
專家(MOE)模型的混合物正在通過提高效率和可擴展性來徹底改變大型語言模型(LLM)。這種創新的體系結構將模型分為專門的子網絡或“專家”,每個人都接受了特定數據類型或任務的培訓。通過僅根據輸入激活專家的一個相關子集,MOE模型可顯著提高容量,而不會按比例增加計算成本。這種選擇性激活優化了資源使用情況,並可以在自然語言處理,計算機視覺和推薦系統等各個領域跨越複雜的任務。本文探討了MOE模型,其功能,流行示例和Python實施。
本文是數據科學博客馬拉鬆的一部分。
目錄:
什麼是專家(MOE)的混合物?
MOE模型通過使用多個較小的專業模型而不是單個大型模型來增強機器學習。每個較小的型號都以特定的問題類型出色。 “決策者”(門控機制)為每個任務選擇適當的模型,從而提高整體績效。包括變壓器在內的現代深度學習模型使用分層互連的單元(“神經元”)來處理數據並將結果傳遞到後續層。 MOE通過將復雜的問題分為專業組件(“專家”)來反映這一點,每個組件都可以解決特定方面。
MOE模型的關鍵優勢:
MOE模型包括兩個主要部分:專家(專業的較小的神經網絡)和一個路由器(基於輸入的相關專家)。這種選擇性激活提高了效率。
深度學習
在深度學習中,MoE通過分解複雜問題來改善神經網絡性能。它使用多個專門研究不同輸入數據方面的多個較小的“專家”模型,而不是單個大型模型。門控網絡確定每個輸入要使用的專家,從而提高效率和有效性。
MOE模型如何運作?
MOE模型如下:
基於MOE的突出模型
MOE模型在AI中越來越重要,因為它們在保持性能的同時有效地縮放了LLM。 Mixtral 8x7b是一個值得注意的例子,使用了稀疏的MOE架構,僅激活每個輸入的一部分專家,從而導致效率顯著提高。
混合8x7b是僅解碼器的變壓器。輸入令牌嵌入向量中並通過解碼器層進行處理。輸出是每個位置被一個單詞佔據的概率,從而實現文本填充和預測。每個解碼器層都有一個注意機制(用於上下文信息)和專家(SMOE)部分的稀疏混合物(單獨處理每個單詞向量)。 SMOE層使用多個層(“專家”),對於每個輸入,都會使用最相關的專家輸出的加權總和。
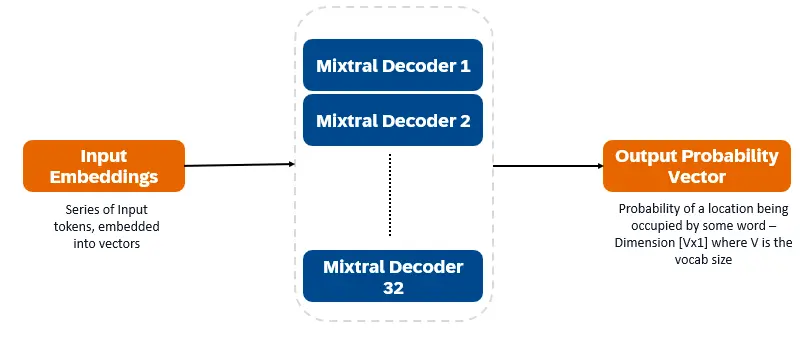
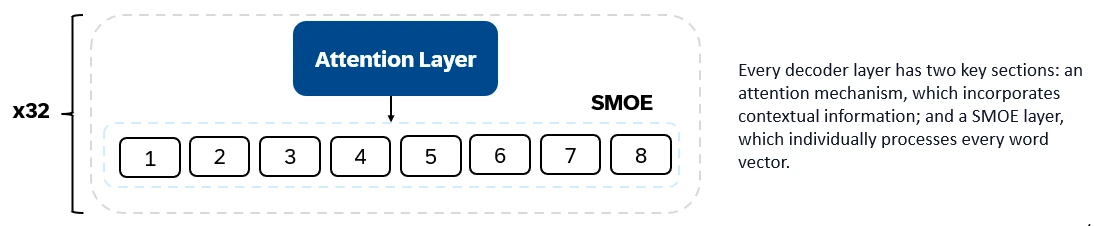
混音8x7b的主要特徵:
混音8x7b在文本生成,理解,翻譯,摘要等方面表現出色。
DBRX(Databricks)是一種基於變壓器的僅解碼器的LLM,該LLM使用下一步的預測訓練。它使用細粒度的MOE架構(132B總參數,36B活動)。它已在文本和代碼數據的12T代幣上進行了預培訓。 DBRX使用許多較小的專家(16位專家,每個輸入選擇4個)。
DBRX的主要體系結構特徵:
DBRX的主要特徵:
DBRX在代碼生成,複雜的語言理解和數學推理方面表現出色。
DeepSeek-V2使用精細的專家和共享專家(始終活躍)來整合普遍知識。
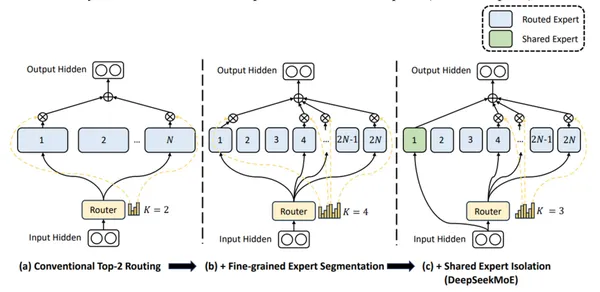
DeepSeek-V2的主要特徵:
DeepSeek-V2擅長對話,內容創建和代碼生成。
(Python實施和輸出比較部分是為了簡短的,因為它們是冗長的代碼示例和詳細的分析。)
常見問題
Q1。專家(MOE)模型的混合物是什麼? A. Moe模型使用稀疏體系結構,僅激活每個任務最相關的專家,從而減少了計算資源的使用。
Q2。 MOE型號的權衡是什麼? A. MOE模型需要重要的VRAM來存儲所有專家,以平衡計算能力和內存要求。
Q3。混合8x7b的主動參數計數是什麼? A.混合8x7b具有128億個活動參數。
Q4。 DBRX與其他MOE模型有何不同? A. DBRX使用較小的專家使用細粒度的MOE方法。
Q5。 DeepSeek-V2有什麼區別? A. DeepSeek-V2結合了細粒度和共享的專家,以及較大的參數集和長上下文長度。
結論
MOE模型為深度學習提供了高效的方法。在需要大量VRAM的同時,他們對專家的選擇性激活使它們成為處理各個領域的複雜任務的強大工具。混合8x7b,dbrx和DeepSeek-V2代表了該領域的重大進步,每個方面都具有自己的優勢和應用。
以上是什麼是專家的混合物?的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















