

javascript比较文档位置_javascript技巧

这个方法起先用在 IE ,用来确定 DOM Node 是否包含在另一个 DOM Element 中。
当尝试优化 CSS 选择器遍历(像:“#id1 #id2”),这个方法很有用。你可以通过 getElementById 得到元素,然后使用 .contains() 确定 #id1 实际上是否包含 #id2。
注意点:如果 DOM Node 和 DOM Element 相一致,.contains() 将返回 true ,虽然,一个元素不能包含自己。
这里有一个简单的执行包装,可以运行在:Internet Explorer, Firefox, Opera, and Safari。
function contains(a, b) {
return a.contains ? a != b && a.contains(b) : !!(a.compareDocumentPosition(arg) & 16);
}
2、NodeA.compareDocumentPosition(NodeB)
这个方法是 DOM Level 3 specification 的一部分,允许你确定 2 个 DOM Node 之间的相互位置。这个方法比 .contains() 强大。这个方法的一个可能应用是排序 DOM Node 成一个详细精确的顺序。
使用这个方法你可以确定关于一个元素位置的一连串的信息。所有的这些信息将返回一个比特码(Bit,比特,亦称二进制位)。
对于那些,人们知之甚少。比特码是将多重数据存储为一个简单的数字(译者注:0 或 1)。你最终打开 / 关闭个别数目(译者注:打开/关闭对应 0 /1),将给你一个最终的结果。
这里是从 NodeA.compareDocumentPosition(NodeB) 返回的结果,包含你可以得到的信息。
Bits Number Meaning
000000 0 元素一致
000001 1 节点在不同的文档(或者一个在文档之外)
000010 2 节点 B 在节点 A 之前
000100 4 节点 A 在节点 B 之前
001000 8 节点 B 包含节点 A
010000 16 节点 A 包含节点 B
100000 32 浏览器的私有使用
现在,这意味着一个可能的结果类似于:
<script> <BR> alert( document.getElementById("a").compareDocumentPosition(document.getElementById("b")) == 20); <BR></script>
一旦一个节点 A 包含另一个节点 B,包含 B(+16) 且在 B 之前(+4),则最后的结果是数字 20 。如果你查看比特发生的变化,将增加你的理解。
000100 (4) + 010000 (16) = 010100 (20)
这个,毫无疑问,有助于理解单个最混乱的 DOM API 方法。当然,他的价值当之无愧的。
现在,DOMNode.compareDocumentPosition 在 Firefox 和 Opera 中是可用的。然而,有一些技巧,我们可以用来在 IE 中执行他。
// Compare Position - MIT Licensed, John Resig
function comparePosition(a, b){
return a.compareDocumentPosition ?
a.compareDocumentPosition(b) :
a.contains ?
( a != b && a.contains(b) && 16 ) +
( a != b && b.contains(a) && 8 ) +
( a.sourceIndex >= 0 && b.sourceIndex >= 0 ?
(a.sourceIndex (a.sourceIndex > b.sourceIndex && 2 ) :
1 ) :
0;
}
IE 提供给我们一些可以使用的方法和属性。开始,使用 .contains() 方法(如我们前面所讨论的),以便给我们包含(+16)或者被包含(+8)的结果。IE 还有一个 .sourceIndex 属性在所有的 DOM Element 对应着元素在文档中的位置,例如:document.documentElement.sourceIndex == 0。因为我们有这个信息,我们可以完成两个 compareDocumentPosition 难题:在前面(+2)和在后面(+4)。另外,如果一个元素不在当前的文档,.sourceIndex 将等于 -1,这个给我们另外一个回答(+1)。最后,通过这个过程的推断,我们可以确定如果一个元素等于他本身,返回一个空的比特码(+0)。
这个函数可以在 Internet Explorer、Firefox 和 Opera 中运行。但在 Safari 中却有残缺功能(因为他只有 contains() 方法,而没有 .sourceIndex 属性。我们只能得到 包含(+16),被包含(+8),其他的所有结果都将返回(+1)代表一个断开)。
PPK 提供了一个关于通过创建一个 getElementsByTagNames 方法使新功能可以被使用的很棒的例子。让我们改编他到我们的新方法中:
// Original by PPK quirksmode.org
function getElementsByTagNames(list, elem) {
elem = elem || document;
var tagNames = list.split(','), results = [];
for ( var i = 0; i var tags = elem.getElementsByTagName( tagNames[i] );
for ( var j = 0; j results.push( tags[j] );
}
return results.sort(function(a, b){
return 3 - (comparePosition(a, b) & 6);
});
}
我们现在可以使用他来按次序构建一个站点的目录:
getElementsByTagNames("h1, h2, h3");
虽然 Firefox 和 Opera 都采取了一些主动落实这一方法。我依然期待看到更多的浏览器进入,以帮助向前推动。

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 小米14 Pro怎麼開啟nfc功能?
Mar 19, 2024 pm 02:28 PM
小米14 Pro怎麼開啟nfc功能?
Mar 19, 2024 pm 02:28 PM
現今手機的效能和功能越來越強大,幾乎所有手機都配備了便利的NFC功能,方便用戶進行行動支付和身分認證。然而,有些小米14Pro的用戶可能不清楚如何啟用NFC功能。接下來,讓我詳細向大家介紹一下。小米14Pro怎麼開啟nfc功能?步驟一:打開手機的設定選單。步驟二:找到並點選「連接和分享」或「無線和網路」選項。步驟三:在連接和共享或無線和網路選單中,找到並點擊「NFC和付款」。步驟四:找到並點選「NFC開關」。一般情況下,預設是關閉的狀態。步驟五:在NFC開關頁面上,點選開關按鈕,將其切換為開啟狀
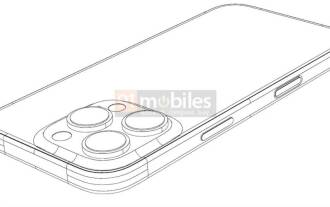 iPhone 16 Pro CAD 圖曝光 加入第二個新按鍵
Mar 09, 2024 pm 09:07 PM
iPhone 16 Pro CAD 圖曝光 加入第二個新按鍵
Mar 09, 2024 pm 09:07 PM
iPhone16Pro的CAD檔案已經曝光,設計與先前的傳聞一致。去年秋天,iPhone15Pro新增了Action按鈕,而今年秋天,Apple似乎計劃對這款硬體的尺寸進行微小的調整。加入Capture按鈕據傳言,iPhone16Pro可能會新增第二個新按鈕,這將是繼去年之後連續第二年增加新按鈕。傳聞指出新的Capture按鈕將被設定在iPhone16Pro的右下側,這項設計可望讓相機控制更加便捷,同時也能讓Action按鈕用於其他功能。這個按鈕將不再只是一個普通的快門按鈕。關於相機,從目前iP
 華為 Pocket2怎麼隔空刷抖音?
Mar 18, 2024 pm 03:00 PM
華為 Pocket2怎麼隔空刷抖音?
Mar 18, 2024 pm 03:00 PM
隔空滑動螢幕是華為的一項功能,在華為mate60系列中可以說是備受好評,這個功能是通過利用手機上的激光感應器和前置攝像頭的3D深感攝像頭,來完成一系列不需要觸碰螢幕的功能,比如說隔空刷抖音,但華為Pocket2該要怎麼隔空刷抖音呢?華為Pocket2怎麼隔空截圖? 1.開啟華為Pocket2的設定2、然後選擇【輔助功能】。 3.點選打開【智慧感知】。 4.打開【隔空滑動螢幕】、【隔空截圖】、【隔空按壓】開關就可以了。 5.使用的時候,需要再距離螢幕20~40CM處,張開手掌,待螢幕上出現手掌圖標,
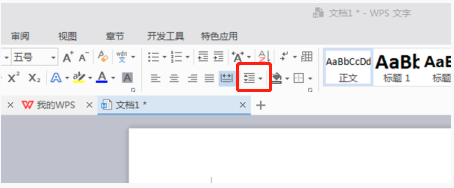 WPS Word怎麼設定行距讓文件更工整
Mar 20, 2024 pm 04:30 PM
WPS Word怎麼設定行距讓文件更工整
Mar 20, 2024 pm 04:30 PM
WPS是我們常用的辦公室軟體,在進行長篇文章的編輯時,常常會因為字體太小而看不清楚,所以會對字體和整個文件進行調整。例如:把文件進行行距的調整,會讓整個文件變得非常清晰,我建議各位小夥伴們都要學會這個操作步驟,今天就分享給大家,具體的操作步驟如下,快來看一看!開啟要調整的WPS文字文件,在【開始】選單中找到段落設定工具欄,你會看到行距設定小圖示(如圖中紅色線圈所示)。 2.點選行距設定右下角的小倒三角形,會出現對應的行距數值,可以選擇1~3倍行距(如圖箭頭所示)。 3.或者點選滑鼠右鍵點擊段落,就會出
 TrendX 研究院:Merlin Chain 計畫分析及生態盤點
Mar 24, 2024 am 09:01 AM
TrendX 研究院:Merlin Chain 計畫分析及生態盤點
Mar 24, 2024 am 09:01 AM
根據3月2日數據統計,比特幣二層網路MerlinChain總TVL已達30億美元。其中比特幣生態資產佔比達90.83%,包括價值15.96億美元的BTC以及4.04億美元的BRC-20資產等。上一個月,MerlinChain在開啟質押活動14天內,其TVL總額就已經達到了19.7億美元,超過了去年11月份上線也是最近同樣引人注目的Blast。 2月26日,MerlinChain生態內的NFT總價值超過了4.2億美元,成為除以太坊以外NFT市值最高的公鏈項目。項目簡介MerlinChain是OKX支
 C語言與PHP的區別及比較分析
Mar 20, 2024 am 08:54 AM
C語言與PHP的區別及比較分析
Mar 20, 2024 am 08:54 AM
C語言與PHP的差異及比較分析C語言和PHP都是常見的程式語言,但它們在許多方面有著明顯的差異。本文將對C語言和PHP進行比較分析,並透過具體的程式碼範例來說明它們之間的差異。一、語法和用途:C語言:C語言是一種過程導向的程式語言,主要用於系統級程式設計和嵌入式開發。 C語言的語法相對較為簡潔和底層,能夠直接操作內存,具有高效性和靈活性。 C語言強調程式設計師對程式的完全
 PHP7.2及5版比較及優劣勢分析
Feb 27, 2024 am 10:51 AM
PHP7.2及5版比較及優劣勢分析
Feb 27, 2024 am 10:51 AM
PHP7.2和5版本對比及優劣勢分析PHP是一種極為流行的伺服器端腳本語言,廣泛應用於Web開發。然而,PHP不斷在不同的版本中進行更新和改進,以滿足不斷變化的需求。目前,PHP7.2是最新版本,它和之前的PHP5版本相比有許多值得關注的差異和改進。在本文中,我們將對PHP7.2和PHP5版本進行對比,分析它們的優劣勢,並提供具體的程式碼範例。一、性能PH
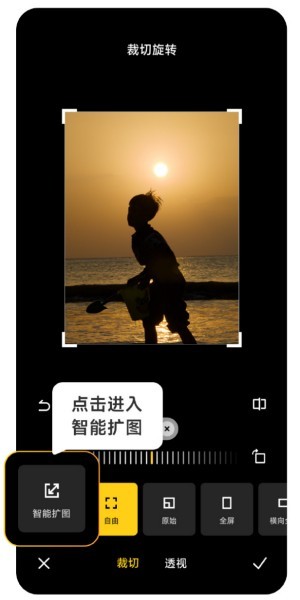 小米14 Ultra AI智慧擴圖如何使用?
Mar 16, 2024 pm 12:37 PM
小米14 Ultra AI智慧擴圖如何使用?
Mar 16, 2024 pm 12:37 PM
時代的進步讓許多人收入越來越高了,平時使用的手機也會經常更換,最近小米剛推出的小米14Ultra想必用戶們都是有所了解的,性能配置非常高,能夠為用戶們提供更為舒適的流暢體驗,不過新手機難免會遇到很多不會用的功能,例如小米14UltraAI智慧擴圖怎麼使用?快來看看下面的使用教學吧!小米14UltraAI智慧擴圖怎麼使用?先打開小米14Ultra,進入相冊,選擇想要進行擴圖的圖片,進入相簿編輯選項。點選其中的裁切旋轉,點選裁切,在出現的選擇中點選智慧擴圖。最後根據你自己的需求來選擇擴圖的方式,
