
一。前言
通常,我們分頁時要怎麼實現?
SELECT * FROM table ORDER BY id LIMIT 1000, 10;
但是,資料量大增以後呢?
SELECT * FROM table ORDER BY id LIMIT 1000000, 10;
如上第二條查詢時很慢的,直接拖死。
最關鍵的原因mysql查詢機制的問題:
#不是先跳過,後再查詢;
而是先查詢,然後跳過。 (解釋如下)
什麼意思?例如limit 100000,10,在找到需要的那10條時,先會輪詢經過前10W條數據,先回行查詢出前100000條的字段數據,然後發現沒用捨棄掉,直到最後找到需要的10條。
二。分析limit offset,N, 當offset非常大時,效率極低,原因是mysql並不是跳過offset行,然後單取N行,
而是取offset+N行,返回放棄前offset行,返回N行【同前邊說的先查詢,後跳過】.效率較低,當offset越大時,效率越低三。 3條最佳化建議
1:#從業務上去解決
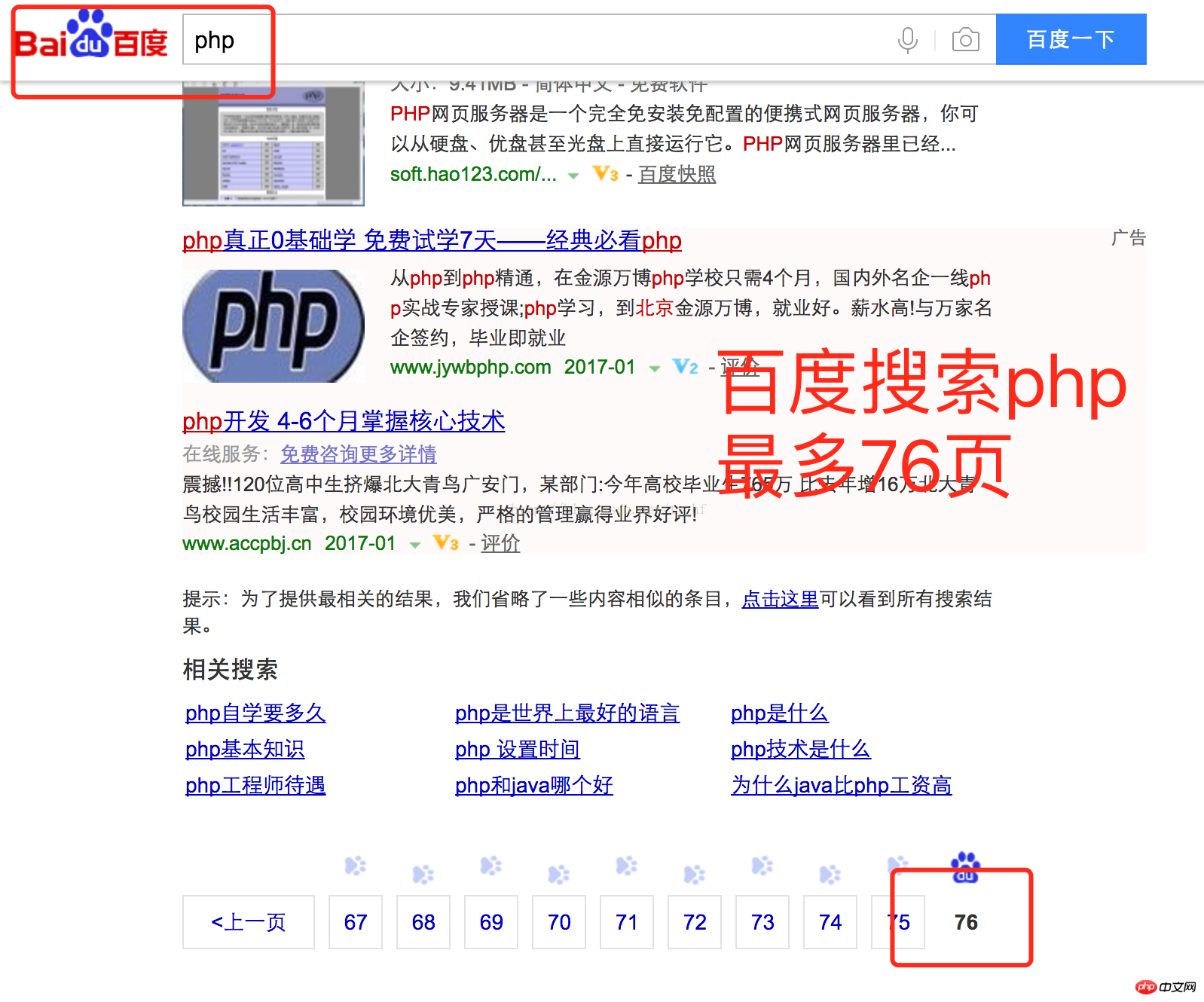
辦法
不允許翻過100頁以百度為例,一般翻頁到70頁左右.
##2:不用
offset,#用條件查詢.
範例:
mysql> select id, from lx_com limit 5000000,10; +---------+--------------------------------------------+ | id | name | +---------+--------------------------------------------+ | 5554609 |温泉县人民政府供暖中心 | .................. | 5554618 |温泉县邮政鸿盛公司 | +---------+--------------------------------------------+ 10 rows in set (5.33 sec) mysql> select id,name from lx_com where id>5000000 limit 10; +---------+--------------------------------------------------------+ | id | name | +---------+--------------------------------------------------------+ | 5000001 |南宁市嘉氏百货有限责任公司 | ................. | 5000002 |南宁市友达电线电缆有限公司 | +---------+--------------------------------------------------------+ 10 rows in set (0.00 sec)
現象:從5.3秒到不到100毫秒,查詢速度大幅加快;但是資料結果卻不一樣優點:利用where條件來避免掉先查詢後跳過的問題,而是
條件縮小範圍,以便直接跳過。有問題: 有時有會發現用此方法與limitM,N,兩個次的結果不一致[如上邊實例所展示]
############原因###:###資料已被物理刪除過###,###有空洞###.###### ##########解決###:###資料不進行物理刪除###(###可以邏輯刪除###).###最终在页面上显示数据时,逻辑删除的条目不显示即可.
(一般来说,大网站的数据都是不物理删除的,只做逻辑删除 ,比如 is_delete=1)
3:延迟索引.
非要物理删除,还要用offset精确查询,还不限制用户分页,怎么办?
优化思路:
利用索引覆盖,快速查询出满足条件的主键id;然后凭借主键id作为where条件,达到快速查询。
(速度快在哪里?利用索引覆盖不需要回行就可以快速查询出满足条件的id,时间节约在这里了)
我们现在必须要查,则只查索引,不查数据,得到id.再用id去查具体条目. 这种技巧就是延迟索引.
慢原因:
查询100W条数据的id,name,m每次查询回行抛弃,跨过100W后取到真正要的数据。【就是我们刚刚说的,先查询,后跳过】
优化后快原理:
a.利用索引覆盖先查询出主键id,在索引上就拿到信息了,避免回行
b.找到主键后,根据已知的目标主键在查询,避免跨大数据行去寻找,而是直接定位哪几条数据直接查询。
本方法即延迟索引查询。
mysql> select id,name from lx_com inner join (select id from lx_com limit 5000000,10) as tmp using(id); +---------+-----------------------------------------------+ | id | name | +---------+-----------------------------------------------+ | 5050425 | 陇县河北乡大谈湾小学 | ........ | 5050434 | 陇县堎底下镇水管站 | +---------+-----------------------------------------------+ 10 rows in set (1.35 sec)
四。总结:
从方案上来说,肯定是方法一优先,从业务上去满足是否要翻那么多页。
如果业务要求,则用id>n limit m的方式来代替limit n,m,但缺点是不能有物理删除
如果非有物理删除有空缺不能用方法二,则用延迟索引法,本质是利用索引覆盖先快速取出索引值,根据锁定的目标的索引值。一次性去回行取值,效果很明显。
以上就是Mysql优化-大数据量下的分页策略的内容,更多相关内容请关注PHP中文网(www.php.cn)!





















