
光束搜索:深入研究這種強大的解碼算法
光束搜索是自然語言處理(NLP)和機器學習的關鍵解碼算法,尤其是對於序列生成任務,例如文本生成,機器翻譯和摘要。 它有效地平衡了搜索空間的探索與高質量輸出的產生。本文提供了對光束搜索的全面概述,包括其機制,實施,應用和局限性。
密鑰學習目標:
表:
梁搜索機構
在解碼梁搜索機構>
光束搜索是通過遍歷節點代表令牌和邊緣代表過渡概率的圖的圖來運行的。 在每個步驟中:
它將這些令牌擴展為序列,計算其累積概率。
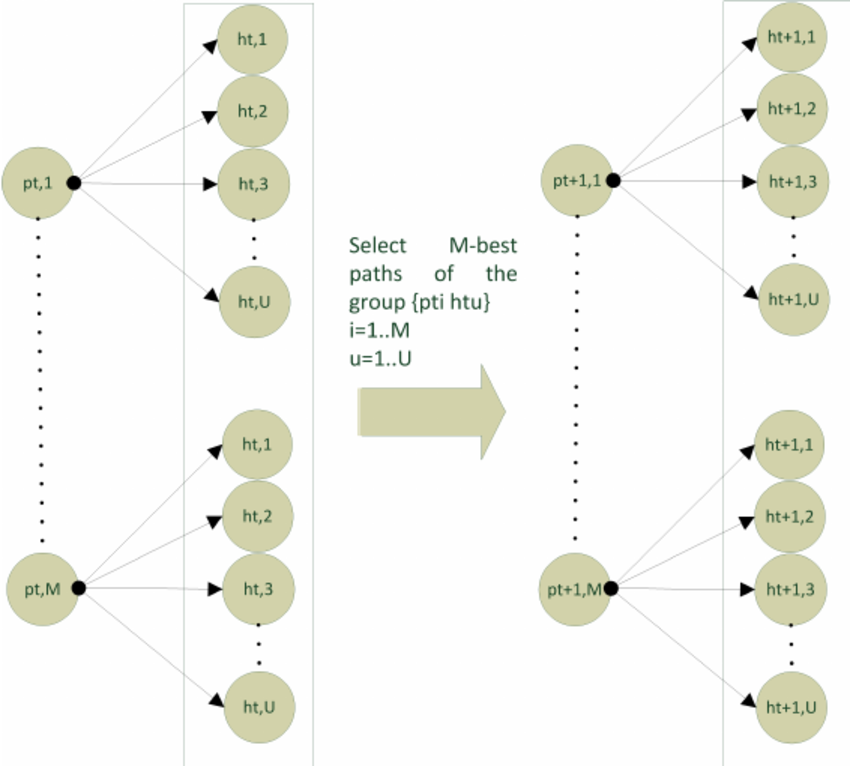 它僅保留下一步的頂部
它僅保留下一步的頂部
序列。
>樑寬度(k)是關鍵參數。更寬的光束探索了更多的序列,可能會提高產出質量,但顯著提高了計算成本。較窄的光束更快,但風險會缺少上級序列。
梁搜索在解碼
中的重要性光束搜索對於解碼至關重要,因為:
(步驟1:安裝和導入依賴項)>
(步驟2:模型和令牌設置)(步驟3-8:用於編碼輸入,輔助功能,遞歸光束搜索,最佳序列檢索和圖形繪圖的剩餘代碼部分是從原始文章中復制的。
(也從原始文章中復制了輸出示例。 梁搜索的挑戰和局限
儘管有優勢,但梁搜索仍有局限性:<code># Install transformers and graphviz !sudo apt-get install graphviz graphviz-dev !pip install transformers pygraphviz from transformers import GPT2LMHeadModel, GPT2Tokenizer import torch import matplotlib.pyplot as plt import networkx as nx import numpy as np from matplotlib.colors import LinearSegmentedColormap from tqdm import tqdm import matplotlib.colors as mcolors</code>
光束寬度選擇:
找到最佳光束寬度需要仔細的實驗。<code># Load model and tokenizer
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = GPT2LMHeadModel.from_pretrained('gpt2').to(device)
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model.eval()</code>>重複序列:它可以生成無需其他約束的重複或毫無意義的輸出。
對較短序列的偏置:概率累積方法可以偏愛較短的序列。
>結論
梁搜索是現代NLP中的基本算法,在效率和產出質量之間提供平衡。它的靈活性和生成相干序列的能力使其成為各種NLP應用程序的寶貴工具。儘管存在挑戰,但其適應性和有效性鞏固了其作為序列產生的基石的地位。
(本文所示的媒體不歸Analytics Vidhya擁有,並由作者酌情使用。)
以上是NLP解碼中的光束搜索是什麼?的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















