
Solar-10.7b
:深入研究高效的大型語言模型
Solar-10.7b項目了解Solar-10.7b
Solar-10.7b由AI上台下AI開發,是建立在Llama-2 Architecture上的107億個參數模型。 值得注意的是,它的表現優於其他LLM,其參數計數明顯較大,包括混合8x7b。 有關對Llama-2的全面了解,請參閱我們的微調指南。>深度縮放:一種新穎的縮放技術
深度尺度插圖。一個兩階段的過程結合了深度縮放和持續的預訓練。 (源)
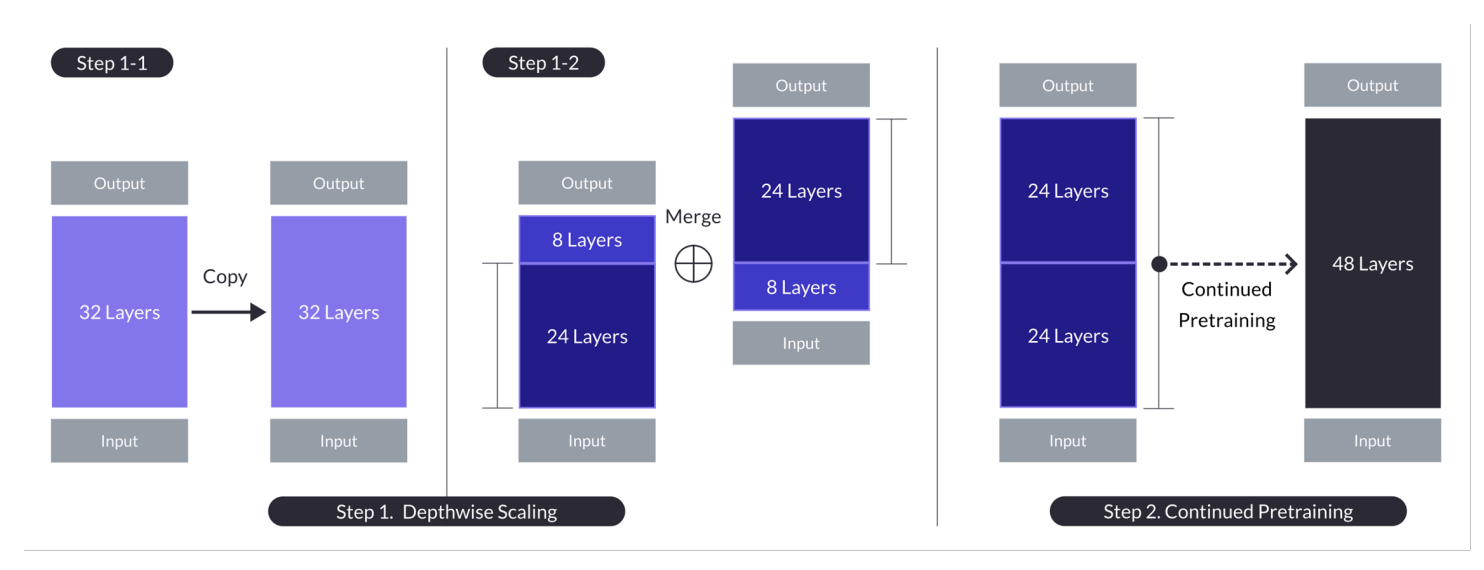 該過程涉及:
該過程涉及:
基本模型:
一個32層的Llama 2模型,用Mistral 7b權重初始化。
微調的Solar-10.7b型號提供了不同的應用:
1。安裝:
2。導入庫:
3。 GPU配置:確保啟用GPU(例如,使用Google COLAB的運行時設置)。用。 4。模型定義:
5。模型推理和結果生成:
DUS需要更廣泛的超參數探索。
個性化教育
使用Solar-10.7b-Instruct的實用指南
本節提供了使用Solar-10.7b-Instruct V1.0 GGUF模型的逐步指南。 pip -q install transformers==4.35.2
pip -q install accelerate
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
!nvidia-smi驗證
model_ID = "Upstage/SOLAR-10.7B-Instruct-v1.0"
tokenizer = AutoTokenizer.from_pretrained(model_ID)
model = AutoModelForCausalLM.from_pretrained(model_ID, device_map="auto", torch_dtype=torch.float16)
user_request = "What is the square root of 24?"
conversation = [{'role': 'user', 'content': user_request}]
prompt = tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, use_cache=True, max_length=4096)
output_text = tokenizer.decode(outputs[0])
print(output_text)
雖然功能強大,但Solar-10.7b有局限性:計算需求:
以上是Solar-10.7b微調模型教程的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















