
>本博客文章深入研究了Microsoft的Phi-2語言模型,將其性能與其他模型進行了比較,並詳細介紹了其培訓過程。 我們還將使用Transformers庫和擁抱的臉部角色扮演數據集介紹如何訪問和微調PHI-2。 Microsoft的“ PHI”系列中的27億參數模型
PHI-2,儘管大小相對較小,但其目標是最先進的性能。 它採用了一個變壓器體系結構,該體系結構對關注NLP和編碼的合成數據集和Web數據集進行了1.4萬億個代幣的培訓。 與許多較大的型號不同,PHI-2是一個沒有指令微調或RLHF的基本模型。>
>兩個關鍵方面推動了Phi-2的發展:
圖像源

圖像源

>通過擁抱的面孔空間演示探索Phi-2的功能:phi 2在GPU上流式傳輸。 該演示提供了基本的提示響應功能。
> AI新的? AI基礎知識技能軌道是一個很好的起點。
>讓我們使用推理 >管道(確保已安裝了最新的
>管道(確保已安裝了最新的
使用提示符,調整參數(例如transformers>
transformers
PHI-2的輸出令人印象深刻,生成了用解釋的代碼。 accelerate
!pip install -q -U transformers
!pip install -q -U accelerate
from transformers import pipeline
model_name = "microsoft/phi-2"
pipe = pipeline(
"text-generation",
model=model_name,
device_map="auto",
trust_remote_code=True,
)>
>微調PHI-2數據集上的微調phi-2。 hieunguyenminh/roleplay
!pip install -q -U transformers
!pip install -q -U accelerate
from transformers import pipeline
model_name = "microsoft/phi-2"
pipe = pipeline(
"text-generation",
model=model_name,
device_map="auto",
trust_remote_code=True,
)
from IPython.display import Markdown
prompt = "Please create a Python application that can change wallpapers automatically."
outputs = pipe(
prompt,
max_new_tokens=300,
do_sample=True,
temperature=0.7,
top_k=50,
top_p=0.95,
)
Markdown(outputs[0]["generated_text"])
%%capture %pip install -U bitsandbytes %pip install -U transformers %pip install -U peft %pip install -U accelerate %pip install -U datasets %pip install -U trl
>
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
logging,
)
from peft import (
LoraConfig,
PeftModel,
prepare_model_for_kbit_training,
get_peft_model,
)
import os, torch
from datasets import load_dataset
from trl import SFTTrainer 
base_model = "microsoft/phi-2" dataset_name = "hieunguyenminh/roleplay" new_model = "phi-2-role-play"
# ... (Method to securely retrieve Hugging Face API token) ... !huggingface-cli login --token $secret_hf
dataset = load_dataset(dataset_name, split="train[0:1000]")
bnb_config = BitsAndBytesConfig(
load_in_4bit= True,
bnb_4bit_quant_type= "nf4",
bnb_4bit_compute_dtype= torch.bfloat16,
bnb_4bit_use_double_quant= False,
)
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token 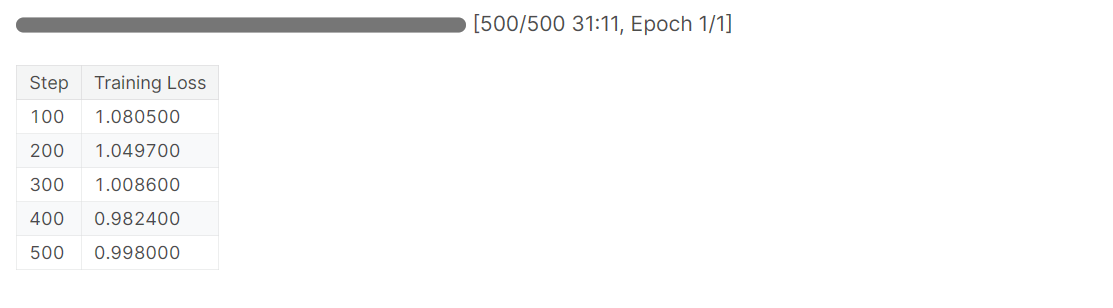
model = prepare_model_for_kbit_training(model)
peft_config = LoraConfig(
r=16,
lora_alpha=16,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=[
'q_proj',
'k_proj',
'v_proj',
'dense',
'fc1',
'fc2',
]
)
model = get_peft_model(model, peft_config) 
圖像源
模型評估
training_arguments = TrainingArguments(
output_dir="./results", # Replace with your desired output directory
num_train_epochs=1,
per_device_train_batch_size=2,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
save_strategy="epoch",
logging_steps=100,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
disable_tqdm=False,
report_to="none",
)
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
max_seq_length= 2048,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)
trainer.train() 
>
以上是開始使用PHI-2的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















