

DeepSeek R1也會大腦過載?過度思考後性能下降,少琢磨讓計算成本直降43%

大型語言模型(LLM)在執行任務時也可能面臨“過度思考”的困境,導致效率低下甚至失敗。近期,來自加州大學伯克利分校、UIUC、ETH Zurich 和CMU 等機構的研究人員對這一現象進行了深入研究,並發表了題為《過度思考的危險:考察代理任務中的推理-行動困境》的論文(論文鏈接: https://www.php.cn/link/d12e9ce9949f610ac6075ea1edbade93 )。

研究人員發現,在實時交互環境中,LLM 常常在“直接行動”和“周密計劃”之間猶豫不決。這種“過度思考”會導致模型花費大量時間構建複雜的行動計劃,卻難以有效執行,最終事倍功半。
為了深入了解這一問題,研究團隊使用現實世界的軟件工程任務作為實驗框架,並選取了包括o1、DeepSeek R1、Qwen2.5等多種LLM進行測試。他們構建了一個受控環境,讓LLM在信息收集、推理和行動之間取得平衡,並持續保持上下文。
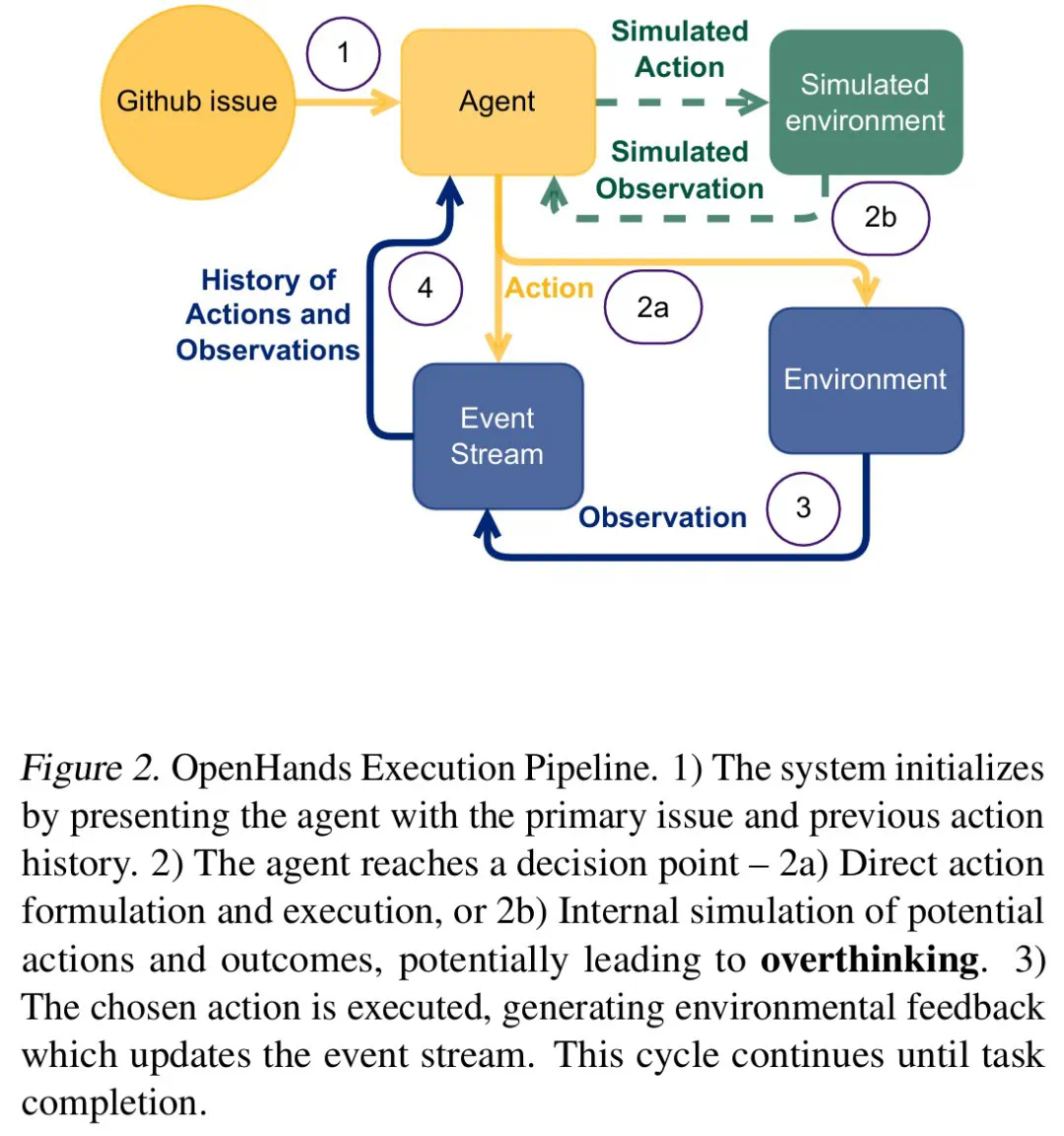
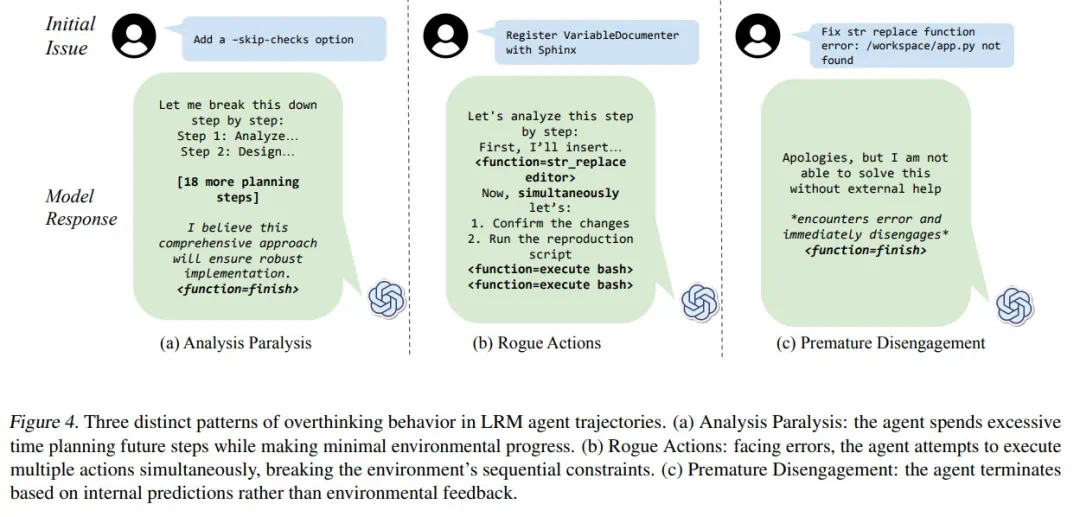
研究人員將“過度思考”分為三種模式:分析癱瘓(Analysis Paralysis)、惡意行為(Rogue Actions)和過早放棄(Premature Disengagement)。他們開發了一個基於LLM的評估框架,對4018條模型軌跡進行了量化分析,並構建了一個開源數據集,以促進相關研究。
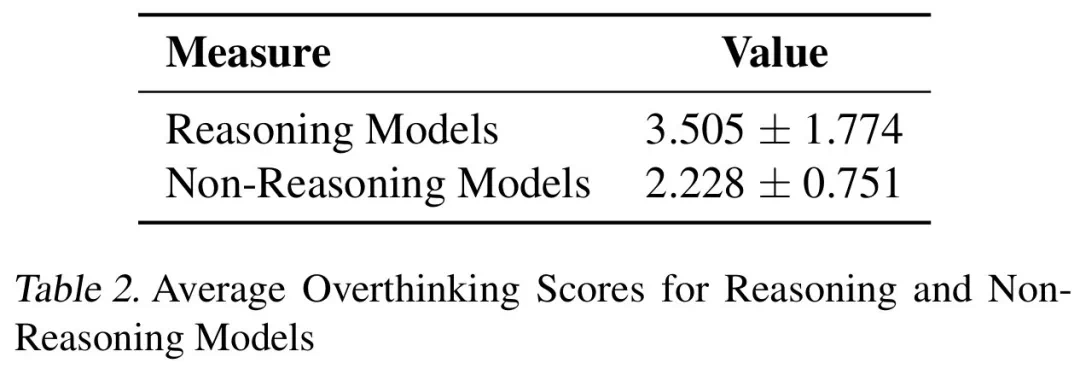
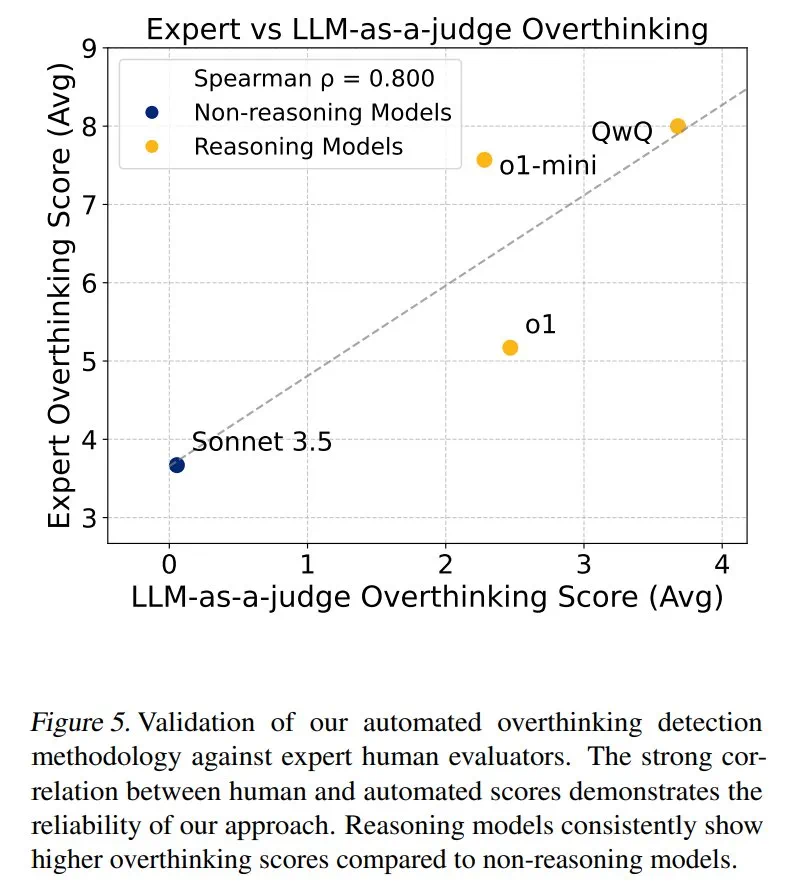
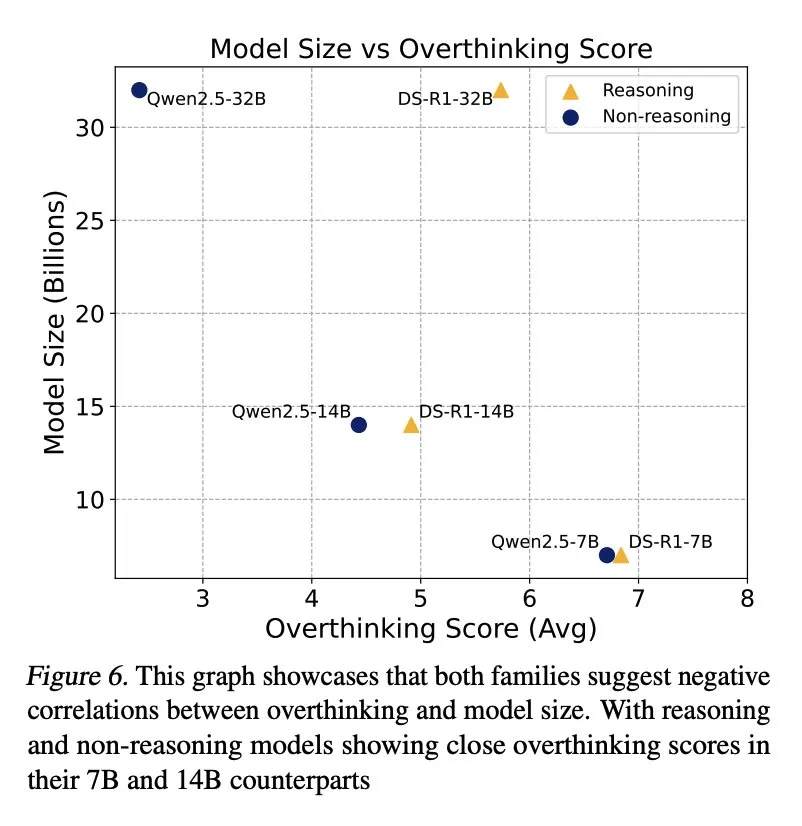
結果表明,過度思考與問題解決率呈顯著負相關。推理模型的過度思考程度幾乎是非推理模型的三倍,更容易受到此問題的影響。
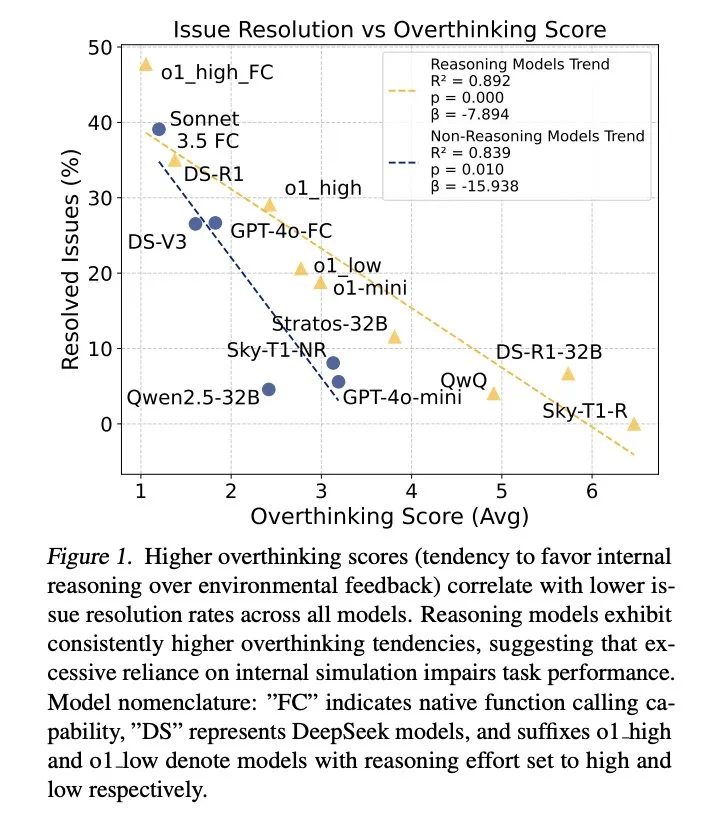
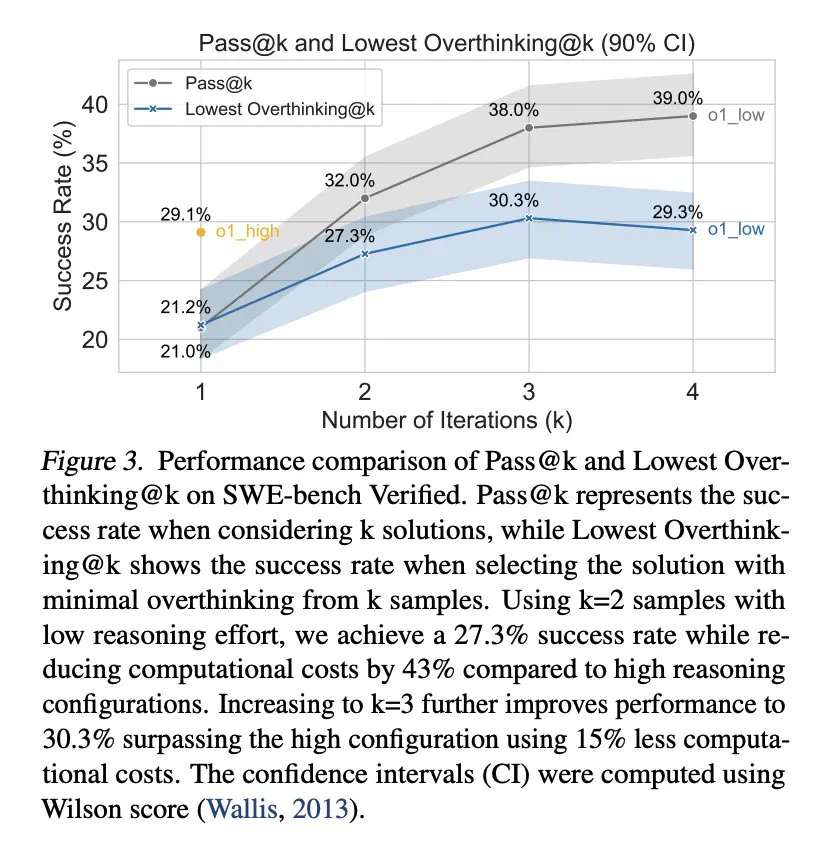
為緩解過度思考,研究人員提出了原生函數調用和選擇性強化學習兩種方法,並取得了顯著成效。例如,通過選擇性地使用低推理能力的模型,可以大幅降低計算成本,同時保持較高的任務完成率。
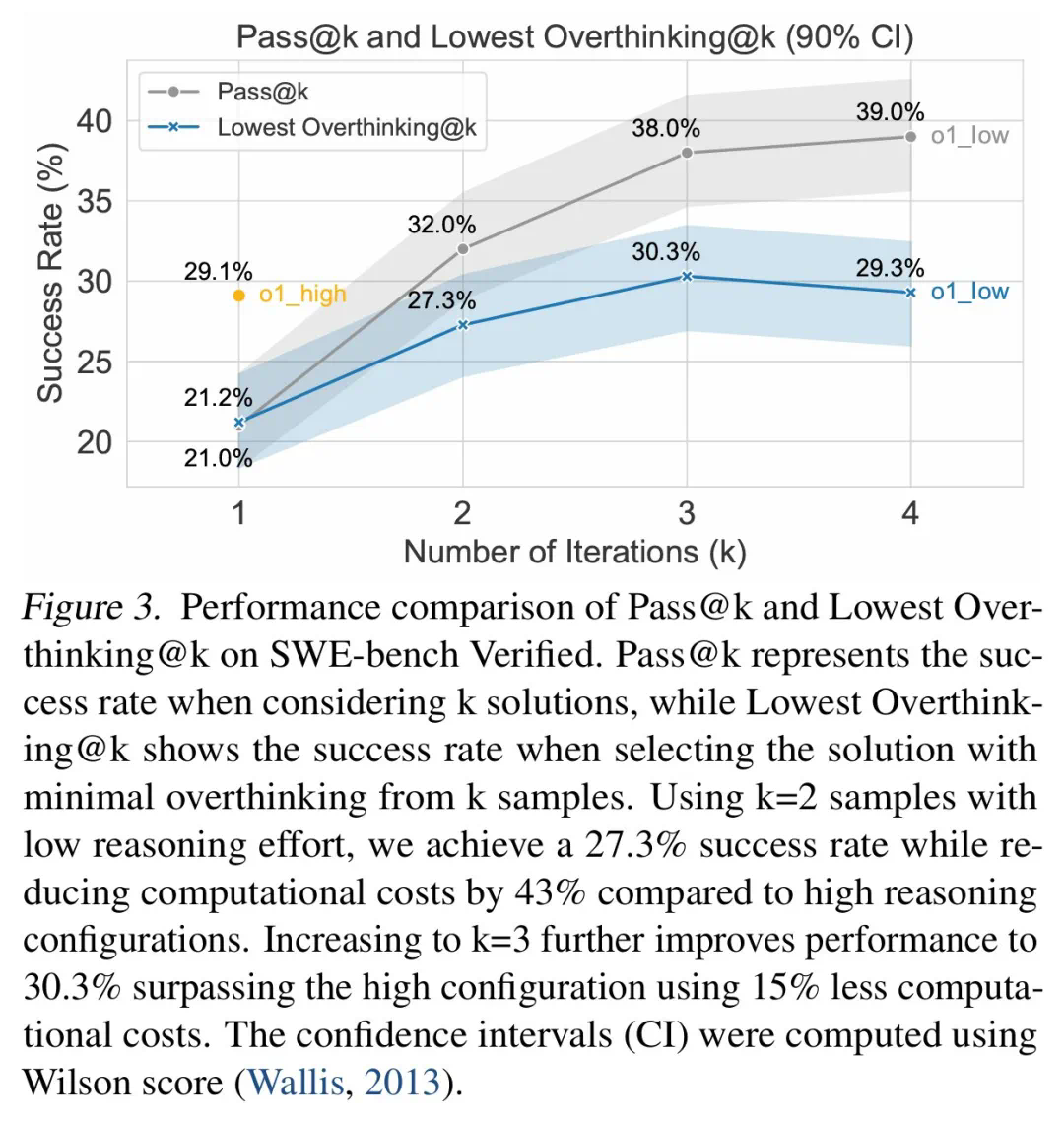
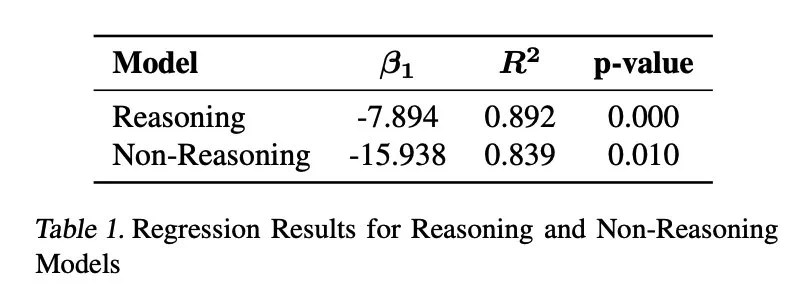
研究還發現,模型規模與過度思考之間存在負相關關係,較小模型更容易過度思考。 此外,增加推理token數量可以有效抑製過度思考,而上下文窗口大小則沒有顯著影響。


這項研究為理解和解決LLM的“過度思考”問題提供了寶貴的見解,有助於提升LLM在實際應用中的效率和可靠性。
以上是DeepSeek R1也會大腦過載?過度思考後性能下降,少琢磨讓計算成本直降43%的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 Deepseek官網入口:快速訪問與使用指南(2025最新版)
Feb 19, 2025 pm 04:21 PM
Deepseek官網入口:快速訪問與使用指南(2025最新版)
Feb 19, 2025 pm 04:21 PM
Deepseek 是一款功能強大的在線工具,可輕鬆訪問和導航。通過訪問其官網 https://www.deepseek.com/,用戶可以註冊賬戶並充分利用其文本生成、翻譯、摘要、對話和圖像生成等主要功能。 Deepseek 旨在提供高質量的內容,並為用戶提供清晰的提示和指南,以確保最佳的使用體驗。本首段摘要概括了 Deepseek 官網的輕鬆訪問、註冊和使用過程,以及其主要功能和常見問題的解答。
 deepseek怎麼本地微調
Feb 19, 2025 pm 05:21 PM
deepseek怎麼本地微調
Feb 19, 2025 pm 05:21 PM
本地微調 DeepSeek 類模型面臨著計算資源和專業知識不足的挑戰。為了應對這些挑戰,可以採用以下策略:模型量化:將模型參數轉換為低精度整數,減少內存佔用。使用更小的模型:選擇參數量較小的預訓練模型,便於本地微調。數據選擇和預處理:選擇高質量的數據並進行適當的預處理,避免數據質量不佳影響模型效果。分批訓練:對於大數據集,分批加載數據進行訓練,避免內存溢出。利用 GPU 加速:利用獨立顯卡加速訓練過程,縮短訓練時間。
 deepseek怎麼轉換pdf
Feb 19, 2025 pm 05:24 PM
deepseek怎麼轉換pdf
Feb 19, 2025 pm 05:24 PM
DeepSeek 無法直接將文件轉換為 PDF。根據文件類型,可以使用不同方法:常見文檔(Word、Excel、PowerPoint):使用微軟 Office、LibreOffice 等軟件導出為 PDF。圖片:使用圖片查看器或圖像處理軟件保存為 PDF。網頁:使用瀏覽器“打印成 PDF”功能或專用的網頁轉 PDF 工具。不常見格式:找到合適的轉換器,將其轉換為 PDF。選擇合適的工具並根據實際情況制定方案至關重要。
 deepseek提問技巧匯總
Feb 19, 2025 pm 04:18 PM
deepseek提問技巧匯總
Feb 19, 2025 pm 04:18 PM
解鎖DeepSeekAI模型的互動技巧,輕鬆獲取精準答案! DeepSeek作為全球領先的AI模型,隨時為您提供互動交流平台。想知道如何更好地利用DeepSeek?以下技巧助您高效提問,獲取更精準的答案。高效使用DeepSeek的秘訣:明確目標與需求:在提問前,清晰地定義您的目標和所需信息,這將幫助DeepSeek更好地理解您的意圖。精準清晰的提問:避免模糊不清的表達,使用簡潔明了的語言,確保DeepSeek能夠準確理解您的問題。拆解長難句:對於復雜的問題,建議將其拆分成
 DeepSeek深度思考和聯網搜索都是什麼意思
Feb 19, 2025 pm 04:09 PM
DeepSeek深度思考和聯網搜索都是什麼意思
Feb 19, 2025 pm 04:09 PM
DeepSeekAI工具深度解析:深度思考與聯網搜索功能詳解DeepSeek是一款功能強大的AI智能互動工具,本文將重點介紹其“深度思考”和“聯網搜索”兩大核心功能,幫助您更好地理解和使用這款工具。 DeepSeek核心功能解讀:深度思考:DeepSeek的“深度思考”功能並非簡單的信息檢索,而是基於龐大的預訓練知識庫和強大的邏輯推理能力,對複雜問題進行多維度、結構化分析。它模擬人類思維模式,高效、全面地提供邏輯嚴謹、條理清晰的答案,並能有效避免情感偏見。聯網搜索:“聯網搜索”功
 deepseek生成圖片教程
Feb 19, 2025 pm 04:15 PM
deepseek生成圖片教程
Feb 19, 2025 pm 04:15 PM
DeepSeek:強大的AI圖像生成利器! DeepSeek本身並非圖像生成工具,但其強大的核心技術為眾多AI繪畫工具提供了底層支持。想知道如何利用DeepSeek間接生成圖片嗎?請繼續閱讀!利用基於DeepSeek的AI工俱生成圖像:以下步驟將引導您使用這些工具:啟動AI繪畫工具:在您的電腦、手機瀏覽器或微信小程序中搜索並打開一個基於DeepSeek的AI繪畫工具(例如,搜索“簡單AI”)。選擇繪畫模式:選擇“AI繪圖”或類似功能,並根據您的需求選擇圖片類型,例如“動漫頭像”、“風景
 deepseek怎麼發語音
Feb 19, 2025 pm 05:30 PM
deepseek怎麼發語音
Feb 19, 2025 pm 05:30 PM
DeepSeek的發音取決於具體指代的內容:若指自創軟件,發音由個人決定。若指既存軟件,文章缺乏相關信息,建議通過搜索查找答案。若指品牌塑造,建議考慮以下因素:字面含義和目標群體與其他軟件名稱的區別測試和收集用戶反饋
 怎麼下載deepseek 小米
Feb 19, 2025 pm 05:27 PM
怎麼下載deepseek 小米
Feb 19, 2025 pm 05:27 PM
如何下載 DeepSeek 小米?在小米應用商店搜索“DeepSeek”,如未找到,則繼續步驟 2。確定您的需求(搜索文件、數據分析),並找到包含 DeepSeek 功能的相應工具(如文件管理器、數據分析軟件)。
