
通過合併信息檢索,檢索增強的生成(RAG)賦予大型語言模型(LLMS)。這使LLM可以訪問外部知識庫,從而產生更準確,最新和上下文適當的響應。高級抹布技術矯正抹布(crag),通過引入自我反射和自我評估機制來進一步提高準確性。
本文涵蓋:
作為數據科學博客馬拉鬆的一部分出版。
目錄
克拉格的基本機制
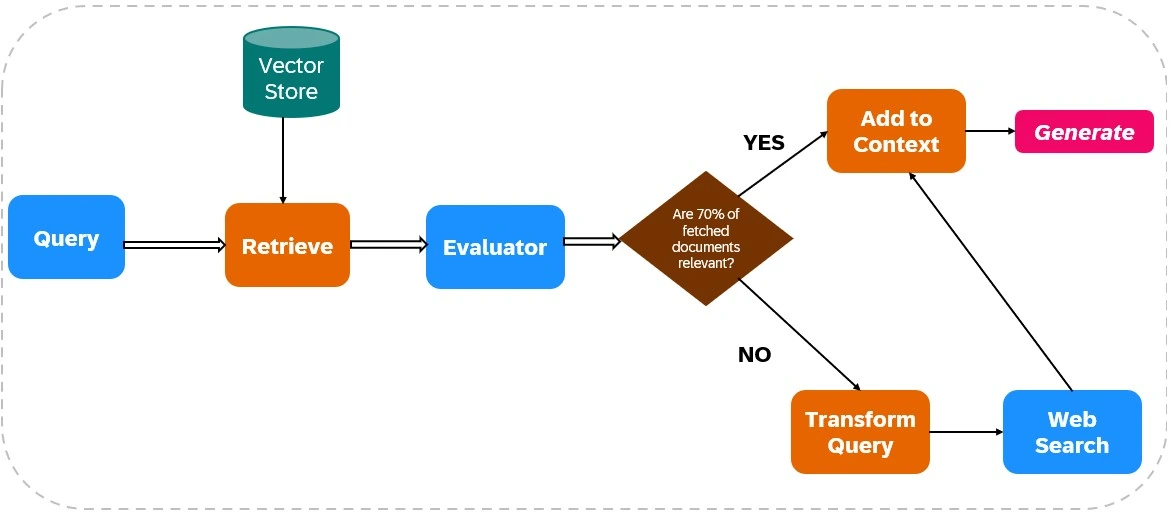
CRAG通過將Web搜索集成到其檢索和生成過程中來增強LLM輸出的可靠性(見圖1)。
文件檢索:
相關性評估:
評估者評估檢索的文件相關性。如果超過70%的文件被視為無關緊要,則啟動糾正措施;否則,響應產生將進行。
Web搜索集成:
如果文檔相關性不足,則CRAG使用Web搜索:
響應生成:
CRAG從初始檢索和Web搜索中綜合數據,以創建一個連貫,準確的響應。
岩壁與傳統抹布
與傳統抹布不同,Crag會積極驗證和完善檢索到的信息,這與傳統的抹布不同,這依賴於未經驗證的文檔檢索。 CRAG經常合併實時的Web搜索,從而提供對最新信息的訪問,這與傳統抹布對靜態知識庫的依賴不同。這使得crag非常適合需要高精度和實時數據集成的應用程序。
實用的crag實施
本節詳細介紹了使用Python,Langchain和Tavily的CRAG實施。
步驟1:庫安裝
安裝必要的庫:
! !
步驟2:API密鑰配置
設置您的API鍵:
導入操作系統 os.environ [“ tavily_api_key”] =“” os.environ [“ openai_api_key”] =“”
步驟3:庫導入
導入所需的庫(省略了簡短的代碼,但類似於原始示例)。
步驟4:記錄分塊和獵犬的創建
(對於簡短而省略了代碼,但類似於原始示例,使用pypdfloader,遞歸cearsivecharactertextsplitter,openaiembeddings和Chroma)。
步驟5:抹布鏈設置
(對於簡短而省略了代碼,但類似於原始示例,使用hub.pull("rlm/rag-prompt")和ChatOpenAI )。
步驟6:評估器設置
(為簡潔而省略了代碼,但類似於原始示例,定義Evaluator類並使用ChatOpenAI進行評估)。
步驟7:查詢重寫器設置
(為簡潔而省略了代碼,但類似於原始示例,使用ChatOpenAI進行查詢重寫)。
步驟8:Web搜索設置
來自langchain_community.tools.tavily_search導入tavilySearchResults web_search_tool = tavilySearchResults(k = 3)
步驟9-12:Langgraph Workflow設置和執行
(為簡短而省略了代碼,但在概念上與原始示例相似,定義GraphState ,函數節點( retrieve , generate , evaluate_documents , transform_query , web_search ),並使用StateGraph進行連接。)最終輸出和與傳統抹布的比較也非常相似。
克拉格的挑戰
CRAG的有效性在很大程度上取決於評估者的準確性。弱評估者可能會引入錯誤。可伸縮性和適應性也是關注點,需要持續更新和培訓。 Web搜索集成引入了偏見或不可靠的信息的風險,需要強大的過濾機制。
結論
CRAG顯著提高了LLM輸出精度和可靠性。其評估和補充使用實時Web數據檢索信息的能力使其對於要求高精度和最新信息的應用程序很有價值。但是,持續改進對於解決與評估者準確性和Web數據可靠性相關的挑戰至關重要。
關鍵要點(類似於原始的,但為簡潔而改寫)
經常詢問的問題(類似於原始問題,但為簡潔而改寫)
(注意:圖像保持不變,並且如原始輸入所示。)
以上是矯正抹布(crag)行動的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















