多模式檢索增強發電(RAG)已徹底改變了大型語言模型(LLMS)的訪問和利用外部數據,超越了傳統的僅限文本限制。 多模式數據的越來越多的流行率需要整合文本和視覺信息才能進行綜合分析,尤其是在金融和科學研究等複雜領域。多模式抹布通過使LLM能夠處理文本和圖像來實現這一目標,從而改善了知識檢索和更細微的推理。本文詳細介紹了使用Google的Gemini模型,頂點AI和Langchain構建多模式的抹布系統,向您指導您完成每個步驟:環境設置,數據預處理,嵌入生成以及創建強大的文檔搜索引擎。
密鑰學習目標
>掌握多模式抹布的概念及其在增強數據檢索功能方面的重要性。 -
了解雙子座如何處理和集成文本和視覺數據。 >
- 學習利用頂點AI的功能來構建適合實時應用的可擴展AI模型。
>探索Langchain在將LLM與外部數據源無縫集成的作用中。 -
開發有效的框架,這些框架同時使用文本和視覺信息來確切,上下文感知的響應。 -
將這些技術應用於實際用例,例如內容生成,個性化建議和AI助手。
-
- >本文是數據科學博客馬拉鬆的一部分。
>
目錄的表
>多模式抹布:綜合概述
>使用的核心技術
系統體系結構解釋了-
>用頂點AI,Gemini和Langchain - 構建多模式的抹布系統
步驟1:環境配置-
步驟2:Google Cloud Project詳細信息-
>步驟3:頂點AI SDK初始化-
步驟4:導入必要的庫- >
步驟5:模型規格-
步驟6:數據攝入-
>步驟7:創建和部署頂點AI向量搜索索引和端點- >
>步驟8:獵犬創建和文檔加載-
步驟9:帶獵犬和雙子座LLM - 的鏈結構
步驟10:模型測試-
-
現實世界應用-
結論
常見問題-
-
多模式抹布:綜合概述- >
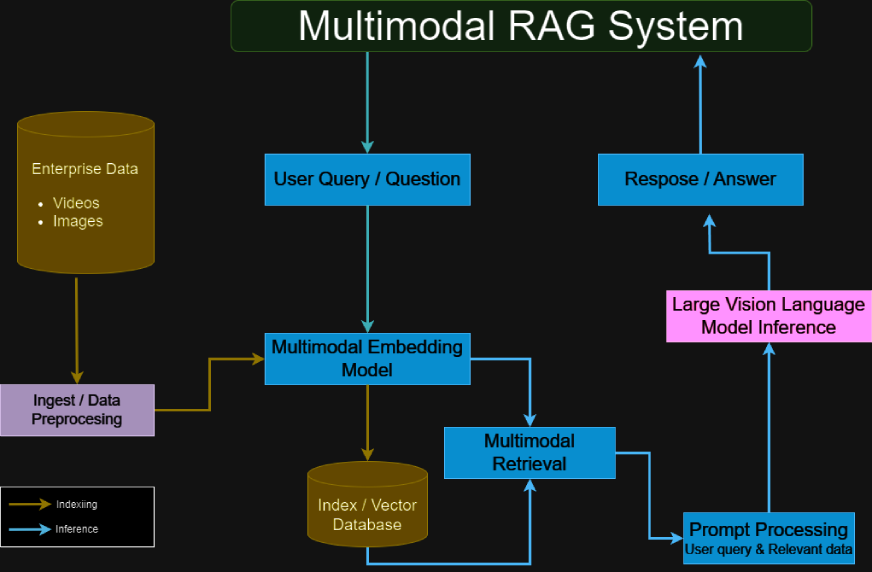
>多模式抹布系統結合了視覺和文本信息,以提供更豐富的,更相關的輸出。與傳統的基於文本的LLM不同,多模式抹布系統旨在攝入和處理視覺內容,例如圖表,圖形和圖像。這種雙重處理能力對於分析複雜數據集尤其有益,其中視覺元素與文本一樣豐富,例如財務報告,科學出版物或技術手冊。

通過處理文本和圖像,該模型可以更深入地了解數據,從而產生更準確和有見地的響應。這種集成減輕了產生誤導或事實不正確的信息(機器學習中的常見問題)的風險,從而導致更可靠的決策和分析產出。
>使用
的核心技術
本節總結了所使用的關鍵技術:
> google Deepmind的雙子座:
一個強大的生成AI套件,設計用於多模式任務,能夠無縫處理和生成文本和圖像。 - >
> dertex ai:一個用於開發,部署和縮放機器學習模型的綜合平台,具有可靠的矢量搜索功能,可用於有效的多模式數據檢索。
>
- >> langchain:>一個框架,簡化了LLM與各種工具和數據源的集成,從而促進了模型,嵌入式和外部資源之間的連接。 >
>- >檢索 - 傑出生成(RAG)框架:結合基於檢索的基於檢索的模型和基於生成的模型,以通過從外部來源從外部來源領取相關的上下文,在生成輸出之前,以提高響應準確性,非常適合處理多模態內容。 >>>>>>>>>>>。
>
OpenAi的dall·e:- (可選)圖像生成模型,該模型將文本提示轉換為視覺內容,增強具有上下文相關圖像的多模式抹布輸出。
用於多模式處理的>
變壓器:用於處理混合輸入類型的基礎體系結構,啟用涉及文本和視覺數據的有效處理和響應生成。
-
系統體系結構解釋了
-
>多模式抹布系統通常包括:
用於多模式處理的Gemini-
處理文本和圖像輸入,從每種模式中提取詳細信息。
>- >頂點AI矢量搜索:提供了一個矢量數據庫,用於有效嵌入管理和數據檢索。 >
> langchain MultivectorRetriever:- >作為中介,根據用戶查詢從矢量數據庫中檢索相關數據。 >
RAG框架集成:- 將檢索到的數據與LLM的生成能力結合在一起,以創建準確,上下文富裕的響應。
>多模式編碼器:
融合了文本和視覺內容,確保兩種數據類型都有效地有助於輸出。
用於混合數據處理的- > 變壓器:利用注意機制來對齊和整合來自不同模態的信息。
- >微調管道:(可選)定制培訓程序,這些培訓程序基於特定的多模式數據集優化模型性能,以提高準確性和上下文理解。 >
-
(其餘部分,步驟1-10,實際應用,結論和常見問題解答將遵循類似的重塑和重組模式,以保持原始含義,同時避免逐字化重複。這些圖像將保持其原始格式和位置。)
以上是用頂點AI和Gemini掌握多模式抹布的內容的詳細內容。更多資訊請關注PHP中文網其他相關文章!