為清晰度和準確性編輯,該數據掃描社區教程探討了圖像文本基礎模型,重點介紹了創新的對比字幕(COCA)模型。 可口可樂獨特地結合了對比和生成性學習目標,將諸如剪輯和simvlm之類的模型的優勢整合到單個體系結構中。

基礎模型:深水潛水
>
在大規模數據集上預先訓練的基礎模型適用於各種下游任務。 儘管NLP的基礎模型(GPT,BERT)激增,但視覺和視覺模型仍在不斷發展。研究探索了三種主要方法:單名模型,具有對比損失的圖像文本編碼器以及具有生成目標的編碼器模型。 每種方法都有局限性。
密鑰術語:
-
基礎模型:預先訓練的模型適用於各種應用。
- 對比損失:比較相似和不同輸入對的損失函數。
- >交叉模式相互作用:不同數據類型之間的相互作用(例如,圖像和文本)。
- > encoder-decoder體系結構: 神經網絡處理輸入和生成輸出。
零射擊學習:- 在看不見的數據類別上預測。
在
> simvlm:- 一個簡單的視覺語言模型。
- 模型比較:
單個編碼器模型:
在視覺任務上出色,但由於依賴人類註釋而與視力語言任務鬥爭。 >
image-Text雙編碼模型(剪輯,對齊):
非常適合零攝像分類和圖像檢索,但在需要融合的image-text表示的任務中有限(例如,視覺詢問)。
- 生成模型(SIMVLM):使用跨模式相互作用進行關節圖像文本表示,適用於VQA和圖像字幕。
- 可口可樂:橋接gap
- 可口架構:
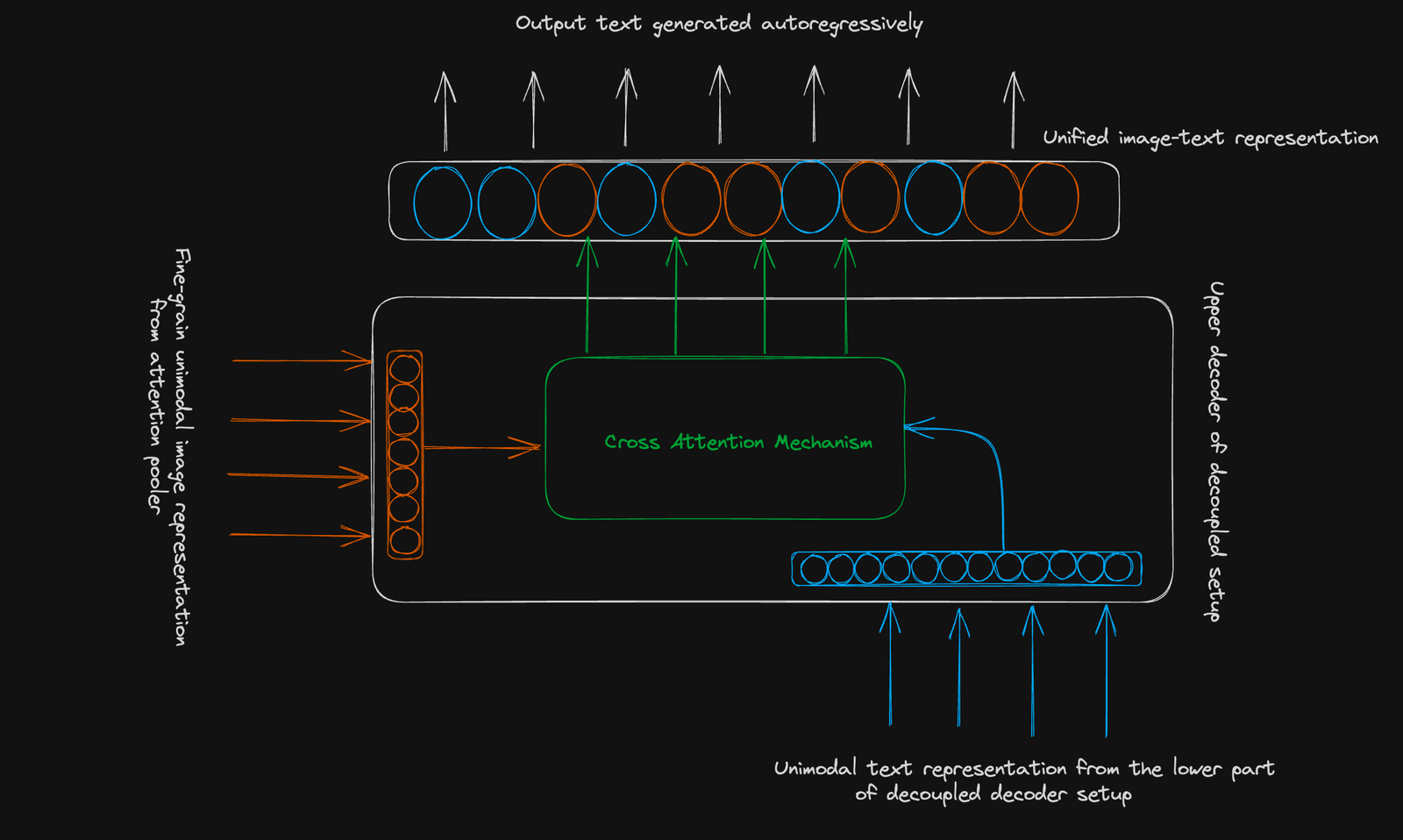
可口可使用的是標準的編碼器解碼器結構。 它的創新在於A
脫鉤的解碼器:>
-
較低解碼器:生成一個單峰文本表示對比度學習(使用[cls]令牌)。
- 上的解碼器:生成用於生成學習的多模式圖像文本表示。 兩個解碼器都使用因果掩蔽。
對比目標:學會在共享向量空間中群集相關的圖像文本對並分開無關的圖像對。 使用單個合併的圖像嵌入。
生成目標:使用細顆粒的圖像表示(256維序列)和交叉模式的注意來預測文本自動加註。
結論:
>可可代表圖像文本基礎模型中的顯著進步。其組合方法可以增強各種任務的性能,為下游應用程序提供多功能工具。 為了進一步了解先進的深度學習概念,請考慮Datacamp使用KERAS課程的高級深度學習。
進一步讀取:
>從自然語言監督中學習可轉移的視覺模型
>圖像文本預訓練與對比字幕
-
以上是可口可樂:對比字幕是圖像文本基礎模型在視覺上解釋的詳細內容。更多資訊請關注PHP中文網其他相關文章!