
DeepSeek開創性的開源版本:CUDA內核加速LLMS。 這種優化的多立體注意(MLA)解碼內核(專為料斗GPU設計)顯著提高了AI模型託管的速度和效率。 關鍵改進包括BF16支持和分類的KV緩存(64座尺寸),從而產生了令人印象深刻的性能基準。
? #opensourceweek的第一天:flashmlaDeepSeek自豪地推出了Flashmla,這是霍珀GPU的高效MLA解碼內核。針對可變長度序列進行了優化,現在正在生產中。
✅bf16支持
✅分頁kv緩存(塊尺寸64)3000 GB/S內存和580個TFLOPS…
- DeepSeek(@Deepseek_ai)2025年2月24日
密鑰功能:
bf16精度:
在保持數值穩定性的同時啟用有效的計算。什麼是flashmla?
了解多頭潛在註意力(MLA) 標準的多頭注意力限制
>
霍普體系結構GPU(例如H800 SXM5)> cuda 12.3
> pytorch 2.0
這種出色的性能使FlashMLA非常適合要求AI工作負載。
了解多頭潛在註意(MLA)標準多頭注意力限制:
> MHA的KV高速緩存以序列長度線性縮放,為長序列創建一個存儲器瓶頸。 緩存大小的計算為:
(其中是注意頭的數量,而seq_len * n_h * d_h是頭維)。 n_h
d_h
MLA將密鑰和值壓縮到較小的潛在向量(
)中,將KV高速緩存大小降低到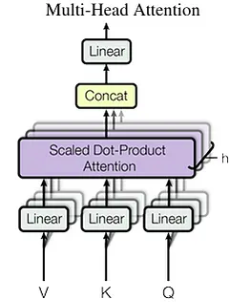 >(其中
>(其中
c_tseq_len * d_c>鍵值緩存和自動回歸解碼d_c
kV緩存可以加速自迴旋解碼。 但是,這增加了內存使用量。
解決內存挑戰:
>諸如多Query注意(MQA)和分組 - 問題註意(GQA)等技術減輕與KV緩存相關的內存問題。
> flashmla在DeepSeek模型中的作用:> FlashMLA
Powers DeepSeek的R1和V3型號,實現了有效的大規模AI應用程序。> nvidia hopper體系結構
Nvidia Hopper是一種專為AI和HPC工作負載而設計的高性能GPU架構。 它的創新(例如變壓器引擎和第二代MIG)可實現出色的速度和可擴展性。
>性能分析和含義
FlashMLA可實現BF16矩陣乘法的580個TFLOPS,是H800 GPU的理論峰的兩倍以上。 這證明了GPU資源的高效利用。
結論
FlashMLA代表了AI推理效率的重大進步,尤其是對於Hopper GPU。 它的MLA優化,結合BF16支持和分頁的KV緩存,可提供顯著的性能。 這使大規模的AI模型更容易訪問和成本效益,為模型效率樹立了新的基準。>
以上是DeepSeek推出了FlashMLA的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















