
>本指南展示了使用低級適配器(LORA)適配器和擁抱臉的Microsoft PHI-4大語言模型(LLM)進行專門任務。 通過專注於特定域,您可以優化PHI-4的性能,以諸如客戶支持或醫療建議之類的應用程序。 洛拉的效率使這個過程更快,更少的資源密集型。
>鍵學習成果:
unsloth。
SFTTrainer
開始之前,請確保您有:
python 3.8pytorch(在CUDA支持GPU加速度)
unsloth>
transformers安裝必要的庫
datasets
pip install unsloth pip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
步驟1:Model Setup
>
這涉及加載模型和導入基本庫:
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/Phi-4",
max_seq_length=max_seq_length,
load_in_4bit=load_in_4bit,
)
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth",
random_state=3407,
) >
>
 >我們將以ShareGpt格式使用Finetome-100K數據集。
>我們將以ShareGpt格式使用Finetome-100K數據集。
unsloth
from datasets import load_dataset
from unsloth.chat_templates import standardize_sharegpt, get_chat_template
dataset = load_dataset("mlabonne/FineTome-100k", split="train")
dataset = standardize_sharegpt(dataset)
tokenizer = get_chat_template(tokenizer, chat_template="phi-4")
def formatting_prompts_func(examples):
texts = [
tokenizer.apply_chat_template(convo, tokenize=False, add_generation_prompt=False)
for convo in examples["conversations"]
]
return {"text": texts}
dataset = dataset.map(formatting_prompts_func, batched=True)
 使用擁抱臉的微調
使用擁抱臉的微調
>
SFTTrainer
from trl import SFTTrainer
from transformers import TrainingArguments, DataCollatorForSeq2Seq
from unsloth import is_bfloat16_supported
from unsloth.chat_templates import train_on_responses_only
trainer = SFTTrainer(
# ... (Trainer configuration as in the original response) ...
)
trainer = train_on_responses_only(
trainer,
instruction_part="user",
response_part="assistant",
) >
>
 監視GPU內存使用率:
監視GPU內存使用率:
步驟5:推理
import torch # ... (GPU monitoring code as in the original response) ...
 生成響應:
生成響應:
pip install unsloth pip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git


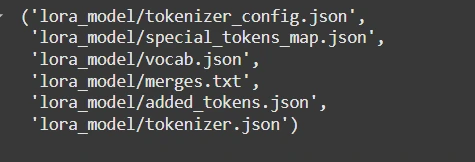
>步驟6:保存和上傳
>>在本地保存或推到擁抱面孔:
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/Phi-4",
max_seq_length=max_seq_length,
load_in_4bit=load_in_4bit,
)
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth",
random_state=3407,
)
記住用實際的擁抱臉代幣替換<your_hf_token></your_hf_token>>
結論:
>
以上是如何在本地微調PHI-4?的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















