
Apache冰山:一種現代餐桌格式,用於增強數據湖管理
Apache Iceberg是一種尖端的表格格式,旨在解決傳統蜂巢桌的缺點,提供出色的性能,數據一致性和可擴展性。本文探討了冰山的演變,關鍵特徵(酸性交易,架構進化,時間旅行),建築和與其他桌面格式(如三角洲湖和帕quet)的比較。我們還將研究其與現代數據湖泊的集成及其對大規模數據管理和分析的影響。
Apache Iceberg起源於2017年的Netflix(Ryan Blue和Daniel Weeks的創意),是為了解決蜂巢表格式固有的固有局限性的效果瓶頸,一致性問題和局限性。開源並於2018年捐贈給Apache軟件基金會,迅速獲得了吸引力,吸引了蘋果,AWS和LinkedIn等行業巨頭的貢獻。
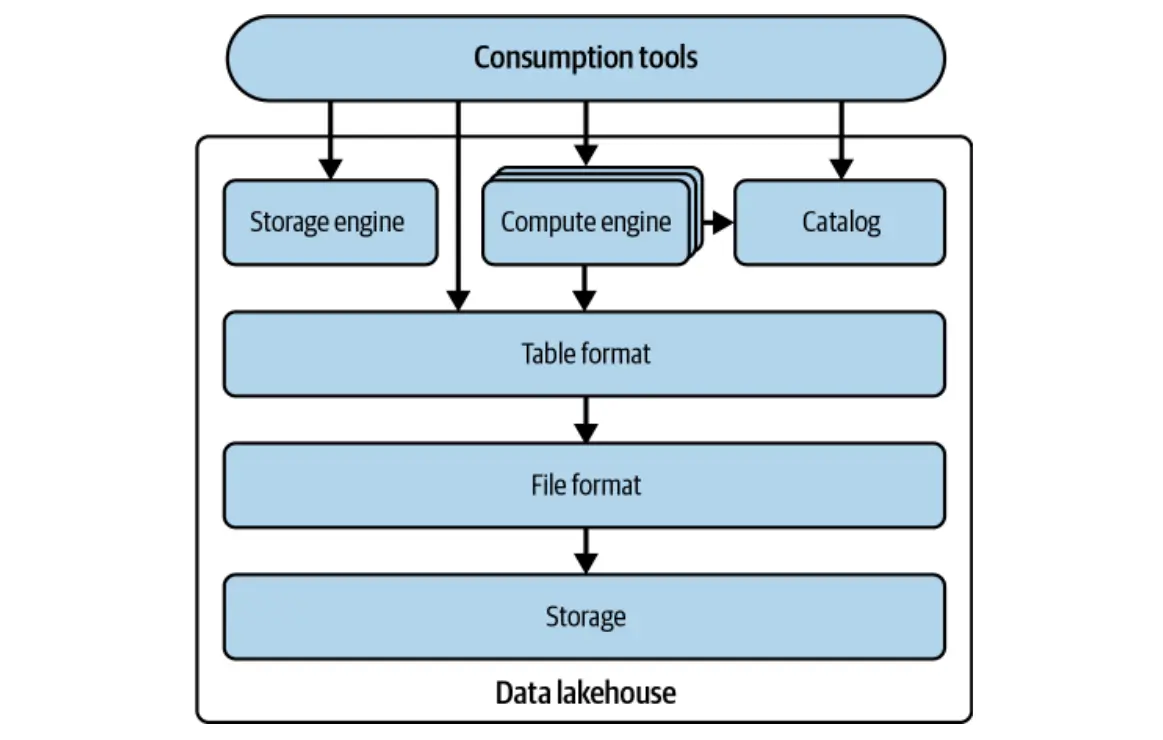
Netflix的經驗強調了Hive的一個危險弱點:它依靠目錄的桌面跟踪。這種方法缺乏穩健一致性,有效並發性以及現代數據倉庫中預期的高級功能所需的粒度。冰山的發展旨在克服這些局限性,重點是:
冰山通過將表作為文件列表而不是目錄來解決這些挑戰。它提供了標準化的格式,該格式定義了多個文件中的元數據結構,並提供了與流行引擎(如Spark和Flink)無縫集成的庫。
冰山的設計優先考慮與現有存儲和計算引擎的兼容性,從而促進了廣泛的採用而沒有發生重大變化。目的是將冰山建立為行業標準,使用戶可以與桌子互動,而不論基本格式如何。現在,許多數據工具提供本地冰山支持。
冰山超越僅解決Hive的局限性;它引入了強大的功能,可增強數據湖和數據湖泊工作量。關鍵功能包括:
冰山使用樂觀的並發控制來確保酸性特性,以確保交易是完全投入或完全卷回去的。這可以最大程度地減少衝突,同時保持數據完整性。
與傳統數據湖不同,冰山可以在不重寫整個桌子的情況下修改分區方案。這樣可以確保有效的查詢優化而不會破壞現有數據。
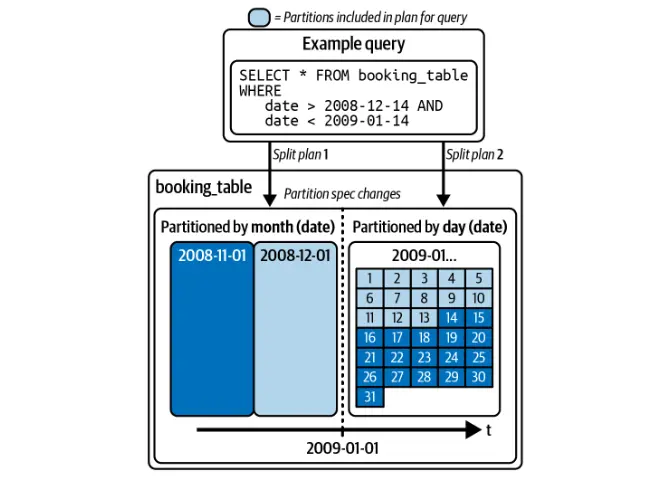
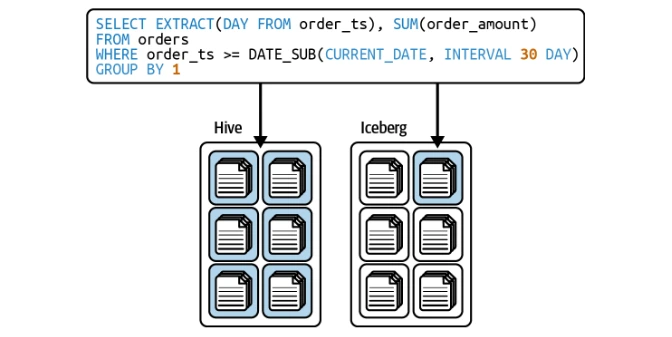
冰山會自動根據分區優化查詢,從而消除了用戶通過分區列手動過濾的需求。
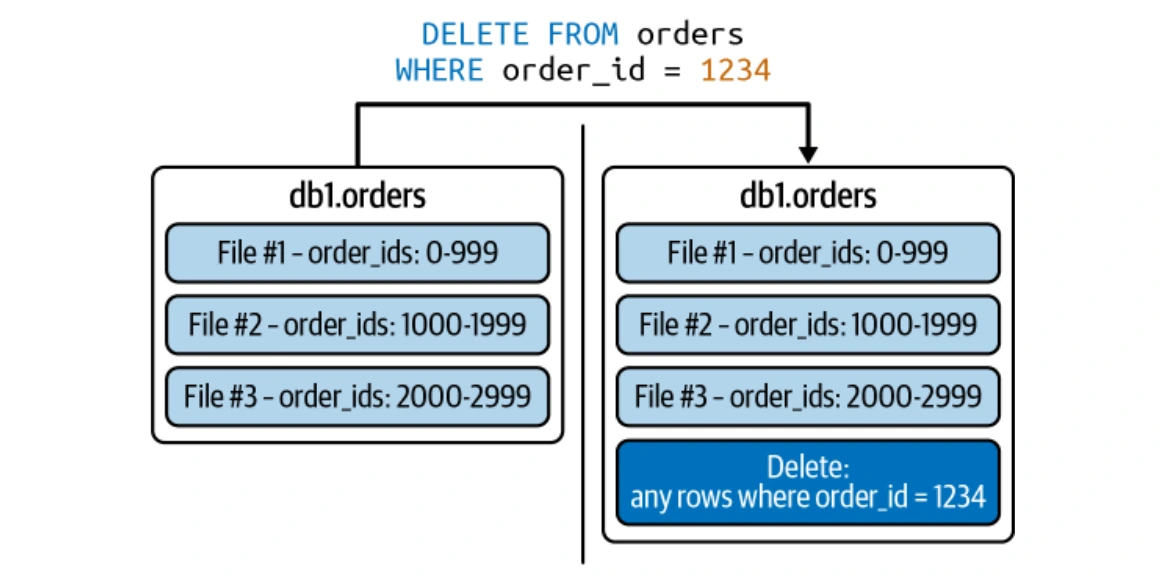
冰山支持有效的行級更新,同時支持抄寫(Cow)和Merge-on-Read(MOR)策略。
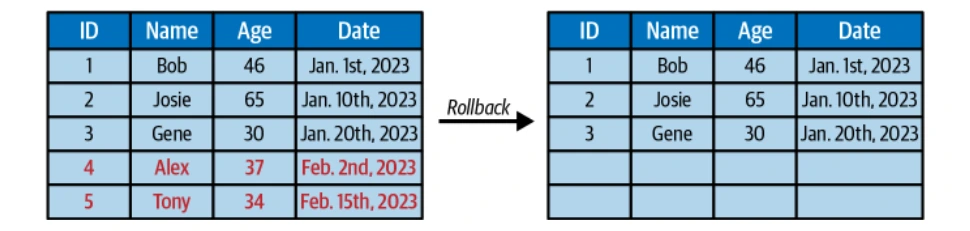
冰山的不變快照使時間旅行查詢以及回到以前的表格狀態的能力。

冰山支持模式修改(添加,刪除或更改列),而無需數據重寫,確保靈活性和兼容性。
本節探討了冰山的建築及其如何克服Hive的局限性。
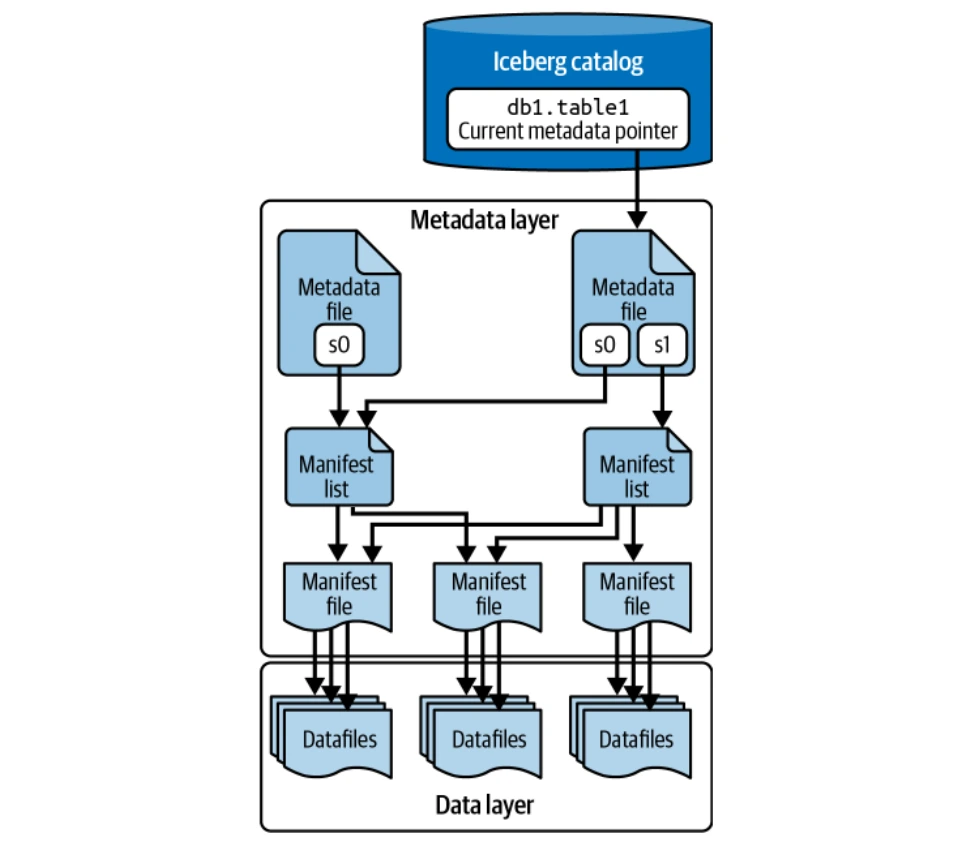
數據層存儲實際的表數據(數據文件和刪除文件)。它託管在分佈式文件系統(HDFS,S3等)上,並支持多個文件格式(Parquet,orc,avro)。對於其柱狀存儲而言,通常首選Parquet。


該層在樹結構中管理所有元數據文件,跟踪數據文件和操作。關鍵組件包括清單文件,清單列表和元數據文件。海雀文件存儲高級統計信息和索引,以進行查詢優化。
該目錄充當中央註冊表,為每個表提供當前元數據文件的位置,確保所有讀者和作家都持續訪問。各種後端可以用作冰山目錄(Hadoop目錄,Hive Metastore,Nessie Catalog,AWS Glue目錄)。
冰山,鑲木木,獸人和三角洲湖經常用於大規模數據處理。冰山將自己作為表格格式區分開,提供交易保證和元數據優化,這與文件格式不同。與三角洲湖相比,冰山在模式和分區進化中出色。
Apache Iceberg為數據湖管理提供了強大,可擴展和用戶友好的方法。它的功能使其成為處理大規模數據的組織的引人注目的解決方案。
Q1。什麼是Apache冰山?答:一種現代的開源表格式,可增強數據湖性能,一致性和可擴展性。
Q2。為什麼需要阿帕奇冰山?答:克服Hive在元數據處理和交易功能中的局限性。
Q3。冰山如何處理模式演變?答:它支持模式更改,而無需全表重寫。
Q4。什麼是冰山的分區進化? A.修改分區方案而無需重寫歷史數據。
Q5。冰山如何支持酸交易?答:通過樂觀的並發控制,確保原子更新。
以上是如何使用Apache冰山表?的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















