

Python编码爬坑指南(必看)

自己最近有在学习python,这实在是一门非常短小精悍的语言,很喜欢这种语言精悍背后又有强大函数库支撑的语言。可是刚接触不久就遇到了让人头疼的关于编码的问题,在网上查了很多资料现在在这里做一番总结,权当一个记录也为后来的兄弟姐妹们服务,如果可以让您少走一些弯路本人将倍感荣幸。
先来描述下现象吧:
import os
for i in os.listdir("E:\Torchlight II"):
print i代码很简单我们使用os的listdir函数遍历了E:\Torchlight II这个目录(Torchlight ?! :)),由于这个目录下有些文件是以中文命名的,所以在最后print结果时出现了乱码,像这样:
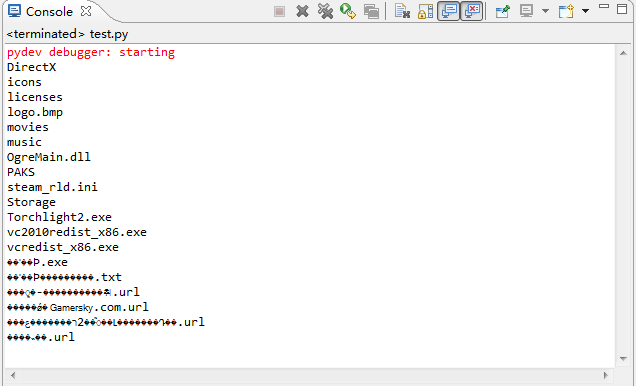
那么问题出在哪儿呢? 别急,我们一点一点来分析它。
从这里和这里我们几乎能够肯定的知道问题是出在:
This means that the python console app can't write the given character to the console's encoding. More specifically, the python console app created a _io.TextIOWrapperd instance with an encoding that cannot represent the given character. sys.stdout --> _io.TextIOWrapperd --> (your console)
看到这里不知你是否与我想的一样,能不能去设置console的编码,将其设置为能够理解中文字符的编码不就可以正常的显示出中文了吗?等等,让我们在多Google一会儿,
Python determines the encoding of stdout and stderr based on the value of the LC_CTYPE variable, but only if the stdout is a tty. So if I just output to the terminal, LC_CTYPE (or LC_ALL) define the encoding. However, when the output is piped to a file or to a different process, the encoding is not defined, and defaults to 7-bit ASCII.
更详细的说明如下:
1). When Python finds its output attached to a terminal, it sets the sys.stdout.encoding attribute to the terminal's encoding. The print statement's handler will automatically encode unicode arguments into str output. 2). When Python does not detect the desired character set of the output, it sets sys.stdout.encoding to None, and print will invoke the "ascii" codec.
嚯嚯,看来刚才的想法是可行的只是不太优雅罢了,因为我们得去修改系统的设置。事实上上面的论述是基于linux环境的,在linux下可能需要我们去更改某个环境变量的值(LC_CTYPE or LANG);如果我们是在windows下面的话,console的编码设置是跟操作系统的区域设置相关的。比如在中文的win7环境下,console默认的编码就是GBK(cp936)。你可以试试下面的代码:
import locale print locale.getdefaultlocale()[1]
console的编码不好设置了那能否对stdout.out.encoding进行设置以达到我们的目的呢?很遗憾,答案是否定的,这家伙压根就是只读的:

没有办法了么?不会,其实我们离成功已经很近了,来,根据上面检索到的那些资料分析整理下看看我们现在掌握到的情况都有哪些:
1). console不能正常显示中文,console的编码是由操作系统决定的(windows环境下); 2). 我的操作系统是win7中文版(GBK),enc = locale.getdefaultlocale()[1]; 3). console的编码决定了sys.stdout.encoding的取值,sys.stdout.encoding = utf-8; 4). 从操作系统枚举目录(E:\Torchlight II)列表返回的字符串也是GBK编码
是不是已经看出问题来了。最上面截图中那么奇奇怪怪的问号尖角符号就是因为字符串本身是按照gbk进行编码的,但是由于sys.stdout.encoding = utf-8,导致print会按照utf-8对input的数据进行encode从而转换为unicode字符。这,当然错误了。原因已经清楚了,来改改代码吧:
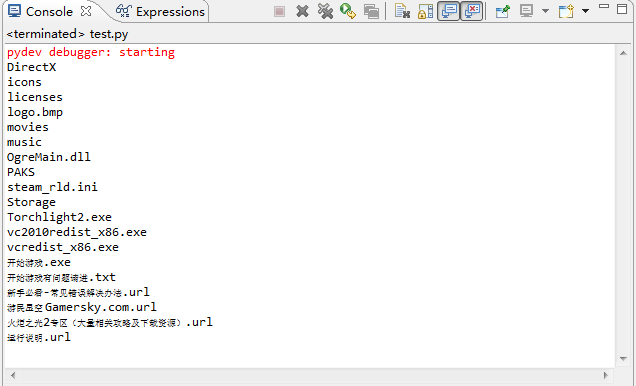
import os
for i in os.listdir("E:\Torchlight II"):
print i.decode('gbk')在代码中我们手动告诉了python对读入的字符串按章gbk编码来进行解码,而这一个动作之后数据已经是标准的unicode字符了,可以放心的交给print去打印输出了(即使这会儿sys.stdout.encoding = utf-8):
ps:
实际在google中还查到过很多相关的类似编码的问题,比如这里的,还有这里的。虽然问题的样子千变万化并且解决方式多种多样甚至是python自己的特定解决方式,比如这里。但这些问题本质都是一样的都是关于字符的编码和解码,搞清楚了其中的本质所有问题都能够迎刃而解。
以上这篇Python编码爬坑指南(必看)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 如何解決Linux終端中查看Python版本時遇到的權限問題?
Apr 01, 2025 pm 05:09 PM
如何解決Linux終端中查看Python版本時遇到的權限問題?
Apr 01, 2025 pm 05:09 PM
Linux終端中查看Python版本時遇到權限問題的解決方法當你在Linux終端中嘗試查看Python的版本時,輸入python...
 如何在使用 Fiddler Everywhere 進行中間人讀取時避免被瀏覽器檢測到?
Apr 02, 2025 am 07:15 AM
如何在使用 Fiddler Everywhere 進行中間人讀取時避免被瀏覽器檢測到?
Apr 02, 2025 am 07:15 AM
使用FiddlerEverywhere進行中間人讀取時如何避免被檢測到當你使用FiddlerEverywhere...
 在Python中如何高效地將一個DataFrame的整列複製到另一個結構不同的DataFrame中?
Apr 01, 2025 pm 11:15 PM
在Python中如何高效地將一個DataFrame的整列複製到另一個結構不同的DataFrame中?
Apr 01, 2025 pm 11:15 PM
在使用Python的pandas庫時,如何在兩個結構不同的DataFrame之間進行整列複製是一個常見的問題。假設我們有兩個Dat...
 Uvicorn是如何在沒有serve_forever()的情況下持續監聽HTTP請求的?
Apr 01, 2025 pm 10:51 PM
Uvicorn是如何在沒有serve_forever()的情況下持續監聽HTTP請求的?
Apr 01, 2025 pm 10:51 PM
Uvicorn是如何持續監聽HTTP請求的? Uvicorn是一個基於ASGI的輕量級Web服務器,其核心功能之一便是監聽HTTP請求並進�...
 如何在10小時內通過項目和問題驅動的方式教計算機小白編程基礎?
Apr 02, 2025 am 07:18 AM
如何在10小時內通過項目和問題驅動的方式教計算機小白編程基礎?
Apr 02, 2025 am 07:18 AM
如何在10小時內教計算機小白編程基礎?如果你只有10個小時來教計算機小白一些編程知識,你會選擇教些什麼�...


 如何繞過Investing.com的反爬蟲機制獲取新聞數據?
Apr 02, 2025 am 07:03 AM
如何繞過Investing.com的反爬蟲機制獲取新聞數據?
Apr 02, 2025 am 07:03 AM
攻克Investing.com的反爬蟲策略許多人嘗試爬取Investing.com(https://cn.investing.com/news/latest-news)的新聞數據時,常常�...
