

建立財務報告檢索系統
Mar 21, 2025 am 10:08 AM財務報告對於評估公司健康至關重要。它們跨越數百頁,因此很難有效提取特定的見解。分析師和投資者花費數小時篩選資產負債表,損益表和腳註只是為了回答簡單的問題,例如 - 2024年公司的收入是多少?隨著LLM模型和向量搜索技術的最新進展,我們可以使用LlamainDex和相關框架自動化財務報告分析。這篇博客文章探討了我們如何使用LlamainDex,Chromadb,Gemini2.0和Ollama來構建一個強大的金融抹布系統,該系統可以從冗長的報告中回答冗長的報告。
學習目標
- 了解對有效分析的財務報告檢索系統的需求。
- 了解如何使用LlamainDex進行預處理和矢量化財務報告。
- 探索Chromadb,用於構建一個可靠的矢量數據庫進行文檔檢索。
- 使用Gemini 2.0和Llama 3.2實施查詢引擎進行財務數據分析。
- 使用LlamainDex來發現高級查詢路由技術,以增強見解。
本文作為數據科學博客馬拉鬆的一部分發表。
目錄
- 為什麼我們需要財務報告檢索系統?
- 項目實施
- 使用LlamainDex處理的文檔
- 用Chromadb構建矢量數據庫
- 使用Gemini 2.0查詢財務數據
- 使用Llama 3.2的本地查詢
- 與LlamainDex的高級查詢路由
- 結論
- 常見問題
為什麼我們需要財務報告檢索系統?
財務報告包含有關公司業績的重要見解,包括收入,費用,負債和盈利能力。但是,這些報告龐大,漫長且充滿了技術術語,使分析師,投資者和高管手動提取相關信息非常耗時。
財務報告檢索系統可以通過啟用自然語言查詢來自動化此過程。用戶可以簡單地提出諸如“ 2023年的收入是什麼? ”或“總結2023年的流動性問題”之類的問題,而不是通過PDF進行搜索。該系統迅速檢索並總結了相關部分,節省了手動工作的時間。
項目實施
對於項目實施,我們需要首先設置環境並安裝所需的庫:
步驟1:設置環境
我們將首先為我們的開發工作創建和Conda Env。
1 2 3 |
|
步驟2:安裝必需的Python庫
安裝圖書館是任何項目實施的關鍵步驟:
1 2 3 4 |
|
步驟3:創建項目目錄
現在,創建一個項目目錄並創建一個名為.env的文件,然後在該文件上放置了所有API鍵,以進行安全的API密鑰管理。
1 2 3 |
|
我們加載來自該.ENV文件的環境變量以安全地存儲敏感的API密鑰。這樣可以確保我們的雙子座API或Google API仍然受到保護。
我們將使用Jupyter筆記本進行項目。
創建一個Jupyter筆記本文件,然後逐步開始實現。
步驟4:加載API鍵
現在,我們將在下面加載API密鑰:
1 2 3 4 5 6 7 8 9 |
|
現在,我們的環境準備就緒,因此我們可以進入下一個最重要的階段。
使用LlamainDex處理的文檔
從年度報告網站收集Motorsport Games Inc.財務報告。
在此處下載鏈接。
第一頁看起來像:

該報告總共有123頁,但我只是採用了報告的財務報表,並為我們的項目創建了新的PDF。
我怎麼做? PYPDF庫非常容易。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
新報告文件只有38頁,這將幫助我們快速嵌入文檔。
加載和拆分財務報告
在您的項目數據目錄中,放置您的新創建的Motorsport_games_financial_report.pdf文件,該文件將為該項目索引。
財務報告通常採用PDF格式,其中包含廣泛的表格數據,腳註和法律聲明。我們使用LlamainDex的SimpleDirectoryReader加載這些文檔並將其轉換為文檔。
1 2 3 |
|
由於報告作為單個文檔非常大,因此我們將其拖入較小的塊或節點。每個塊對應於頁面或部分,它有助於更有效地檢索。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
要了解文檔攝入的過程,請參見下圖。

現在,我們的財務數據已準備好進行矢量化和存儲以進行檢索。
用Chromadb構建矢量數據庫
我們將使用Chromadb進行快速,準確和本地矢量數據庫。我們嵌入的財務文本表示形式將存儲在Chromadb中。
我們初始化了矢量數據庫,並使用Ollama進行局部嵌入生成的配置,並配置提名 - embed-Text模型。
1 2 3 4 5 6 7 8 9 10 11 12 |
|
最後,我們使用LlamainDex的VectorStoreIndex創建了一個向量索引。該索引將我們的矢量數據庫與LlamainDex的查詢引擎聯繫起來。
1 2 3 4 |
|
上面的代碼將使用財務文本文檔中的提名 - 內容文本創建矢量索引。這將需要時間,具體取決於您的本地系統規範。
完成索引後,您可以使用代碼在必要時嵌入無需重新索引的代碼。
1 2 3 |
|
這將允許您使用存儲中的Chromadb嵌入文件。
現在,我們已經完成了重負荷,是時候查詢報告並放鬆了。
使用Gemini 2.0查詢財務數據
一旦我們的財務數據索引,我們就可以提出自然語言問題並獲得準確的答案。為了查詢,我們將使用與矢量數據庫進行交互的Gemini-2.0 Flash模型來獲取相關部分並生成洞察響應。
設置Gemini-2.0
1 2 3 |
|
使用Gemini 2.0與矢量索引啟動查詢引擎
1 |
|
Exa mple疑問和回應
下面我們有多個疑問,有不同的響應:
查詢1
1 2 3 |
|
回覆

報告中的相應圖像:

查詢2
1 2 3 4 5 |
|
回覆

報告中的相應圖像:

查詢3
1 2 3 4 5 |
|
回覆

查詢4
1 2 3 4 5 |
|
回覆

從報告中對照圖像:

查詢5
1 2 3 4 5 |
|
回覆

從報告中對照圖像:

查詢6
1 2 3 4 5 |
|
回覆

報告中的相應圖像:

查詢7
1 2 3 4 5 |
|
回覆

查詢8
1 2 3 4 5 |
|
回覆

報告中的相應圖像:

使用Llama 3.2的本地查詢
利用美洲駝3.2在本地查詢財務報告,而無需依賴基於雲的模型。
設置美洲駝3.2:1b
1 2 |
|
查詢9
1 2 3 4 5 |
|
回覆

從報告中對照圖像:

與LlamainDex的高級查詢路由
有時,我們需要詳細的檢索和總結的見解。我們可以通過組合向量索引和摘要索引來做到這一點。
- 精確文檔檢索的向量索引
- 簡明財務摘要的摘要索引
我們已經構建了矢量索引,現在我們將創建一個摘要索引,該索引使用層次結構方法來匯總財務報表。
1 2 3 |
|
然後集成RouterqueryEngine,該RouterqueryEngine可以根據查詢類型有條件地決定是否從摘要索引或向量索引檢索數據。
1 2 3 |
|
現在創建摘要查詢引擎
1 2 3 |
|
該摘要查詢引擎進入摘要工具。向量查詢引擎進入矢量工具。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
現在完成了兩個工具,我們通過路由器連接這些工具,因此當通過路由器查詢屁股時,它將決定通過分析用戶查詢使用哪種工具。
1 2 3 4 5 6 7 8 |
|
我們的高級查詢系統已完全設置,現在查詢我們新偏愛的高級查詢引擎。
查詢10
1 2 3 4 |
|
回覆

您可以看到我們的智能路由器會決定使用摘要工具,因為在查詢用戶中要求摘要。
查詢11
1 2 |
|
回覆

在這裡,路由器選擇向量工具,因為用戶要求提供特定信息,而不是摘要。
本文中使用的所有代碼都在這裡
結論
我們可以通過LlamainDex,Chromadb和Advanced LLM有效分析財務報告。該系統可實現自動財務見解,實時查詢和強大的摘要。這種類型的系統使財務分析在投資,交易和開展業務期間更容易獲得和有效地做出更好的決策。
關鍵要點
- LLM動力文件檢索系統可以大大減少分析複雜財務報告所花費的時間。
- 使用雲和本地LLM的混合方法確保了一種成本效益,隱私和設計系統的靈活方法。
- LlamainDex的模塊化框架提供了一種簡單的方法來自動化財務報告抹布工作流程
- 可以將這種類型的系統適用於不同領域,例如法律文檔,醫療報告和監管文件,這使其成為一種多功能的破布解決方案。
常見問題
問1。系統如何處理不同的財務報告?答:該系統旨在通過將其分解成文本塊,嵌入並將其存儲在Chromadb中來處理任何結構化的財務文件。可以動態添加新報告,而無需完整的重新索引。
問2。是否可以擴展以生成財務圖表和可視化?答:是的,通過整合matplotlib,pandas和簡化,您可以看到諸如收入增長,淨虧損分析或資產分配等趨勢。
Q3。查詢路由系統如何提高準確性?答:RouterqueryEngine自動檢測查詢是否需要匯總響應或特定的財務數據檢索。這樣可以減少無關緊要的輸出並確保響應的精度。
問4。在此系統中,適合實時財務分析?答:可以,但這取決於矢量存儲的更新的頻率。您可以使用OpenAI嵌入API進行連續攝入管道,以動態地進行實時財務報告查詢。
本文所示的媒體不由Analytics Vidhya擁有,並由作者酌情使用。
以上是建立財務報告檢索系統的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱門文章
熱門文章
熱門文章標籤

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)






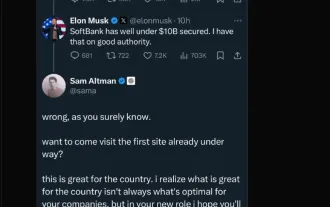 Elon Musk&Sam Altman衝突超過5000億美元的星際之門項目
Mar 08, 2025 am 11:15 AM
Elon Musk&Sam Altman衝突超過5000億美元的星際之門項目
Mar 08, 2025 am 11:15 AM
Elon Musk&Sam Altman衝突超過5000億美元的星際之門項目



