

正则匹配 模式修正符 小写u的有关问题 php

正则匹配 模式修正符 小写u的问题 php
最近看到一段代码:
<br /><?php<br />$str = '你好,世界dd';<br />preg_match_all('/./us', $str, $match);<br />echo count($match[0])."<br />"; <br />?><br />上网查了不少资料,但对于php正则表达式中的模式修正符u实在有些不明白,求解啊……

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 解決方法:您的組織要求您更改 PIN 碼
Oct 04, 2023 pm 05:45 PM
解決方法:您的組織要求您更改 PIN 碼
Oct 04, 2023 pm 05:45 PM
「你的組織要求你更改PIN訊息」將顯示在登入畫面上。當在使用基於組織的帳戶設定的電腦上達到PIN過期限制時,就會發生這種情況,在該電腦上,他們可以控制個人設備。但是,如果您使用個人帳戶設定了Windows,則理想情況下不應顯示錯誤訊息。雖然情況並非總是如此。大多數遇到錯誤的使用者使用個人帳戶報告。為什麼我的組織要求我在Windows11上更改我的PIN?可能是您的帳戶與組織相關聯,您的主要方法應該是驗證這一點。聯絡網域管理員會有所幫助!此外,配置錯誤的本機原則設定或不正確的登錄項目也可能導致錯誤。即
 Windows 11 上調整視窗邊框設定的方法:變更顏色和大小
Sep 22, 2023 am 11:37 AM
Windows 11 上調整視窗邊框設定的方法:變更顏色和大小
Sep 22, 2023 am 11:37 AM
Windows11將清新優雅的設計帶到了最前沿;現代介面可讓您個性化和更改最精細的細節,例如視窗邊框。在本指南中,我們將討論逐步說明,以協助您在Windows作業系統中建立反映您的風格的環境。如何更改視窗邊框設定?按+開啟“設定”應用程式。 WindowsI前往個人化,然後按一下顏色設定。顏色變更視窗邊框設定視窗11「寬度=」643「高度=」500「>找到在標題列和視窗邊框上顯示強調色選項,然後切換它旁邊的開關。若要在「開始」功能表和工作列上顯示主題色,請開啟「在開始」功能表和工作列上顯示主題
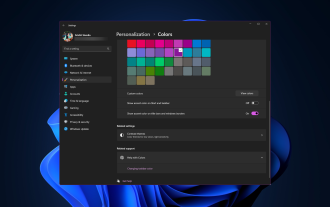 如何在 Windows 11 上變更標題列顏色?
Sep 14, 2023 pm 03:33 PM
如何在 Windows 11 上變更標題列顏色?
Sep 14, 2023 pm 03:33 PM
預設情況下,Windows11上的標題列顏色取決於您選擇的深色/淺色主題。但是,您可以將其變更為所需的任何顏色。在本指南中,我們將討論三種方法的逐步說明,以更改它並個性化您的桌面體驗,使其具有視覺吸引力。是否可以更改活動和非活動視窗的標題列顏色?是的,您可以使用「設定」套用變更活動視窗的標題列顏色,也可以使用登錄編輯程式變更非活動視窗的標題列顏色。若要了解這些步驟,請前往下一部分。如何在Windows11中變更標題列的顏色? 1.使用「設定」應用程式按+開啟設定視窗。 WindowsI前往“個人化”,然
 Windows 11 上啟用或停用工作列縮圖預覽的方法
Sep 15, 2023 pm 03:57 PM
Windows 11 上啟用或停用工作列縮圖預覽的方法
Sep 15, 2023 pm 03:57 PM
工作列縮圖可能很有趣,但它們也可能分散注意力或煩人。考慮到您將滑鼠懸停在該區域的頻率,您可能無意中關閉了重要視窗幾次。另一個缺點是它使用更多的系統資源,因此,如果您一直在尋找一種提高資源效率的方法,我們將向您展示如何停用它。不過,如果您的硬體規格可以處理它並且您喜歡預覽版,則可以啟用它。如何在Windows11中啟用工作列縮圖預覽? 1.使用「設定」應用程式點擊鍵並點選設定。 Windows按一下系統,然後選擇關於。點選高級系統設定。導航至“進階”選項卡,然後選擇“效能”下的“設定”。在「視覺效果」選
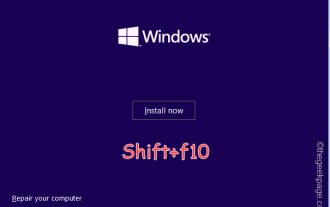 OOBELANGUAGE錯誤Windows 11 / 10修復中出現問題的問題
Jul 16, 2023 pm 03:29 PM
OOBELANGUAGE錯誤Windows 11 / 10修復中出現問題的問題
Jul 16, 2023 pm 03:29 PM
您是否在Windows安裝程式頁面上看到「出現問題」以及「OOBELANGUAGE」語句? Windows的安裝有時會因此類錯誤而停止。 OOBE表示開箱即用的體驗。正如錯誤提示所表示的那樣,這是與OOBE語言選擇相關的問題。沒有什麼好擔心的,你可以透過OOBE螢幕本身的漂亮註冊表編輯來解決這個問題。快速修復–1.點選OOBE應用底部的「重試」按鈕。這將繼續進行該過程,而不會再打嗝。 2.使用電源按鈕強制關閉系統。系統重新啟動後,OOBE應繼續。 3.斷開系統與網際網路的連接。在脫機模式下完成OOBE的所
 Windows 11 上的顯示縮放比例調整指南
Sep 19, 2023 pm 06:45 PM
Windows 11 上的顯示縮放比例調整指南
Sep 19, 2023 pm 06:45 PM
在Windows11上的顯示縮放方面,我們都有不同的偏好。有些人喜歡大圖標,有些人喜歡小圖標。但是,我們都同意擁有正確的縮放比例很重要。字體縮放不良或圖像過度縮放可能是工作時真正的生產力殺手,因此您需要知道如何自訂以充分利用系統功能。自訂縮放的優點:對於難以閱讀螢幕上的文字的人來說,這是一個有用的功能。它可以幫助您一次在螢幕上查看更多內容。您可以建立僅適用於某些監視器和應用程式的自訂擴充功能設定檔。可以幫助提高低階硬體的效能。它使您可以更好地控制螢幕上的內容。如何在Windows11
 10種在 Windows 11 上調整亮度的方法
Dec 18, 2023 pm 02:21 PM
10種在 Windows 11 上調整亮度的方法
Dec 18, 2023 pm 02:21 PM
螢幕亮度是使用現代計算設備不可或缺的一部分,尤其是當您長時間注視螢幕時。它可以幫助您減輕眼睛疲勞,提高易讀性,並輕鬆有效地查看內容。但是,根據您的設置,有時很難管理亮度,尤其是在具有新UI更改的Windows11上。如果您在調整亮度時遇到問題,以下是在Windows11上管理亮度的所有方法。如何在Windows11上變更亮度[10種方式解釋]單一顯示器使用者可以使用下列方法在Windows11上調整亮度。這包括使用單一顯示器的桌上型電腦系統以及筆記型電腦。讓我們開始吧。方法1:使用操作中心操作中心是訪問
 華為GT3 Pro和GT4的差異是什麼?
Dec 29, 2023 pm 02:27 PM
華為GT3 Pro和GT4的差異是什麼?
Dec 29, 2023 pm 02:27 PM
許多用戶在選擇智慧型手錶的時候都會選擇的華為的品牌,其中華為GT3pro和GT4都是非常熱門的選擇,不少用戶都很好奇華為GT3pro和GT4有什麼區別,下面就給大家介紹一下二者。華為GT3pro和GT4有什麼差別一、外觀GT4:46mm和41mm,材質是玻璃鏡板+不鏽鋼機身+高分纖維後殼。 GT3pro:46.6mm和42.9mm,材質是藍寶石玻璃鏡+鈦金屬機身/陶瓷機身+陶瓷後殼二、健康GT4:採用最新的華為Truseen5.5+演算法,結果會更加的精準。 GT3pro:多了ECG心電圖和血管及安
