
這項開創性的調查是2024年2月發布的“大語言模型的數據集:全面調查”,揭示了大型語言模型(LLM)開發的400多個精心分類數據集的寶庫。該資源由楊劉,若恩曹,春朱劉,凱恩和莉安文·金編輯,是研究人員和開發人員的金礦。這不僅僅是靜態收藏;它定期更新,以確保其持續的相關性。
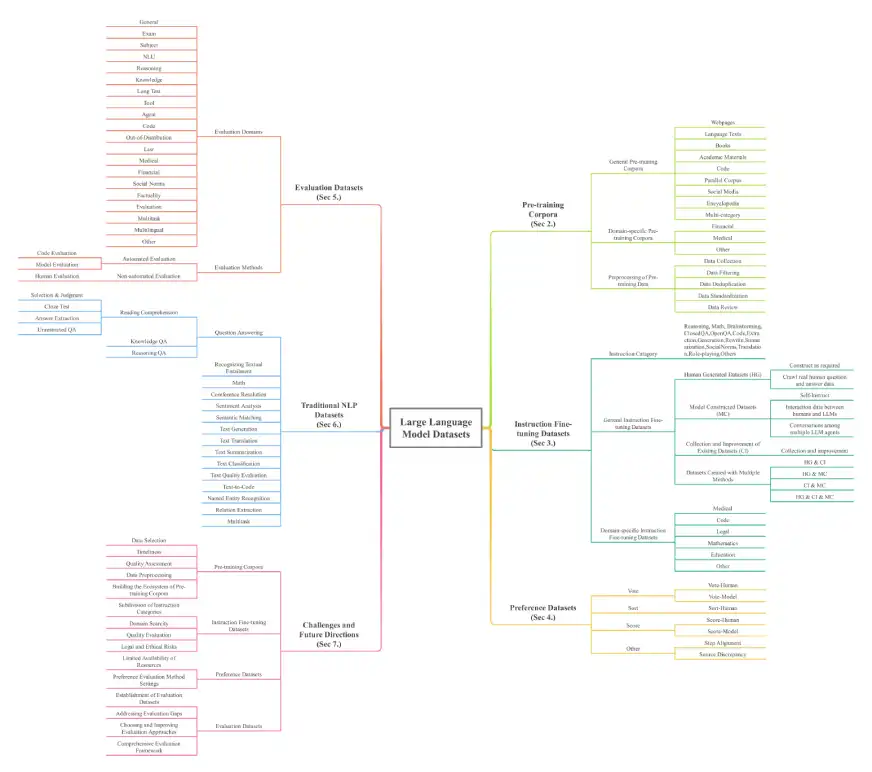
該論文提供了LLM數據集的全面概述,對於理解這些強大模型的基礎至關重要。數據集分為七個關鍵維度:預訓練的語料庫,指令微調數據集,偏好數據集,評估數據集,傳統的NLP數據集,多模式大語言模型(MLLMS)數據集和檢索增強生成(RAG)數據集。純粹的規模令人印象深刻,單獨培訓的數據超過774.5 TB,其他類別的7億個實例,涵蓋了32個域和8種語言。

關鍵數據集類別和示例:
該調查詳細介紹了各種數據集類型,包括:
培訓前語料庫:初始LLM培訓的大量文本收集。示例包括Madlad-400(2.8T代幣),FineWeb(15TB代幣)和BookCorpusopen(17,868本書)。這些進一步分解為一般語料庫(網頁,書籍,語言文本)和特定於領域的語料庫(金融,醫學,數學)。
指令微調數據集:成對的說明和改進模型行為的相應答案。示例包括Databricks-Dolly-15K和羊Alpaca_data。這些也分為一般和域特異性(醫學,代碼)數據集。
偏好數據集:用於通過比較多個響應來評估和改善模型輸出。示例包括chatbot_arena_conversations和HH-RLHF。
評估數據集:專門設計用於在各種任務上基準LLM性能。例子包括山帕卡瓦爾和Bayling-80。
傳統的NLP數據集:用於Pre-LLM NLP任務的數據集。示例包括Boolq,Cosmosqa和PubMedQA。
多模式大型語言模型(MLLMS)數據集:結合文本和其他模式(圖像,視頻)的數據集。示例包括莫斯卡和MMRS-1M。
檢索增強生成(RAG)數據集:具有外部數據檢索功能增強LLM的數據集。例如Crud-rag和Wikival。

資料來源:大型語言模型的數據集:一項全面調查
調查的架構如下所示:
結論和進一步的探索:
這項調查是LLM領域的研究人員和開發人員的重要資源。提供的存儲庫(Awesome-llms-datasets)提供了一個完整的路線圖,用於訪問和利用這些寶貴的數據集。詳細的分類和全面的統計數據使其成為任何使用或研究LLM的人的重要工具。本文還解決了關鍵挑戰,並提出了未來的研究方向。
以上是400個大型語言模型數據集的指南的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















