
在許多現實世界應用中,數據並不純粹是文本的,其中可能包括圖像,表和圖表,這些圖表和圖表有助於加強敘述。多模式報告生成器允許您將文本和圖像同時合併到最終輸出中,從而使您的報告更具動態性和視覺上的豐富。
本文概述瞭如何使用以下方式構建這樣的管道
學習目標
> > data Science Blogathon的一部分。 目錄的>>
>設置完成後,管道將處理PDF文檔,將其內容解析到結構化文本中,並渲染諸如表和圖表之類的視覺元素。然後關聯了這些解析的元素,創建一個統一的數據集。構建了一個摘要,以啟用高級見解,並開發了結構化的查詢引擎,以生成將文本分析與相關視覺效果融合的報告。結果是一個動態和交互式報告生成器,該生成器將靜態文檔轉換為用於用戶查詢的豐富的多模式輸出。
>>按照本詳細指南構建多模式報告生成器,從設置依賴項到使用集成的文本和圖像生成結構化輸出。每個步驟都確保Llamaindex,Llamaparse和Arize Phoenix的無縫整合,以進行有效而動態的管道。
您需要在Python 3.9.9上運行的以下庫:
!pip install -U llama-index-callbacks-arize-phoenix import nest_asyncio nest_asyncio.apply()
例如:
步驟3:加載數據 - 獲取幻燈片甲板
PHOENIX_API_KEY = "<PHOENIX_API_KEY>"
os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"api_key={PHOENIX_API_KEY}"
llama_index.core.set_global_handler(
"arize_phoenix", endpoint="https://llamatrace.com/v1/traces"
)>檢查PDF幻燈片是否在數據文件夾中,如果不將其放在數據文件夾中並按照您的要求命名。
import os
import requests
# Create the directories (ignore errors if they already exist)
os.makedirs("data", exist_ok=True)
os.makedirs("data_images", exist_ok=True)
# URL of the PDF
url = "https://static.conocophillips.com/files/2023-conocophillips-aim-presentation.pdf"
# Download and save to data/conocophillips.pdf
response = requests.get(url)
with open("data/conocophillips.pdf", "wb") as f:
f.write(response.content)
print("PDF downloaded to data/conocophillips.pdf")>您需要嵌入模型和LLM。在此示例中:
接下來,您將其註冊為LlamainDex的默認值:
from llama_index.llms.openai import OpenAI from llama_index.embeddings.openai import OpenAIEmbedding embed_model = OpenAIEmbedding(model="text-embedding-3-large") llm = OpenAI(model="gpt-4o")
解析文件 Llamaparse可以提取文本和圖像(通過多模式大型模型)提取文本和圖像。對於每個PDF頁面,它返回:
from llama_index.core import Settings Settings.embed_model = embed_model Settings.llm = llm
(帶錶,標題,子彈點等)
print(f"Parsing slide deck...")
md_json_objs = parser.get_json_result("data/conocophillips.pdf")
md_json_list = md_json_objs[0]["pages"]

print(md_json_list[10]["md"])
!pip install -U llama-index-callbacks-arize-phoenix import nest_asyncio nest_asyncio.apply()
我們為每個頁面創建一個>> textnode
PHOENIX_API_KEY = "<PHOENIX_API_KEY>"
os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"api_key={PHOENIX_API_KEY}"
llama_index.core.set_global_handler(
"arize_phoenix", endpoint="https://llamatrace.com/v1/traces"
) 
摘要確保您可以輕鬆地檢索或生成整個文檔上的高級摘要。
import os
import requests
# Create the directories (ignore errors if they already exist)
os.makedirs("data", exist_ok=True)
os.makedirs("data_images", exist_ok=True)
# URL of the PDF
url = "https://static.conocophillips.com/files/2023-conocophillips-aim-presentation.pdf"
# Download and save to data/conocophillips.pdf
response = requests.get(url)
with open("data/conocophillips.pdf", "wb") as f:
f.write(response.content)
print("PDF downloaded to data/conocophillips.pdf")我們的管道旨在產生帶有交織的文本塊和圖像塊的最終輸出。為此,我們創建了一種自定義的pydantic模型(使用Pydantic V2或確保兼容性),具有兩種塊類型-e
和> imageBlock - 和一個父母模型 關鍵點:
reportOutput需要至少一個圖像塊,確保最終答案是多模式的。
from llama_index.core import Settings Settings.embed_model = embed_model Settings.llm = llm

print(f"Parsing slide deck...")
md_json_objs = parser.get_json_result("data/conocophillips.pdf")
md_json_list = md_json_objs[0]["pages"] 
print(md_json_list[10]["md"])
 結論
結論
>可以隨意將此管道適應您自己的文檔,為大型檔案添加檢索步驟,或集成特定領域的模型以分析基礎圖像。在這裡鋪設的基礎,您可以創建動態,互動和視覺上豐富的報告,這些報告遠遠超出了簡單的基於文本的查詢。
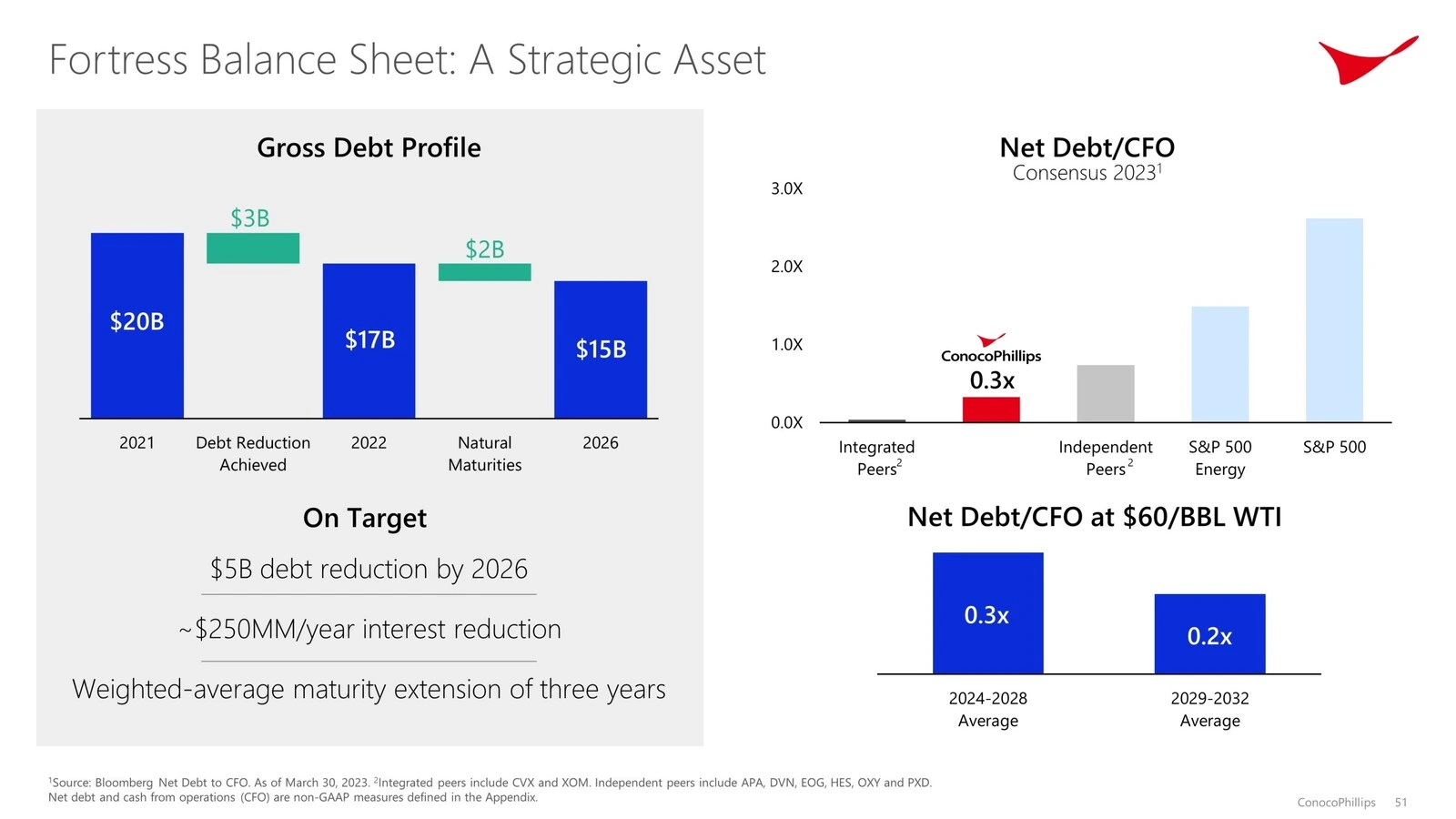 非常感謝Llamaindex的Jerry Liu開發了這款驚人的管道。
非常感謝Llamaindex的Jerry Liu開發了這款驚人的管道。
以上是使用LlamainDex的多模式財務報告生成的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















