
B-Tree又叫平衡多路查找树(并不是二叉的)使用B-tree结构可以显著减少定位记录时所经历的中间过程,从而加快存取速度。
左子节点关键字值在B-Tree中按key检索数据的算法非常直观:首先从根节点进行二分查找,如果找到则返回对应节点的data,否则对相应区间的指针指向的节点递归进行查找,直到找到节点或找到null指针,前者查找成功,后者查找失败。 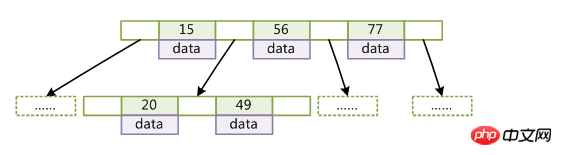
(key为记录的键值,对于不同数据记录,key是互不相同的;data为数据记录除key外的数据)
B+Tree是一种改进后的B-tree。 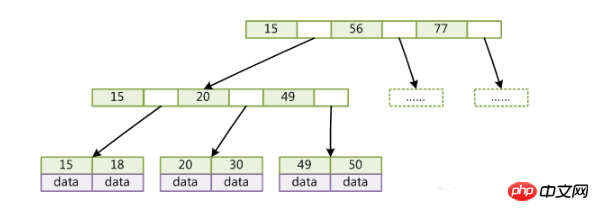
(key为记录的键值,对于不同数据记录,key是互不相同的;data为数据记录除key外的数据)
与B-Tree相比,B+Tree有以下不同点:
每个节点的指针上限为2d而不是2d+1。
内节点不存储data,只存储key;叶子节点不存储指针。
计算机的机械磁盘,为了摊还机械移动花费的等待时间,磁盘会一次存取多个数据项而不是一个,这样的一次读取的信息单元是page,我们可以用读或写的页数作为磁盘存取总时间的主要近似值,在任何时刻,B树算法都只需在内存中保持一定数量的页面。B树的设计考虑磁盘预读取这点,一个B树的节点通常和一个完整磁盘页(page)一样大,并且磁盘页的大小限制了一个B树节点可以含有的孩子个数(分支因子),当然这个具体也需要取决于一个关键字相对一页的大小。
为了尽量减少I/O操作,磁盘读取每次都会预读,大小通常为页的整数倍。即使只需要读取一个字节,磁盘也会读取一页的数据(通常为4K)放入内存,内存与磁盘以页为单位交换数据。因为局部性原理认为,通常一个数据被用到,其附近的数据也会立马被用到。
B-Tree:如果一次检索需要访问4个节点,数据库系统设计者利用磁盘预读原理,把节点的大小设计为一个页,那读取一个节点只需要一次I/O操作,完成这次检索操作,最多需要3次I/O(根节点常驻内存)。数据记录越小,每个节点存放的数据就越多,树的高度也就越小,I/O操作就少了,检索效率也就上去了。
B+Tree:非叶子节点只存key,大大滴减少了非叶子节点的大小,那么每个节点就可以存放更多的记录,树更矮了,I/O操作更少了。所以B+Tree拥有更好的性能。
索引说白了就是一种数据结构。
索引也是有代价的:索引文件本身要消耗存储空间,同时索引会加重插入、删除和修改记录时的负担,另外,MySQL在运行时也要消耗资源维护索引,因此索引并不是越多越好。一般两种情况下不建议建索引
第一种情况是表记录比较少
另一种不建议建索引的情况是索引的选择性较低。所谓索引的选择性(Selectivity),是指不重复的索引值(也叫基数,Cardinality)与表记录数(#T)的比值
一、普通索引
二、唯一索引
三、主键索引
四、组合索引
MySQL中普遍使用B+Tree做索引,但在实现上又根据聚簇索引和非聚簇索引而不同。
所謂叢集索引,就是指主索引檔案與資料檔案為同一份文件,叢集索引主要用在Innodb儲存引擎中。在這個索引實作方式中B+Tree的葉子節點上的data就是資料本身,key為主鍵。如下圖: 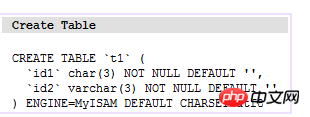
(t1表) 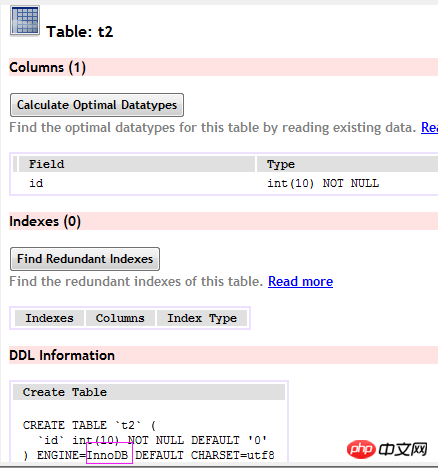
(t2表) 
(資料庫對應的檔案)
因為InnoDB的資料檔案本身要按主鍵聚集,所以InnoDB要求表必須有主鍵(MyISAM可以沒有),如果沒有明確指定,則MySQL系統會自動選擇一個可以唯一標識資料記錄的資料列作為主鍵,如果不存在這種列,則MySQL自動為InnoDB表產生一個隱含欄位作為主鍵,這個欄位長度為6個位元組,類型為長整形。
主要差異:
MyISAM是非事務安全型的,而InnoDB是事務安全型的。
MyISAM鎖定的粒度是表級,而InnoDB支援行級鎖定。
MyISAM支援全文類型索引,而InnoDB不支援全文索引。
MyISAM相對簡單,所以在效率上要優於InnoDB,小型應用可以考慮使用MyISAM。
MyISAM表是保存成檔案的形式,在跨平台的資料轉移中使用MyISAM儲存會省去不少的麻煩。
InnoDB表比MyISAM表更安全,可以在保證資料不會遺失的情況下,切換非事務表到事務表(alter table tablename type=innodb)。
應用場景:
MyISAM管理非事務表。它提供高速儲存和檢索,以及全文搜尋能力。如果應用程式中需要執行大量的SELECT查詢,那麼MyISAM是更好的選擇。
InnoDB用於事務處理應用程序,具有眾多特性,包括ACID事務支援。如果應用程式中需要執行大量的INSERT或UPDATE操作,則應該使用InnoDB,這樣可以提高多使用者並發操作的效能。
取過程
當系統需要讀取主記憶體時,則將位址訊號放到位址匯流排上傳給主記憶體,主存讀到位址訊號後,解析訊號並定位到指定儲存單元,然後將此儲存單元資料放到資料匯流排上,供其它零件讀取。
寫入主記憶體的過程類似,系統將要寫入單元位址和資料分別放在位址匯流排和資料匯流排上,主記憶體讀取兩個匯流排的內容,做對應的寫入作業。
這裡可以看出,主記憶體存取的時間僅與存取次數呈線性關係,因為不存在機械操作,兩次存取的資料的「距離」不會對時間有任何影響,例如,先取A0再取A1和先取A0再取D3的時間消耗是一樣的
當需要從磁碟讀取資料時,系統會將資料邏輯位址傳給磁碟,磁碟的控制電路依照尋址邏輯將邏輯位址翻譯成實體位址,即確定要讀取的資料在哪個磁軌,哪個磁區。為了讀取這個磁區的數據,需要將磁頭放到這個磁區上方,為了實現這一點,磁頭需要移動對準相應磁軌,這個過程叫做尋道,所耗費時間叫做尋道時間,然後磁碟旋轉將目標扇區旋轉到磁頭下,這個過程耗費的時間叫做旋轉時間。
以上就是MySQL索引以及結構深入詳解的內容,更多相關內容請關注PHP中文網(www.php.cn)!





















