

將文本文檔轉換為帶有TFIDFECTORIZER的TF-IDF矩陣

本文解釋了術語“頻率分析”頻率(TF-IDF)技術,這是一種自然語言處理(NLP)的關鍵工具,用於分析文本數據。 TF-IDF通過基於文檔中的頻率加權術語來超越基本單詞袋方法的局限性,並在文檔集合中稀有。這種增強的權重改善了文本分類,並提高了機器學習模型的分析能力。我們將演示如何從Python中從頭開始構建TF-IDF模型並執行數值計算。
目錄
- TF-IDF中的關鍵術語
- 解釋的術語頻率(TF)
- 文檔頻率(DF)解釋了
- 逆文件頻率(IDF)解釋了
- 了解TF-IDF
- 數值TF-IDF計算
- 步驟1:計算術語頻率(TF)
- 步驟2:計算逆文檔頻率(IDF)
- 步驟3:計算TF-IDF
- 使用內置數據集實現Python
- 步驟1:安裝必要的庫
- 步驟2:導入庫
- 步驟3:加載數據集
- 步驟4:初始化
TfidfVectorizer - 步驟5:安裝和轉換文檔
- 步驟6:檢查TF-IDF矩陣
- 結論
- 常見問題
TF-IDF中的關鍵術語
在繼續之前,讓我們定義關鍵術語:
- t :術語(單詞)
- D :文檔(一組單詞)
- N :語料庫中的文檔總數
- 語料庫:整個文檔集合
解釋的術語頻率(TF)
術語頻率(TF)量化特定文檔中一個項出現的頻率。更高的TF表明該文檔中的重要性更大。公式是:
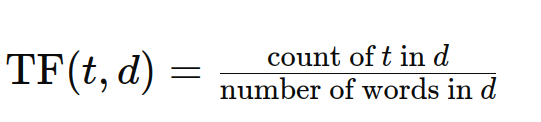
文檔頻率(DF)解釋了
文檔頻率(DF)測量包含特定術語的語料庫中的文檔數量。與TF不同,它計算出一個術語的存在,而不是其出現。公式是:
df(t)=包含術語t的文檔數量
逆文件頻率(IDF)解釋了
逆文檔頻率(IDF)評估單詞的信息性。雖然TF平等地對待所有術語,但IDF會減小常用單詞(例如停止單詞)和上級稀有術語。公式是:
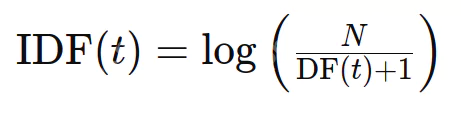
其中n是文檔總數,而df(t)是包含術語t的文檔數量。
了解TF-IDF
TF-IDF結合了項頻率和反向文檔頻率,以確定文檔中相對於整個語料庫的術語意義。公式是:
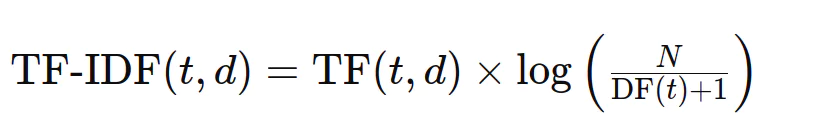
數值TF-IDF計算
讓我們用示例文檔說明數值TF-IDF計算:
文件:
- “天空是藍色的。”
- “今天的陽光很燦爛。”
- “天空中的陽光很燦爛。”
- “我們可以看到閃閃發光的陽光,燦爛的陽光。”
按照原始文本中概述的步驟,我們計算每個文檔中每個術語的TF,IDF,然後計算TF-IDF。 (此處省略了詳細的計算,但它們反映了原始示例。)
使用內置數據集實現Python
本節將使用Scikit-Learn的TfidfVectorizer和20個新聞組數據集進行了TF-IDF計算。
步驟1:安裝必要的庫
PIP安裝Scikit-Learn
步驟2:導入庫
導入大熊貓作為pd 來自sklearn.datasets import fetch_20newsgroups 來自sklearn.feature_extraction.text導入tfidfvectorizer
步驟3:加載數據集
newsgroups = fetch_20newsgroups(subset ='train')
步驟4:初始化TfidfVectorizer
vectorizer = tfidfvectorizer(stop_words ='英語',max_features = 1000)
步驟5:安裝和轉換文檔
tfidf_matrix = vectorizer.fit_transform(newsgroups.data)
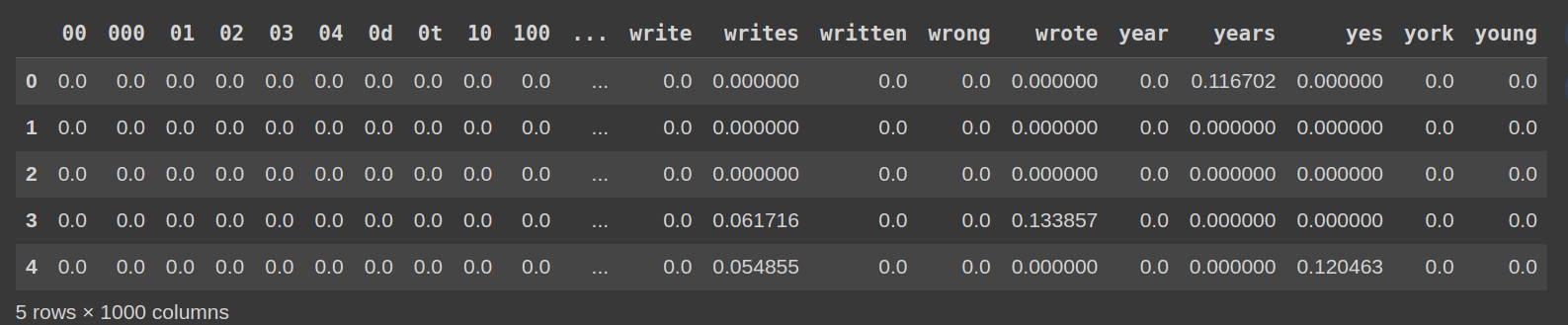
步驟6:檢查TF-IDF矩陣
df_tfidf = pd.dataframe(tfidf_matrix.toArray(),columns = vectorizer.get_feature_names_out()) df_tfidf.head()
結論
使用20個新聞組數據集和TfidfVectorizer ,我們有效地將文本文檔轉換為TF-IDF矩陣。該矩陣表示每個術語的重要性,從而實現了各種NLP任務,例如文本分類和聚類。 Scikit-Learn的TfidfVectorizer顯著簡化了這一過程。
常見問題
常見問題解答部分在很大程度上保持不變,解決了IDF的對數性質,對大數據集的可擴展性,TF-IDF的局限性(忽略單詞順序和上下文)以及常見的應用程序(搜索引擎,文本分類,群集,群集,摘要)。
以上是將文本文檔轉換為帶有TFIDFECTORIZER的TF-IDF矩陣的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 開始使用Meta Llama 3.2 -Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
開始使用Meta Llama 3.2 -Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta的Llama 3.2:多模式和移動AI的飛躍 Meta最近公佈了Llama 3.2,這是AI的重大進步,具有強大的視覺功能和針對移動設備優化的輕量級文本模型。 以成功為基礎
 10個生成AI編碼擴展,在VS代碼中,您必須探索
Apr 13, 2025 am 01:14 AM
10個生成AI編碼擴展,在VS代碼中,您必須探索
Apr 13, 2025 am 01:14 AM
嘿,編碼忍者!您當天計劃哪些與編碼有關的任務?在您進一步研究此博客之前,我希望您考慮所有與編碼相關的困境,這是將其列出的。 完畢? - 讓&#8217
 AV字節:Meta' llama 3.2,Google的雙子座1.5等
Apr 11, 2025 pm 12:01 PM
AV字節:Meta' llama 3.2,Google的雙子座1.5等
Apr 11, 2025 pm 12:01 PM
本週的AI景觀:進步,道德考慮和監管辯論的旋風。 OpenAI,Google,Meta和Microsoft等主要參與者已經釋放了一系列更新,從開創性的新車型到LE的關鍵轉變
 向員工出售AI策略:Shopify首席執行官的宣言
Apr 10, 2025 am 11:19 AM
向員工出售AI策略:Shopify首席執行官的宣言
Apr 10, 2025 am 11:19 AM
Shopify首席執行官TobiLütke最近的備忘錄大膽地宣布AI對每位員工的基本期望是公司內部的重大文化轉變。 這不是短暫的趨勢。這是整合到P中的新操作範式
 視覺語言模型(VLMS)的綜合指南
Apr 12, 2025 am 11:58 AM
視覺語言模型(VLMS)的綜合指南
Apr 12, 2025 am 11:58 AM
介紹 想像一下,穿過美術館,周圍是生動的繪畫和雕塑。現在,如果您可以向每一部分提出一個問題並獲得有意義的答案,該怎麼辦?您可能會問:“您在講什麼故事?
 GPT-4O vs OpenAI O1:新的Openai模型值得炒作嗎?
Apr 13, 2025 am 10:18 AM
GPT-4O vs OpenAI O1:新的Openai模型值得炒作嗎?
Apr 13, 2025 am 10:18 AM
介紹 Openai已根據備受期待的“草莓”建築發布了其新模型。這種稱為O1的創新模型增強了推理能力,使其可以通過問題進行思考
 閱讀AI索引2025:AI是您的朋友,敵人還是副駕駛?
Apr 11, 2025 pm 12:13 PM
閱讀AI索引2025:AI是您的朋友,敵人還是副駕駛?
Apr 11, 2025 pm 12:13 PM
斯坦福大學以人為本人工智能研究所發布的《2025年人工智能指數報告》對正在進行的人工智能革命進行了很好的概述。讓我們用四個簡單的概念來解讀它:認知(了解正在發生的事情)、欣賞(看到好處)、接納(面對挑戰)和責任(弄清我們的責任)。 認知:人工智能無處不在,並且發展迅速 我們需要敏銳地意識到人工智能發展和傳播的速度有多快。人工智能係統正在不斷改進,在數學和復雜思維測試中取得了優異的成績,而就在一年前,它們還在這些測試中慘敗。想像一下,人工智能解決複雜的編碼問題或研究生水平的科學問題——自2023年
 3種運行Llama 3.2的方法-Analytics Vidhya
Apr 11, 2025 am 11:56 AM
3種運行Llama 3.2的方法-Analytics Vidhya
Apr 11, 2025 am 11:56 AM
Meta's Llama 3.2:多式聯運AI強力 Meta的最新多模式模型Llama 3.2代表了AI的重大進步,具有增強的語言理解力,提高的準確性和出色的文本生成能力。 它的能力t
