
透過前面一章我們了解了synchronized是一個重量級的鎖,雖然JVM對它做了很多優化,而下面介紹的volatile則是輕量級的synchronized。如果一個變數使用volatile,則它比使用synchronized的成本更加低,因為它不會引起線程上下文的切換和調度。 Java語言規範對volatile的定義如下:
Java程式語言允許執行緒存取共享變量,為了確保共享變數能準確且一致地更新,執行緒應該確保透過排他鎖單獨獲得這個變數。
上面比較繞口,通俗點講就是說一個變數如果用volatile修飾了,則Java可以確保所有執行緒看到這個變數的值是一致的,如果某個執行緒對volatile修飾的共享變數進行更新,那麼其他執行緒可以立刻看到這個更新,這就是所謂的執行緒可見性。
volatile雖然看起來比較簡單,使用起來無非就是在一個變數前面加上volatile即可,但是要用好並不容易(LZ承認我至今仍然使用不好,在使用時仍然是模棱兩可)。
理解volatile其實還是有點難度的,它與Java的記憶體模型有關,所以在理解volatile之前我們需要先了解有關Java記憶體模型的概念,這裡只做初步的介紹,後續LZ會詳細介紹Java記憶體模型。
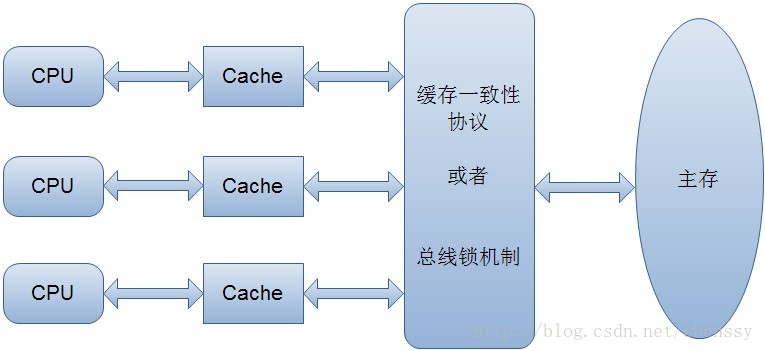
電腦在執行程式時,每個指令都是在CPU中執行的,在執行過程中勢必會涉及到資料的讀寫。我們知道程式運行的資料是儲存在主記憶體中,這時就會有一個問題,讀寫主記憶體中的資料沒有CPU中執行指令的速度快,如果任何的互動都需要與主記憶體打交道則會大大影響效率,所以就有了CPU高速緩存。 CPU高速緩存為某個CPU獨有,只與在該CPU運行的執行緒有關。
有了CPU快取雖然解決了效率問題,但是它會帶來一個新的問題:資料一致性。在程式運作中,會將運作所需的資料複製一份到CPU高速緩存中,在進行運算時CPU不再也主記憶體打交道,而是直接從快取中讀寫數據,只有當運作結束後才會將資料刷新到主記憶體。舉一個簡單的例子:
i++
當執行緒執行這段程式碼時,首先會從主記憶體讀取i( i = 1),然後複製一份到CPU快取中,然後CPU執行+ 1 (2)的操作,然後將資料(2)寫入告訴快取中,最後刷新到主記憶體中。其實這樣做在單線程中是沒有問題的,有問題的是在多線程中。如下:
假如有兩個執行緒A、B都執行這個操作(i++),依照我們正常的邏輯思考主記憶體中的i值應該=3,但事實是這樣麼?分析如下:
兩個執行緒從主記憶體讀取i的值(1)到各自的快取中,然後執行緒A執行+1操作並將結果寫入快取中,最後寫入主記憶體中,此時主存i==2,執行緒B做同樣的操作,主記憶體中的i仍然=2。所以最終結果為2並不是3。這種現象就是快取一致性問題。
解決快取一致性方案有兩種:
透過在總線加LOCK#鎖定的方式
原子性:即一個操作或多個操作要麼全部執行並且執行的過程不會被任何因素打斷,要麼就都不執行。原子性就像資料庫裡面的事務一樣,他們是一個團隊,同生共死。其實理解原子性非常簡單,我們看下面一個簡單的例子:
i = 0; ---1 j = i ; ---2 i++; ---3 i = j + 1; ---4
上面四个操作,有哪个几个是原子操作,那几个不是?如果不是很理解,可能会认为都是原子性操作,其实只有1才是原子操作,其余均不是。
1—在Java中,对基本数据类型的变量和赋值操作都是原子性操作;
2—包含了两个操作:读取i,将i值赋值给j
3—包含了三个操作:读取i值、i + 1 、将+1结果赋值给i;
4—同三一样
在单线程环境下我们可以认为整个步骤都是原子性操作,但是在多线程环境下则不同,Java只保证了基本数据类型的变量和赋值操作才是原子性的(注:在32位的JDK环境下,对64位数据的读取不是原子性操作*,如long、double)。要想在多线程环境下保证原子性,则可以通过锁、synchronized来确保。
volatile是无法保证复合操作的原子性
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
在上面已经分析了,在多线程环境下,一个线程对共享变量的操作对其他线程是不可见的。
Java提供了volatile来保证可见性。
当一个变量被volatile修饰后,表示着线程本地内存无效,当一个线程修改共享变量后他会立即被更新到主内存中,当其他线程读取共享变量时,它会直接从主内存中读取。
当然,synchronize和锁都可以保证可见性。
有序性:即程序执行的顺序按照代码的先后顺序执行。
在Java内存模型中,为了效率是允许编译器和处理器对指令进行重排序,当然重排序它不会影响单线程的运行结果,但是对多线程会有影响。
Java提供volatile来保证一定的有序性。最著名的例子就是单例模式里面的DCL(双重检查锁)。这里LZ就不再阐述了。
JMM比较庞大,不是上面一点点就能够阐述的。上面简单地介绍都是为了volatile做铺垫的。
volatile可以保证线程可见性且提供了一定的有序性,但是无法保证原子性。在JVM底层volatile是采用“内存屏障”来实现的。
上面那段话,有两层语义
保证可见性、不保证原子性
禁止指令重排序
第一层语义就不做介绍了,下面重点介绍指令重排序。
在执行程序时为了提高性能,编译器和处理器通常会对指令做重排序:
编译器重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序;
处理器重排序。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序;
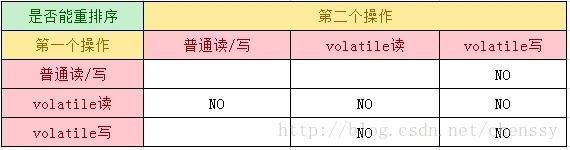
指令重排序对单线程没有什么影响,他不会影响程序的运行结果,但是会影响多线程的正确性。既然指令重排序会影响到多线程执行的正确性,那么我们就需要禁止重排序。那么JVM是如何禁止重排序的呢?这个问题稍后回答,我们先看另一个原则happens-before,happen-before原则保证了程序的“有序性”,它规定如果两个操作的执行顺序无法从happens-before原则中推到出来,那么他们就不能保证有序性,可以随意进行重排序。其定义如下:
同一个线程中的,前面的操作 happen-before 后续的操作。(即单线程内按代码顺序执行。但是,在不影响在单线程环境执行结果的前提下,编译器和处理器可以进行重排序,这是合法的。换句话说,这一是规则无法保证编译重排和指令重排)。
监视器上的解锁操作 happen-before 其后续的加锁操作。(Synchronized 规则)
对volatile变量的写操作 happen-before 后续的读操作。(volatile 规则)
线程的start() 方法 happen-before 该线程所有的后续操作。(线程启动规则)
线程所有的操作 happen-before 其他线程在该线程上调用 join 返回成功后的操作。
如果 a happen-before b,b happen-before c,则a happen-before c(传递性)。
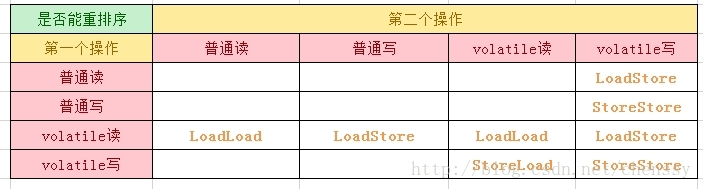
我们着重看第三点volatile规则:对volatile变量的写操作 happen-before 后续的读操作。为了实现volatile内存语义,JMM会重排序,其规则如下:
对happen-before原则有了稍微的了解,我们再来回答这个问题JVM是如何禁止重排序的?
觀察加入volatile關鍵字和沒有加入volatile關鍵字時所產生的彙編程式碼發現,加入volatile關鍵字時,會多出一個lock前綴指令 。 lock前綴指令其實相當於一個記憶體屏障。記憶體屏障是一組處理指令,用來實現對記憶體操作的順序限制。 volatile的底層就是透過記憶體屏障來實現的。下圖是完成上述規則所需的記憶體屏障:
volatile暫且下分析到這裡,JMM體系較為龐大,不是三言兩語能夠說清楚的,後面會結合JMM再一次對volatile深入分析。
volatile看起來簡單,但是要理解它還是比較難的,這裡只是對其進行基本的了解。 volatile相對於synchronized稍微輕量些,在某些場合它可以替代synchronized,但是又不能完全取代synchronized,只有在某些場合才能夠使用volatile。使用它必須滿足如下兩個條件:
對變數的寫入操作不依賴當前值;
該變數沒有包含在具有其他變數的不變式中。
volatile常用於兩個兩個場景:狀態標記兩、double check
週志明:《深入理解Java虛擬機》
方騰飛:《Java並發編程的藝術》
Java並發編程:volatile關鍵字解析
Java 並發程式設計:volatile的使用及其原理
透過前面一章我們了解了synchronized是一個重量級的鎖,雖然JVM對它做了很多優化,而下面介紹的volatile則是輕量級的synchronized。如果一個變數使用volatile,則它比使用synchronized的成本更加低,因為它不會引起線程上下文的切換和調度。 Java語言規範對volatile的定義如下:
Java程式語言允許執行緒存取共享變量,為了確保共享變數能準確且一致地更新,執行緒應該確保透過排他鎖單獨獲得這個變數。
上面比較繞口,通俗點講就是說一個變數如果用volatile修飾了,則Java可以確保所有執行緒看到這個變數的值是一致的,如果某個執行緒對volatile修飾的共享變數進行更新,那麼其他執行緒可以立刻看到這個更新,這就是所謂的執行緒可見性。
volatile雖然看起來比較簡單,使用起來無非就是在一個變數前面加上volatile即可,但是要用好並不容易(LZ承認我至今仍然使用不好,在使用時仍然是模棱兩可)。
理解volatile其實還是有點難度的,它與Java的記憶體模型有關,所以在理解volatile之前我們需要先了解有關Java記憶體模型的概念,這裡只做初步的介紹,後續LZ會詳細介紹Java記憶體模型。
電腦在執行程式時,每個指令都是在CPU中執行的,在執行過程中勢必會涉及到資料的讀寫。我們知道程式運行的資料是儲存在主記憶體中,這時就會有一個問題,讀寫主記憶體中的資料沒有CPU中執行指令的速度快,如果任何的互動都需要與主記憶體打交道則會大大影響效率,所以就有了CPU高速緩存。 CPU高速緩存為某個CPU獨有,只與在該CPU運行的執行緒有關。
有了CPU快取雖然解決了效率問題,但是它會帶來一個新的問題:資料一致性。在程式運作中,會將運作所需的資料複製一份到CPU高速緩存中,在進行運算時CPU不再也主記憶體打交道,而是直接從快取中讀寫數據,只有當運作結束後才會將資料刷新到主記憶體。舉一個簡單的例子:
i++
當執行緒執行這段程式碼時,首先會從主記憶體讀取i( i = 1),然後複製一份到CPU快取中,然後CPU執行+ 1 (2)的操作,然後將資料(2)寫入告訴快取中,最後刷新到主記憶體中。其實這樣做在單線程中是沒有問題的,有問題的是在多線程中。如下:
假如有兩個執行緒A、B都執行這個操作(i++),依照我們正常的邏輯思考主記憶體中的i值應該=3,但事實是這樣麼?分析如下:
兩個執行緒從主記憶體讀取i的值(1)到各自的快取中,然後執行緒A執行+1操作並將結果寫入快取中,最後寫入主記憶體中,此時主存i==2,執行緒B做同樣的操作,主記憶體中的i仍然=2。所以最終結果為2並不是3。這種現象就是快取一致性問題。
解決快取一致性方案有兩種:
透過在匯流排加LOCK#鎖定的方式
通过缓存一致性协议
但是方案1存在一个问题,它是采用一种独占的方式来实现的,即总线加LOCK#锁的话,只能有一个CPU能够运行,其他CPU都得阻塞,效率较为低下。
第二种方案,缓存一致性协议(MESI协议)它确保每个缓存中使用的共享变量的副本是一致的。其核心思想如下:当某个CPU在写数据时,如果发现操作的变量是共享变量,则会通知其他CPU告知该变量的缓存行是无效的,因此其他CPU在读取该变量时,发现其无效会重新从主存中加载数据。
上面从操作系统层次阐述了如何保证数据一致性,下面我们来看一下Java内存模型,稍微研究一下Java内存模型为我们提供了哪些保证以及在Java中提供了哪些方法和机制来让我们在进行多线程编程时能够保证程序执行的正确性。
在并发编程中我们一般都会遇到这三个基本概念:原子性、可见性、有序性。我们稍微看下volatile
原子性:即一个操作或者多个操作 要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
原子性就像数据库里面的事务一样,他们是一个团队,同生共死。其实理解原子性非常简单,我们看下面一个简单的例子即可:
i = 0; ---1 j = i ; ---2 i++; ---3 i = j + 1; ---4
上面四个操作,有哪个几个是原子操作,那几个不是?如果不是很理解,可能会认为都是原子性操作,其实只有1才是原子操作,其余均不是。
1—在Java中,对基本数据类型的变量和赋值操作都是原子性操作;
2—包含了两个操作:读取i,将i值赋值给j
3—包含了三个操作:读取i值、i + 1 、将+1结果赋值给i;
4—同三一样
在单线程环境下我们可以认为整个步骤都是原子性操作,但是在多线程环境下则不同,Java只保证了基本数据类型的变量和赋值操作才是原子性的(注:在32位的JDK环境下,对64位数据的读取不是原子性操作*,如long、double)。要想在多线程环境下保证原子性,则可以通过锁、synchronized来确保。
volatile是无法保证复合操作的原子性
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
在上面已经分析了,在多线程环境下,一个线程对共享变量的操作对其他线程是不可见的。
Java提供了volatile来保证可见性。
当一个变量被volatile修饰后,表示着线程本地内存无效,当一个线程修改共享变量后他会立即被更新到主内存中,当其他线程读取共享变量时,它会直接从主内存中读取。
当然,synchronize和锁都可以保证可见性。
有序性:即程序执行的顺序按照代码的先后顺序执行。
在Java内存模型中,为了效率是允许编译器和处理器对指令进行重排序,当然重排序它不会影响单线程的运行结果,但是对多线程会有影响。
Java提供volatile来保证一定的有序性。最著名的例子就是单例模式里面的DCL(双重检查锁)。这里LZ就不再阐述了。
JMM比较庞大,不是上面一点点就能够阐述的。上面简单地介绍都是为了volatile做铺垫的。
volatile可以保证线程可见性且提供了一定的有序性,但是无法保证原子性。在JVM底层volatile是采用“内存屏障”来实现的。
上面那段话,有两层语义
保证可见性、不保证原子性
禁止指令重排序
第一层语义就不做介绍了,下面重点介绍指令重排序。
在执行程序时为了提高性能,编译器和处理器通常会对指令做重排序:
编译器重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序;
处理器重排序。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序;
指令重排序對單執行緒沒有什麼影響,他不會影響程式的運行結果,但是會影響多執行緒的正確性。既然指令重排序會影響到多執行緒執行的正確性,那麼我們就需要禁止重新排序。那麼JVM是如何禁止重新排序的呢?這個問題稍後回答,我們先看另一個原則happens-before,happen-before原則保證了程序的“有序性”,它規定如果兩個操作的執行順序無法從happens-before原則中推到出來,那麼他們就不能保證有序性,可以隨意進行重新排序。其定義如下:
同一個執行緒中的,前面的操作 happen-before 後續的操作。 (即單執行緒內按程式碼順序執行。但是,在不影響在單執行緒環境執行結果的前提下,編譯器和處理器可以進行重排序,這是合法的。換句話說,這項是規則無法保證編譯重排和指令重排)。
監視器上的解鎖操作 happen-before 其後續的加鎖操作。 (Synchronized 規則)
對volatile變數的寫入操作 happen-before 後續的讀取操作。 (volatile 規則)
線程的start() 方法 happen-before 該線程所有的後續操作。 (執行緒啟動規則)
執行緒所有的操作 happen-before 其他執行緒在該執行緒上呼叫 join 回傳成功後的操作。
如果 a happen-before b,b happen-before c,則a happen-before c(傳遞性)。
我們著重看第三點volatile規則:對volatile變數的寫入操作 happen-before 後續的讀取操作。為了實現volatile記憶體語義,JMM會重新排序,其規則如下:
對happen-before原則有了稍微的了解,我們再來回答這個問題JVM是如何禁止重新排序的?
觀察加入volatile關鍵字和沒有加入volatile關鍵字時所產生的彙編程式碼發現,加入volatile關鍵字時,會多出一個lock前綴指令。 lock前綴指令其實相當於一個記憶體屏障。記憶體屏障是一組處理指令,用來實現對記憶體操作的順序限制。 volatile的底層就是透過記憶體屏障來實現的。下圖是完成上述規則所需的記憶體屏障:
volatile暫且下分析到這裡,JMM體系較為龐大,不是三言兩語能夠說清楚的,後面會結合JMM再一次對volatile深入分析。
volatile看起來簡單,但是要理解它還是比較難的,這裡只是對其進行基本的了解。 volatile相對於synchronized稍微輕量些,在某些場合它可以替代synchronized,但是又不能完全取代synchronized,只有在某些場合才能夠使用volatile。使用它必須滿足如下兩個條件:
對變數的寫入操作不依賴當前值;
該變數沒有包含在具有其他變數的不變式中。
volatile常用於兩個兩個場景:狀態標記兩、double check
以上就是【死磕Java並發】-- ---深入分析volatile的實現原理的內容,更多相關內容請關注PHP中文網(www.php.cn)!





















