
檢索增強的生成(RAG)通過合併外部知識來源可顯著增強大型語言模型(LLM),從而產生更準確和上下文相關的響應。但是,抹布系統並非沒有缺陷,經常產生不准確或無關的輸出。這些限制阻礙了抹佈在各個領域的應用,包括客戶服務,研究和內容創建。了解這些缺點對於開發更可靠的基於檢索的AI至關重要。本文深入研究了RAG失敗背後的原因,並探討了提高破布性能的策略,從而導致更有效,更可擴展的系統。改進的抹布模型有望更一致,高質量的AI輸出。
目錄
什麼是抹布?
抹布或檢索效果的一代是一種複雜的自然語言處理技術,將檢索方法與生成的AI模型相結合,以提供更精確且上下文適當的答案。與僅依靠培訓數據的模型不同,RAG動態訪問外部信息以告知其響應。
關鍵的抹布組件:
了解更多:了解檢索增強發電(RAG)
抹布的局限性
儘管RAG通過合併外部知識,提高準確性和上下文相關性來增強LLM,但它面臨著限制其整體可靠性和有效性的重大挑戰。認識到這些局限性對於開發更健壯的系統至關重要。
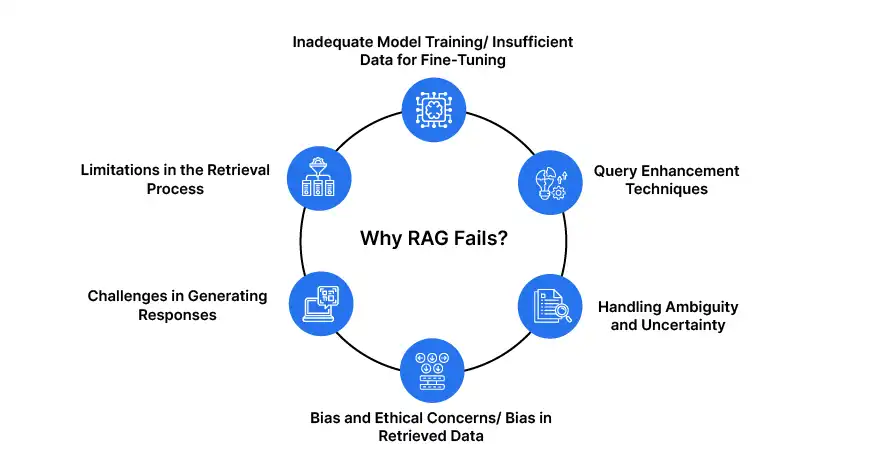
這些限制分為三個主要類別:
通過解決這些問題並實施有針對性的改進,我們可以建立更可靠和有效的抹布系統。
觀看以了解更多信息:解決抹布系統中的現實世界挑戰
(其餘部分詳細詳細介紹了檢索過程故障,生成過程失敗,系統級失敗,結論和常見問題解答將遵循類似的重新繪製和重組模式,並保持原始內容和圖像放置。
以上是為什麼破布失敗以及如何修復?的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















