者可以訪問。此測試證明了Llama 3.3:
在最後一次測試中,我們將評估多語言代碼說明應用程序如何處理SQL查詢並生成德語說明。這是使用的SQL摘要:
>此查詢選擇ID列併計算每個ID的總值(sum(b.value))。它從兩個表中讀取數據:table_x(Aliase為a)和table_y(將其混為為b)。然後,使用聯接條件連接行,其中a.ref_id = b.ref。它過濾行,其中b.flag = 1並按A.ID分組數據。 HAVER子句將組僅包括B.Value總和大於1000的那些。最後,按deal_amount訂購結果。
mkdir multilingual-code-explanation cd multilingual-code-explanation
生成的解釋是簡潔,準確且結構良好的。清楚地解釋了每個密鑰SQL子句(從,從,加入,加入,在哪裡,組,擁有和訂購)。此外,描述與SQL中的執行順序匹配,該說明可以幫助讀者逐步遵循查詢邏輯。
>解釋完全是德語的。  >
在上下文中準確使用了
>
在上下文中準確使用了
>解釋避免了過於復雜的術語,並專注於每個子句的功能。這使初學者很容易理解查詢的工作原理。
此測試證明了Llama 3.3:
在本教程中,您學會了:
如何將擁抱的面部模型集成到簡化的應用程序中。
>如何使用Llama 3.3 API解釋代碼片段。
以上是Llama 3.3:演示項目的分步教程的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















