
該博客文章探討了用於加載大型Pytorch模型的有效內存管理技術,在處理有限的GPU或CPU資源時尤其有益。作者專注於使用torch.save(model.state_dict(), "model.pth")保存模型的方案。儘管示例使用大型語言模型(LLM),但這些技術適用於任何Pytorch模型。
高效模型加載的關鍵策略:
本文詳細介紹了在模型加載過程中優化內存使用量的幾種方法:
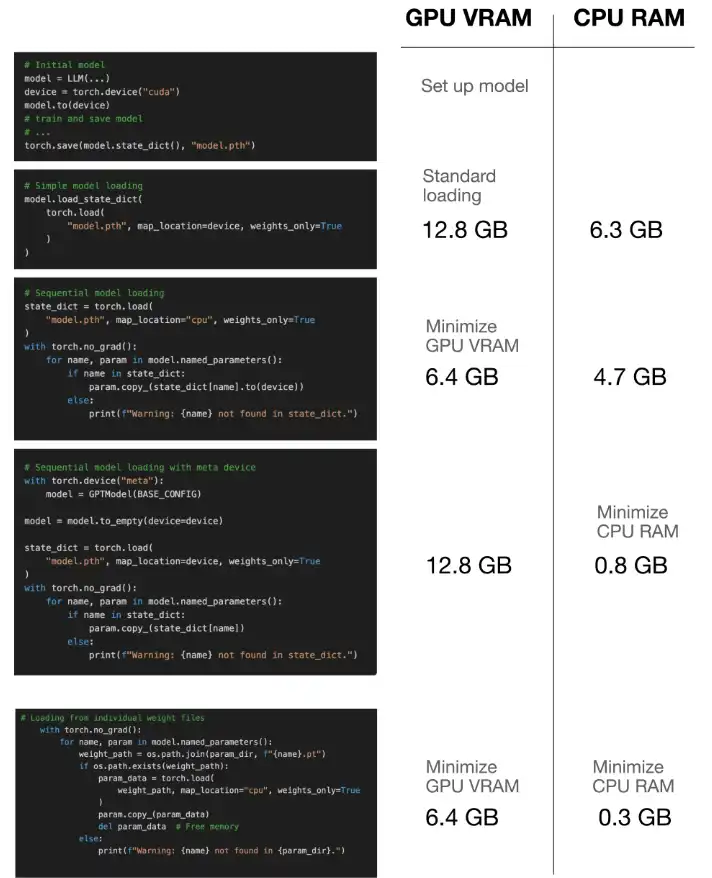
順序的重量加載:此技術將模型體系結構加載到GPU上,然後迭代地將單個權重從CPU存儲器複製到GPU。這樣可以防止GPU內存中同時存在完整模型和權重,從而大大降低了峰值存儲器的消耗。
元設備: Pytorch的“ Meta”設備可實現張量創建,而無需立即內存分配。該模型在元設備上初始化,然後轉移到GPU上,然後將權重直接加載到GPU上,從而最大程度地減少CPU存儲器使用情況。這對於CPU RAM有限的系統特別有用。
mmap=True in torch.load() :此選項使用內存映射的文件I/O,允許Pytorch直接按需磁盤讀取模型數據,而不是將所有內容加載到RAM中。這對於具有有限的CPU內存和快速磁盤I/O的系統是理想的選擇。
個人節省和加載:作為極限資源的最後手段,本文建議將每個模型參數(張量)保存為單獨的文件。然後,加載一次是一個參數,在任何給定時刻最小化內存足跡。這是以增加I/O開銷為代價的。
實際實施和基準測試:
該帖子提供了python代碼段,展示了每種技術,包括用於跟踪GPU和CPU內存使用情況的實用程序功能。這些基准說明了每種方法獲得的內存節省。作者比較每種方法的內存使用量,突出了記憶效率和潛在性能影響之間的權衡。
結論:
本文結束時強調了記憶有效的模型加載的重要性,尤其是對於大型模型。它建議根據特定的硬件限制(CPU RAM,GPU VRAM)和I/O速度選擇最合適的技術。對於有限的CPU RAM, mmap=True方法通常是首選的,而單個重量負載是極度約束環境的最後手段。順序加載方法在許多情況下提供了良好的平衡。
以上是pytorch中的記憶效率重量加載的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















