

新聞APP後端系統架構成長之路 - 高可用架構設計圖文詳解

轉載請註明來源:新聞APP後端系統架構成長之路 - 高可用架構設計
# 1,初入聖地
2,築基:完全重構
# 3,金丹:踩坑。 。而且是踩大坑
4,元嬰:面臨挑戰,流量來襲
5,出竅:伺服器架構調整最佳化
# 6,渡劫:服務治理平台
# 7,大乘:服務端高可用
8,飛升:用戶端高可用-【2017 HTTPS+HTTP-DNS】
1,初入聖地
# 因為工作安排,一些原APP後端的前輩們轉移到了其他業務部門,2015年底開始接手客戶端後端工作,初入聖地,可謂如進煉獄。
當時因手上還有很多業務開發工作需要小夥伴們繼續支持,只能自己先單槍匹馬闖入了APP後端開發。
從原來得心應手的內容業務開發,轉變到APP後端介面開發,有很多APP方面的專業領域知識還不了解,只能一點點和端上的同學進行請教學習,同時也感謝端上的同學進行的幫助。雖然面臨各種困難,但是業務還要繼續前進,版本迭代還在緊張進行中。
就這樣一天天一邊Coding 一邊修BUG 一邊 和十幾位漂亮的產品妹子的各種需求進行周旋。
舊API為12年初開發,至15年底,將近4年時間共經手了4撥人馬,裡面有多少坑可想而知,半夜爬起修復線上BUG已為常事。
同時老API效能問題也不樂觀,介面回應時間以秒計算,當時業務規模還小,原開發前輩們對服務架構及優化也沒有特別的重視。隨著用戶規模快速成長,PUSH一發,服務必掛,無奈只能肉扛。就這樣一面支持緊張版本迭代,一面踩坑,一面填坑,當然也默默的挖坑,持續了一月有餘。
後來對整個舊API代碼完全摸清後,發現4年時間內,APP髮型了版本幾十個,原本老大神前輩們寫的優秀代碼,經過四年時間內,被幾波人改的已經面目全非,嚴重違背了設計初衷,API代碼中全是版本代碼兼容,各版本之間完全沒有分離,單個文件IF ELSE就十餘個,已無法進行擴展,可謂牽一發而動全身,隨便調整幾行代碼就可能導致所有版本整體服務不可用,如果繼續維持,也只能將就個一年半載甚至更短,但是時間越長業務代碼越亂,到時候會面臨更加被動的狀態。
#
2,築基底:介面重建
# 如不改變,必不可長久!只能痛下決心,完全重構!
# 但是業務發展和版本迭代不能停滯,只能從原有內容業務開發調來兩位同學一起繼續支援老API開發,同時我開始對新介面架構設計進行研究。
因對APP開發經驗不足、水平有限,介面重構開始發現無從下手一片空白,連續兩週反反复復熬夜寫了幾套框架,白天和同學們討論,發現各種問題,一一推翻。
無奈只能查詢各種資料,借鏡各大網路應用經驗,同時遍訪名師【感謝:@青哥,@徐大夫,@晶晶,@強哥@濤哥及APP端和WAP端小夥伴們的指導】,透過大量學習,慢慢對整個新介面架構搭建想法有了整體的規劃,感覺見到曙光。
透過一週的日夜趕工,我把整體框架結構初步搭建完畢,馬不停蹄,不敢停歇,那就開始帶領小夥伴們開幹吧!
雖然對整體設計有了大概思路,但是介面重構也面臨很大的問題,需要APP端及產品、統計同學的鼎力支援才能進行下去。
新介面與老介面無論是從呼叫方式或資料輸出結構完全不同,導致APP端程式碼需要大量修改【感謝 @輝輝 @明明 支援配合】
當然統計也面臨同樣的問題,所有的介面都變了,也就是 原來所有的統計規則都需要修改,同時也感謝【@嶸姑娘 @統計部門 @產品 同學】的大力配合。沒有兩端及產品,統計的支持,介面重構工作進度就無從談起,同時也感謝各位領導的大力支持,保障重構工作如期進行。
新介面主要從下面幾個方面進行了著重設計:
1,安全性,
1>, 介面請求增加簽章驗證,建立介面加密請求機制,每個請求位址產生唯一ID,服務端用戶端 雙向加密,並有效避免惡意刷介面。
2>,所有業務參數註冊制,統一安全管理
2,可擴充性
高內聚低耦合,強製版本分離,APP版本扁平化發展,同時提高程式碼復用性,小版本走繼承製。
3,資源管理
服務註冊制,統一入口出口,所有介面需向系統註冊,保障永續發展。後續監控調度降級提 保障。
4,統一快取調度分配系統
#
3,金丹:踩坑。 。 。 。而且是 踩大坑
# 新介面隨著5.0發版如期上線了,以為萬事大吉,可誰知,大坑在前面一直在默默的等著我。
# APP有一個PUSH特性,每次發PUSH會瞬間召回大量用戶訪問APP。
新介面每次發完PUSH,伺服器必掛,悲劇了。
故障表現:
1,php-fpm 堵死,伺服器整體狀況無異常,
# 2,nginx 倒是沒有掛,服務正常。
3,重啟 php-fpm 短暫服務正常,幾秒鐘後又會死掉。
4,介面回應慢,或逾時,app刷新無內容
#故障排查猜測#
一開始懷疑下面幾個問題,
1,MC有問題
2,MYSQL慢
3,請求量大
4,部分請求是代理的老接口,會導致請求翻倍
5,網路問題
6,有些依賴介面慢,把服務拖死
但是因為缺少日誌記錄,所以上面都沒有追蹤到任何依據。
問題追蹤:
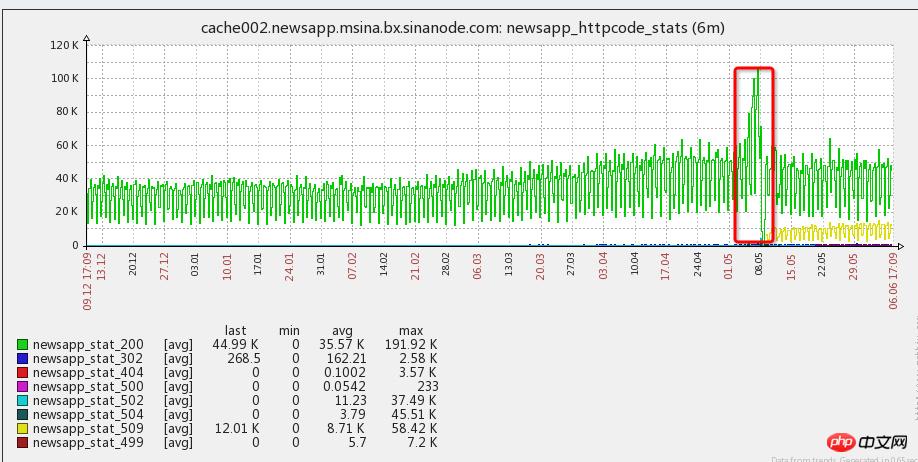
#發push時伺服器壓力瞬間上升,短時間內PHP-FPM會阻塞掛掉
PHP是順序執行,只要有一個後端介面慢,就會造成排隊等待,高並發情況下,吞吐量直線下降,直到PHP 完全被拖死。
1,push時會大量召回APP用戶,同時打開客戶端是平時的3-5 倍如圖(早晚高峰會疊加)
2,客戶端打開PUSH時會,是冷啟動拉起用戶,會調用很多接口資源,並且新API上線之初沒有與 APP端同學進行充分溝通,導致瞬間請求巨量接口,其中包含很多實時興趣、廣告等不能緩存 的後端接口大量裸奔,及MYSQL 等資源,導致大量等待。
3,介面請求後端資源逾時時間設定過長,未及時釋放慢介面請求,造成大量介面請求排隊等待
4,用戶規模成長,APP用戶規模已經和年初相較於翻了一倍,工作重心一直放到了程式碼重構,但是服 務器方面的資源一直被忽視,一直沒有任何新增機器,也是本次故障的一個原因。 【註:硬體投 入其實是成本最低的投入】
然後,然後 就掛了。 。 。
#
問題解決:
1,優化NGINX層緩存,可以快取的內容【如正文】,在NGINX層做CACHE,減少後端壓力
2,停用不必要的介面處理【如統計】,NGINX直接返回,不走PHP,減少PHP-FPM壓力
3,重新梳理請求的後端介面資源,根據業務重要性排優先級, 嚴格控制超時時間。
4,新增設備,重新根據使用者規模計算及配置伺服器資源
5,記錄資源呼叫日誌,監控依賴資源,一旦資源出現問題,及時找提供者解決
6,調整MC快取結構,提升快取利用率
7,與端充分溝通仔細梳理APP對介面請求的次序及頻次,提升有效介面利用率。
透過這一系列改進措施,效果還是比較明顯,新API的效能優勢與舊API相比如下:
舊:小於100ms的請求佔55%
 #舊 API 回應時間
#舊 API 回應時間
# 新:93%以上回應時間小於100ms
 #新 API 回應時間
#新 API 回應時間
問題摘要:
究其根本原因主要有以下幾點,1,應對不足,2,缺少重複溝通,3,健壯性不足,4,PUSH特性
1>,應對不足
用戶規模從年初至當時增加了一倍有餘,未能引起足夠注意,接口重構進度還是慢了一拍,沒有留下充分的優化、思考時間,直接上場徵戰,且沒有及時新增伺服器設備資源,導致踩大坑。
2>,缺少溝通
沒有與APP端同學及維運部門保持充分溝通,只關心了自己腳下一攤。一定要和端上,及維 同學保持足夠的溝通,融為一體。根據現有資源條件【硬件,軟體,依賴資源等】,詳細約定各種資源請求時機、頻次等,適當延遲非主應用介面請求,保障主業務可用,充分利用服務資源。
註:特別是要和端上同學保持好溝通,端上同學開發是根據APP端的業務邏輯需要來請求接口,如果請求接口過量,就相當與自己的APP對自己的服務器發起了大量Ddos攻擊,非常可怕。 。
3>,健全性不足
# 過度依賴信任第三方接口,對依賴接口超時設定不合理,快取利用不充分,無災難備份,依賴資源出問題,只能眼睜睜的等死。
註:不信任原則,對任何依賴資源都不要信任,做好依賴介面隨時掛掉的準備,一定要有容災措施,嚴格設定超時時間,該放棄的就放棄。 做好服務降級策略。 【參考:1,業務降級,加上快取降低更新頻次,2,保障主業務,幹掉非必要業務,3,用戶降級,捨棄部分用戶,保障優質用戶】。 記錄日誌,日誌是系統的眼睛,即使記錄日誌會消耗部分系統效能,也要記錄日誌,一旦系統出現問題,可以透過日誌迅速定位解決問題。
4>,突發大流量
# PUSH和第三方拉起瞬間帶來巨額流量,系統無法承受,缺乏有效的熔斷限流及降級自我保護措施。
小結:透過這次問題我也學到了很多,對整體系統架構有了更深入的了解。同時也領悟了一些道理,有些事情並不是那麼想當然、水到渠成的,凡事做之前要做好充分的細緻的準備。重構不是單純對程式碼重寫,需要對整個上下游系統資源有充分的了解與認知,及做好萬全的準備,如否踩坑將成必然。
4,元嬰:面臨挑戰
# 盼望著,盼望著,流量來了,奧運將近!
BOSS 濤哥放話:如果奧運不故障,請同學吃大餐!如果奧運故障,請濤哥吃大餐!所以為了大餐堅決不能出任何問題!
奧運前我們一直處於備戰狀態,進行了大量優化工作,確保完美度過奧運流量高峰。
1,對所有依賴的資源進行了仔細梳理,重點業務介面進行細緻監控
2,在APP端部署日誌上報模組,即時上報異常日誌,進行監控
3,升級MC叢集進行升級擴容及對系統快取統一最佳化管理
# 4,上線多層業務熔斷降級策略
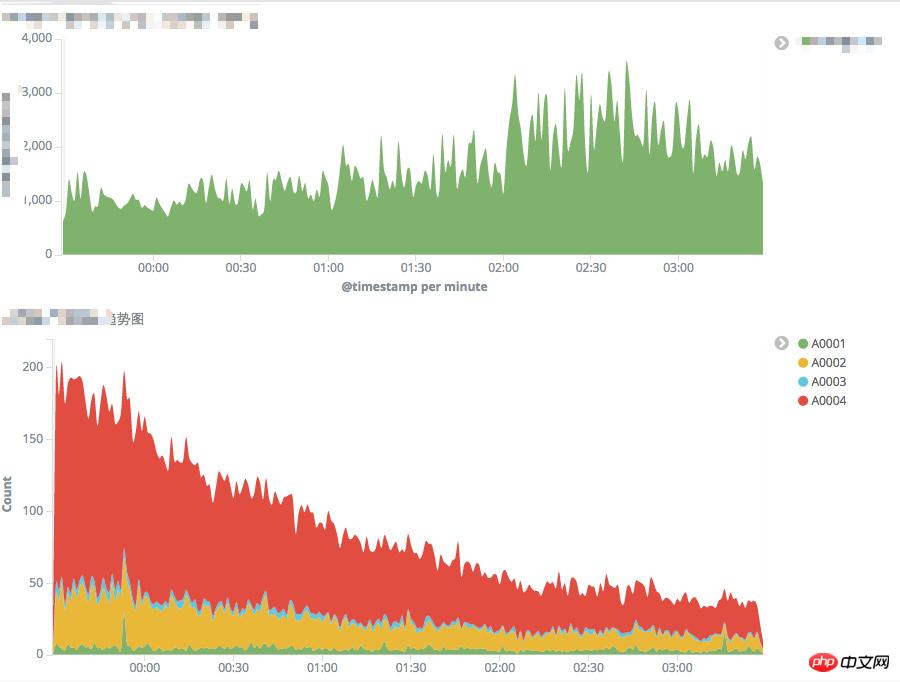
但奧運真的來了,系統還是遭受了很大考驗,奧運開始,為確保系統各項指標正常運作不出任何問題,我們安排工程師輪班24小時在公司值班,奧運首金PUSH不負眾望,瞬間帶來平時5倍以上的流量,各項資源吃緊,伺服器開始滿載運轉。我們先前的準備工作在此刻發揮了作用,值班工程師時刻關注監控大屏,隨時根據監控數據及伺服器負載狀態調整系統參數,同時對各項數據進行提前預熱,平穩度過了奧運首金!首金過後,根據觀察奧運期間發現其他各項奪金事件帶來的流量和首金相比不算太大,我天真的以為整個奧運流量高峰已經安然度過。 【首金異常監控圖如下】
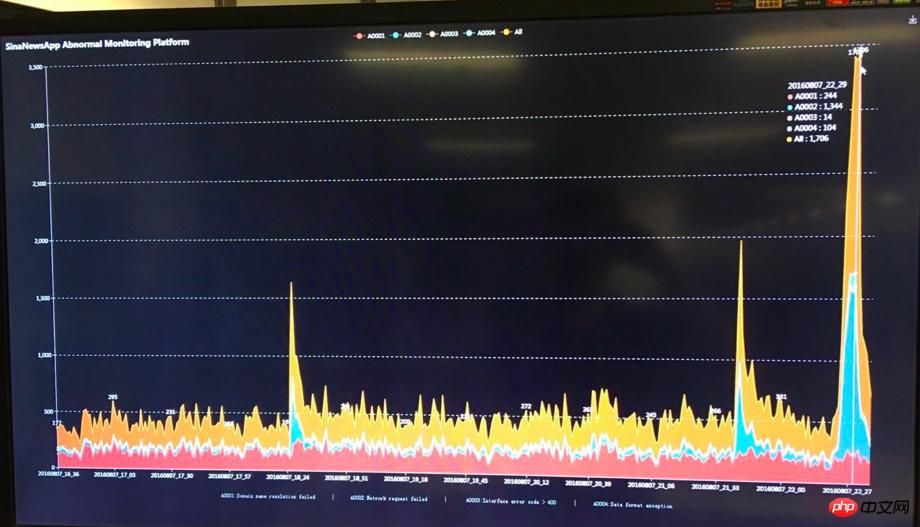
# 可,【天公作美。 。 】寶寶事件突然來襲,和奧運疊加!寶寶事件首日PUSH帶來的流量遠遠超出了首金流量高峰,在眾多八卦用戶的大力支持下,我們的系統終於遭受了有生以來最大考驗,伺服器滿載運行,PUSH瞬間APP端訪問開始出現響應慢的情況,即時監控時間顯示錯誤率也開始上升。
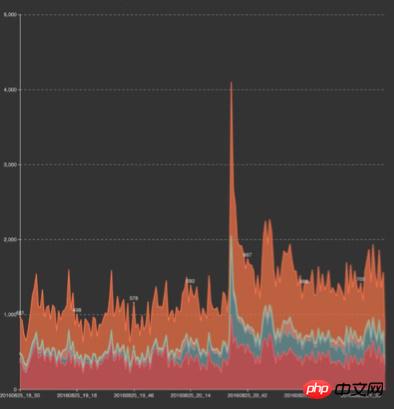 寶寶事件PUSH與奧運疊加流量
寶寶事件PUSH與奧運疊加流量
# 我們馬上啟用應急方案,對系統進行過載保護,業務根據重要性依次進行降級【一般包含:降低更新頻率,延長緩存時間,停用】,保護系統整體可用性不受影響,確保系統平穩度過流量高峰。手動開啟降級後,系統開始迅速釋放大量資源,系統負載開始平穩下降,用戶端回應時間恢復到正常水準。等PUSH過後【一般高峰持續3分鐘左右】,人工取消降級。
雖然奧運期間突然闖入寶寶事件,我們還算是平穩度過,整體服務沒有出現問題,APP整體業務數據隨著這兩個事件也有了極大提升。
BOSS也請同學一起吃大餐HAPPY了一把!
小結:1,監控系統還需更細緻,需要加入資源監控,因為透過事後分析發現,看到的有些問題並不流量導致,可能會是因為依賴資源問題,導致系統擁堵,放大影響。 2,完善警報系統,因突發事件的發生不可預測,不可能有人一直24小時值班。 3,自動降級機制服務治理系統嗑待建立,遇到突發流量,或依賴資源突發異常,無人值守自動降級。
#
5,出竅:業務最佳化及伺服器架構調整
快速發展的業務對我們的系統各項指標也有了更高的要求,首先是伺服器端回應時間。
APP兩大核心功能模組,Feed流及正文的響應速度對整體的用戶體驗是有很大影響的,根據領導的要求,首先我們有了前期目標,Feed流平均響應時長100ms,當時Feed整體響應時間大約為500-700ms左右,可謂任重道遠!
Feed流業務複雜,依賴很多數據資源,如即時廣告,個性化,評論,圖床轉圖,焦點圖,固定位置投放等,有一些資源不能進行緩存,對於實時計算數據,不能依賴緩存,我們只能另闢蹊徑,透過其他途徑解決。
首先我們和維運一起對伺服器軟體系統環境進行了整體升級,把Nginx升級到了Tengine,然後把PHP進行了版本升級,升級玩效果還算比較明顯,整體響應時間減少了20%左右,到了300- 400ms,雖然效能有了提升但是離目標還有很遠。優化繼續,我們對Feed整個業務環節進行打點記錄日誌分析,找出最消耗效能的地方,各個擊破。
原有伺服器結構如下:
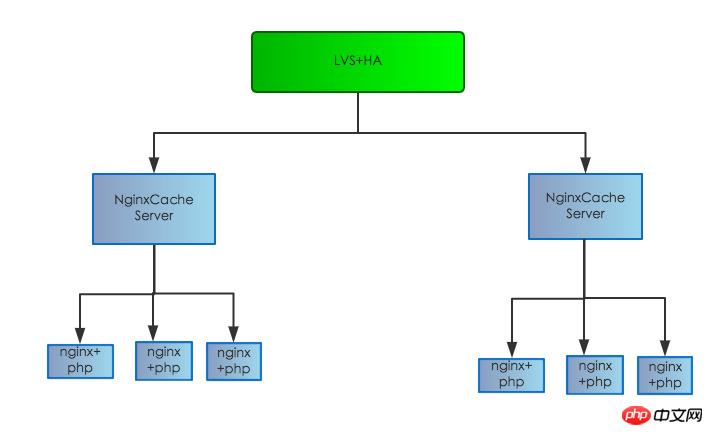
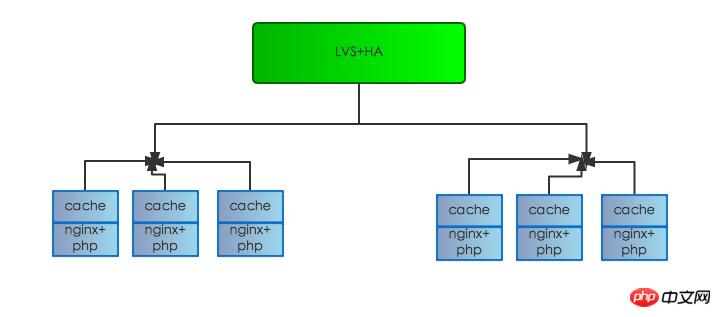
伺服器結構調整完畢,Feed回應時間也大大下降,效能提昇明顯,到了200-350ms左右。離設定目標接近,但仍沒有達成設定目標。
一天我們的工程師在調試程式碼時偶然發現一個問題,PHP-CURL設定的毫秒級超時時間無效,我們透過大量測試驗證PHP預設自帶的CURL庫果然不支援毫秒,透過查詢PHP官方文件發現舊版的PHP libcurl庫存在這個問題【後來發現公司內絕大部分業務的PHP版本環境都存在這個問題】這就意味著我們在系統中做的大量依賴接口超時時間精確控制都沒有生效,也是造成系統性能遲遲上不去的一個重要原因,把這個問題解決,對整體性能提升勢必會帶來很大提升,馬上我們和維運同學一起開始進行線上灰度驗證測試,通過幾天的線上測試,沒有發現其他問題,並且性能果真有很大提升,我們就逐步擴大範圍,直至上線到所有服務器,通過數據表明 libcurl 版本庫升級後,沒有做其他任何優化的情況下服務器Feed響應時間直接到了100- 150ms左右,非常明顯。
伺服器結構層,軟體系統環境層能做的都做了,但是還沒有達成設定的Feed平均回應時間100ms的要求,只能從業務代碼入手了,當時線上Feed流請求依賴資源是順序執行,一個資源發生擁堵,會導致後面請求排隊,造成整體回應時間增加。我們就開始嘗試把PHP CURL 改成多線程並發請求,把串行改為並行,同時請求多個依賴的資源接口,無需等待,通過小伙伴的技術攻關,把CURL類庫進行了重寫,為避免問題,我們有進行了長時間大量灰度測試驗證,測試通過,發佈到線上生產環境,同時小伙伴們的努力也得到了回報,服務器Feed流響應時間直接下降到了100ms以下,同時正文介面的平均回應時間控製到了15ms以內。
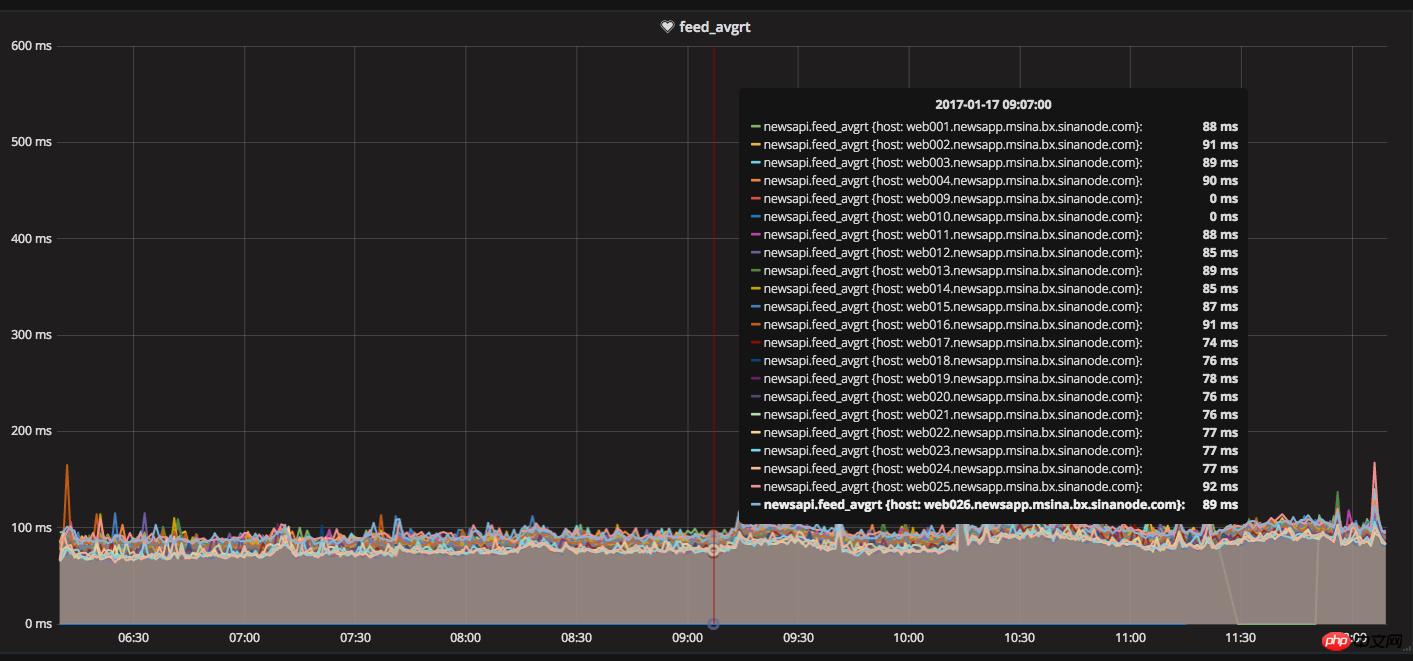
Feed串流回應時間
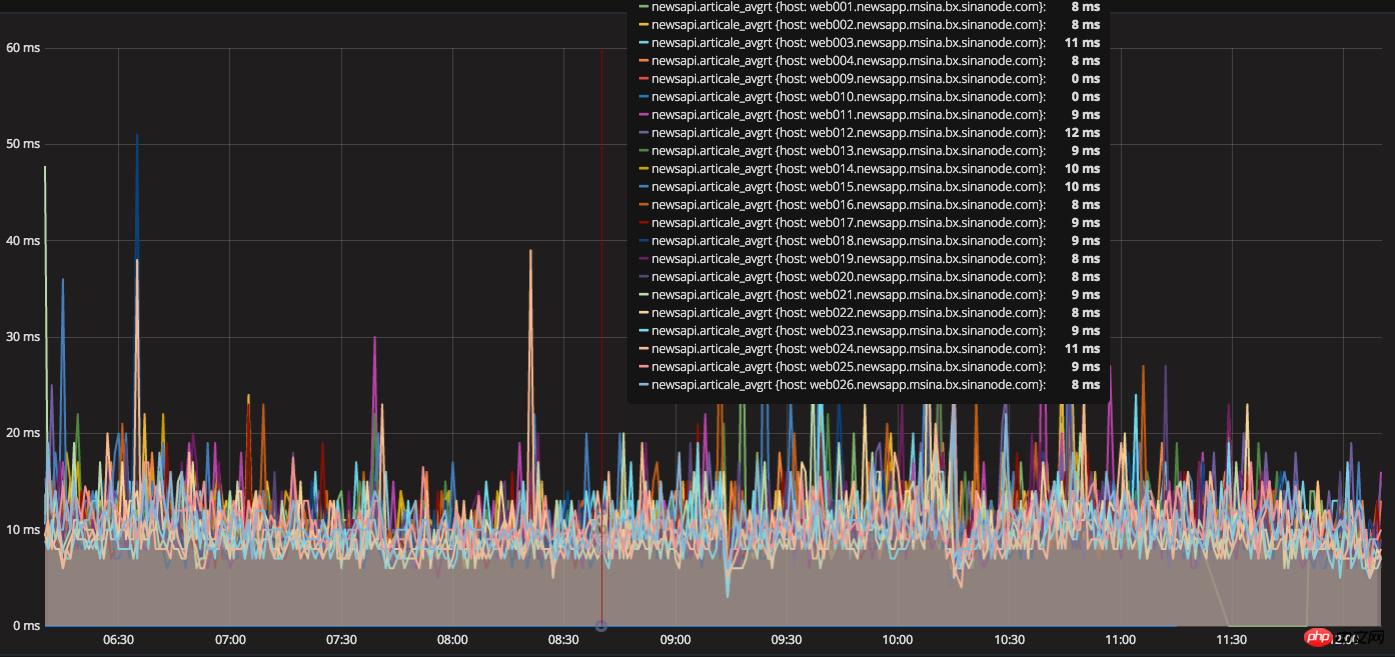 正文平均回應時間
正文平均回應時間
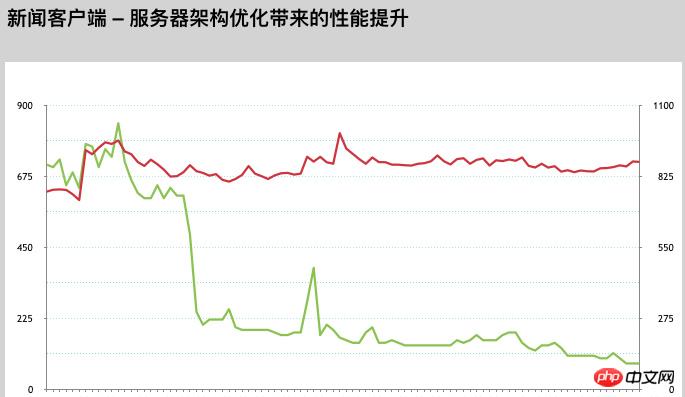
# 後續我們又對伺服器進行了各機房分散式部署,重新分配VIP網路存取節點,優化網路呼叫資源,避免用戶跨運營商、跨南北訪問可能對用戶體驗造成的不良影響。
透過上面的大量最佳化調整,我們的整個系統承載能力也得到了很大提升。
目前高峰QPS達13.4萬,日最高請求HIT數達8億左右,量等級已非常可觀。
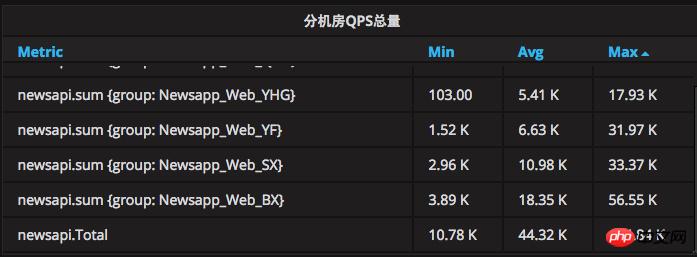
# 單機的QPS承載量也有了很大提升,原來單機 500-800QPS 系統就已滿載,到現在單機 2.5K系統依舊堅如磐石、微絲不動。
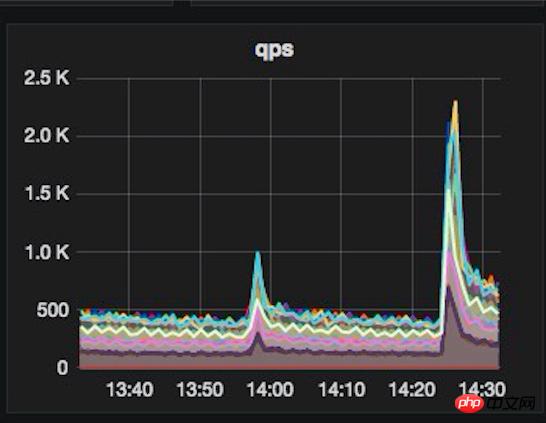
# 感謝團隊內小夥伴持續不懈的努力,同時也感謝維運同學對我們的大力協助,讓新聞APP接口系統的性能及抗負載能力得到了很大提升。
#
6,渡劫:服務治理平台
# 運籌帷幄方能決勝千里。
新聞APP介面目前依賴第三方介面及資源上百個,一旦某個或多個介面及資源發生問題,容易對系統可用性造成影響。
基於這種情況我們設計開發了本系統,主要係統模組如下:
服務自我保護,服務降級,錯誤分析及呼叫鏈監控,監控與警報。自建離線資料中心,依賴資源生命探測系統,介面存取調度開關,離線資料中心即時收集關鍵業務數據,生命探測系統即時偵測資源健康及可用性,介面存取調度開關控制對介面的請求,一旦生命探測系統偵測到某個資源有問題,就會自動透過介面存取控制開關進行降級降頻次訪問,同時自動延長資料快取時間,生命探測系統持續偵測資源健康度,一旦資源完全不可用,控制開關就會完全關閉介面請求存取進行自動服務降級,同時啟用本地資料中心,把資料提供給使用者。等生命探針偵測到資源可用後,恢復呼叫。 本系統多次成功避免了重度依賴資源【如CMS,評論系統,廣告等】故障 對新聞用戶端服務可用性的影響,依賴資源發生故障,業務反應到使用者端基本無感知。同時我們建立了完善的異常監控 錯誤分析及呼叫鏈監控 體系,保障在第一時間預知、發現、並解決問題 【在第7服務端高可用有詳述】。
同時客戶端業務持續快速發展,各功能模組更新迭代也很快,為了滿足快速迭代同時又不能出現任何嚴重程式碼問題,我們也增加了程式碼灰階與發布流程。新功能上線先進行灰階驗證,驗證通過之後上線至全量,同時預留新舊切換模組,新功能一旦出現問題,隨時切換到舊版,保障服務正常。
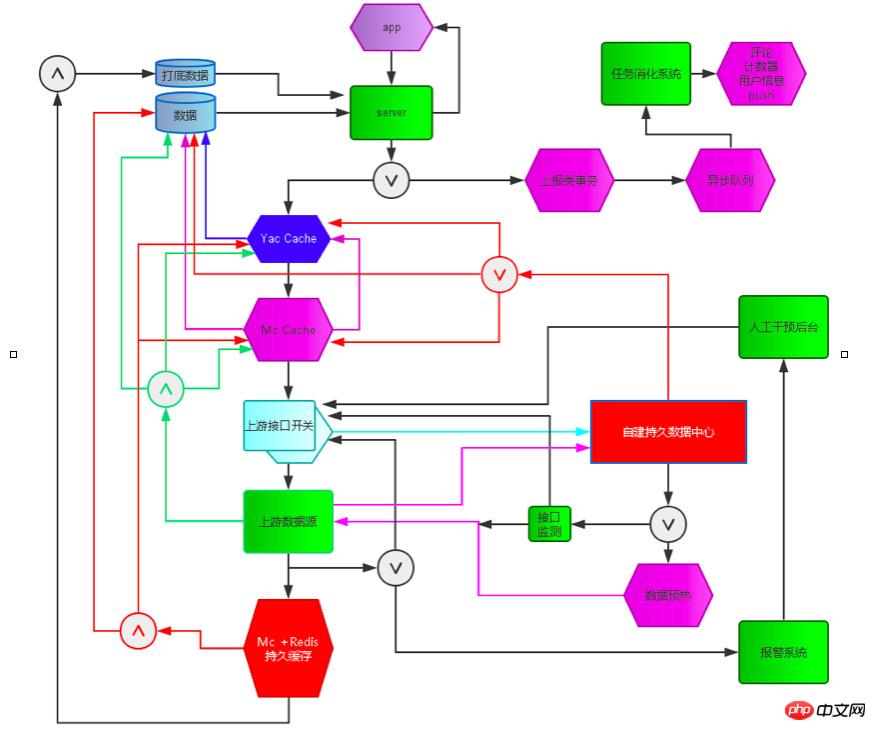 服務治理平台技術實作
服務治理平台技術實作
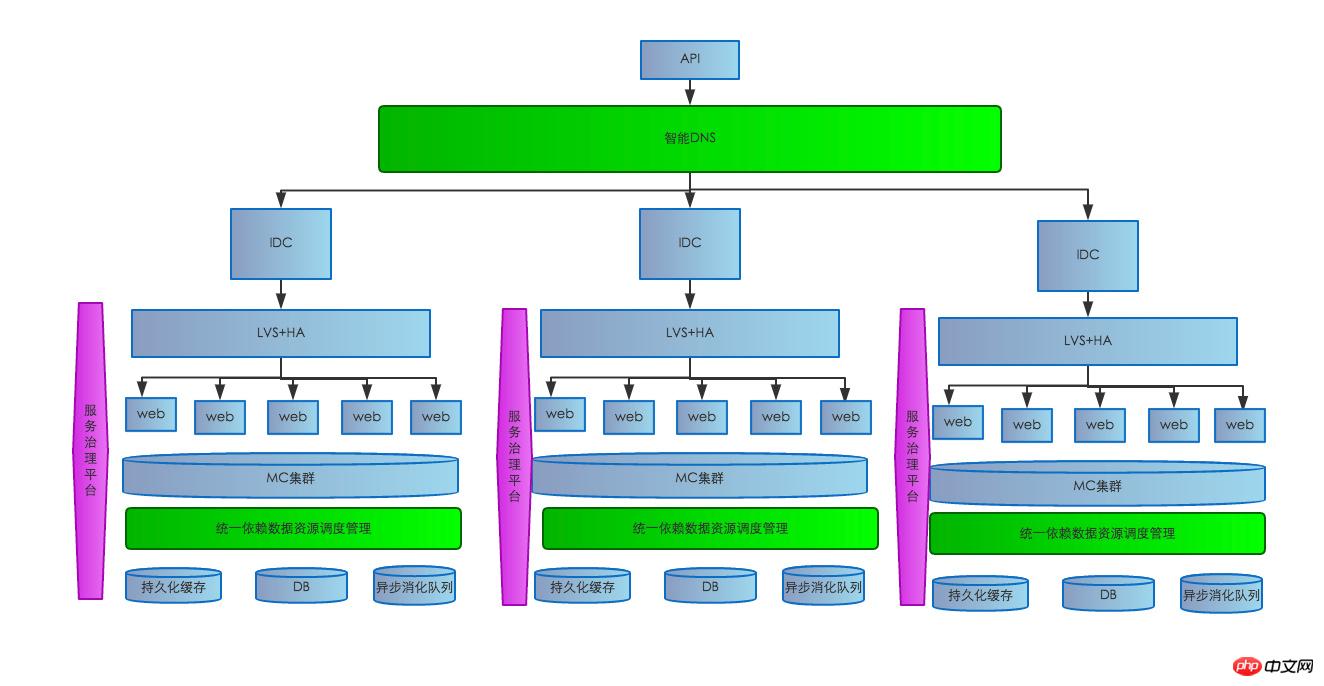
# 服務治理平台建置完畢之後,我們的系統服務架構大概如下:
##
7,大乘:服務端高可用
# 高可用性,目前高併發大流量WEB服務系統中最受關注的問題之一。高可用性設計是個系統工程,其內容涉及(網路、伺服器硬體、Web服務、快取、資料庫、依賴上游資源,日誌,監控,警報 ,自我保護,容災,快速處理復原)等多面向問題。
高可用性的定義:
系統可用性(Availability)的定義公式為:Availability = MTBF / ( MTBF + MTTR ) × 100%
# MTBF(Mean Time Between Failure),即平均故障時間,是描述整個系統可靠性(reliability)的指標。對一個大型Web系統來說,MTBF是指整個系統的各業務不間斷無故障連續運作的平均時間。
MTTR(Mean Time to Repair),即係統平均恢復時間,是描述整個系統容錯能力(fault-tolerant capability)的指標。
對於一個大型Web系統來說,MTTR是指當系統中的元件發生故障時,系統從故障狀態恢復到正常狀態所需的平均時間。
### 從公式可看出,提高MTBF或降低MTTR都能提高系統可用性。 ###那麼問題就來了,要怎麼透過這兩個指標來提升系統可用性呢?
透過上面的定義我們可以看到,高可用的一個重要因素: MTBF 是系統可靠度【平均故障時間】。
那我們就列一下都哪些問題會影響MTBF,可能的因素有:1,伺服器硬件,2,網絡,3,資料庫,4、緩存,5,依賴資源,6,代碼錯誤,7,突發大流量高並發 只要解決好這些問題,就可以避免故障從而提升MTBF。
根據這幾個問題,那新聞客戶端目前是怎麼做的呢?
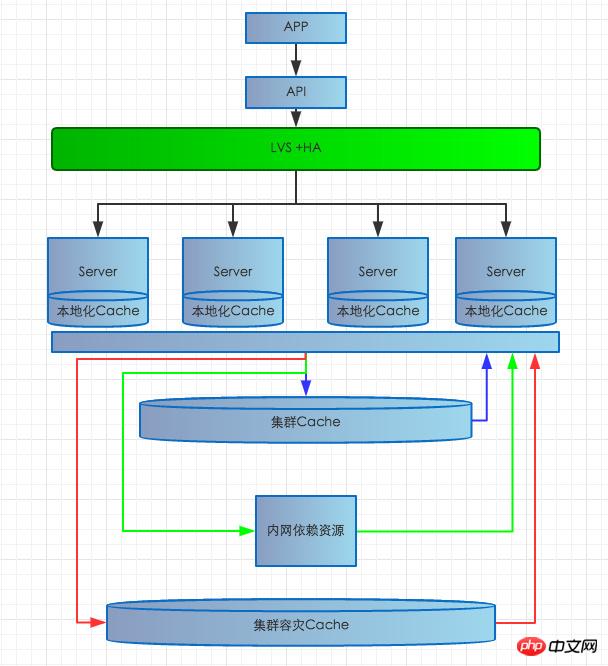
第一個伺服器硬體故障:如果一台伺服器硬體故障會造成這台伺服器上服務不可用,如下圖結構,目前系統是LVS+HA上掛多台MEM伺服器,LVS+HA上有生命探測系統,如果偵測到異常,會從負載平衡及時摘除,避免使用者造訪到問題伺服器造成故障。
第二個內部網路問題:如果發生大規模內部網路故障,一連串的問題,如會造成讀取依賴資源失敗,存取資料庫失敗,讀寫Cache叢集失敗等,影響範圍比較大,後果比較嚴重。那我們就在此次多做一些文章,一般網路問題,主要發生在跨機房訪問擁堵,或者不通。同機房網路不通的情況極為少見。因為有些依賴介面分佈在不同的機房,跨機房網路問題主要會影響依賴介面回應慢或超時,這種問題我們採取多層快取策略,一旦依賴的跨機房介面異常,優先取實時本地化緩存,如果本地化緩存穿透,立刻去拿本機房Cache集群實時緩存,如果集群實時緩存穿透,就取本機房持久化防禦緩存,極端惡劣條件下,持久緩存無命中,那備用數據源返回給用戶,同時預熱備用資料源只持久緩存,讓用戶無感知,避免大範圍故障發生。針對資料庫因網路問題導致延遲的問題,我們主要採取非同步佇列寫入,增加蓄水池,防止資料庫寫入發生擁堵,影響系統穩定性。
第六個程式碼錯誤:以前也發生過因程式碼錯誤造成線上故障血淋淋的案例,而且很多問題都是低階錯誤導致,所以我們也專注於這方面做了大量工作。
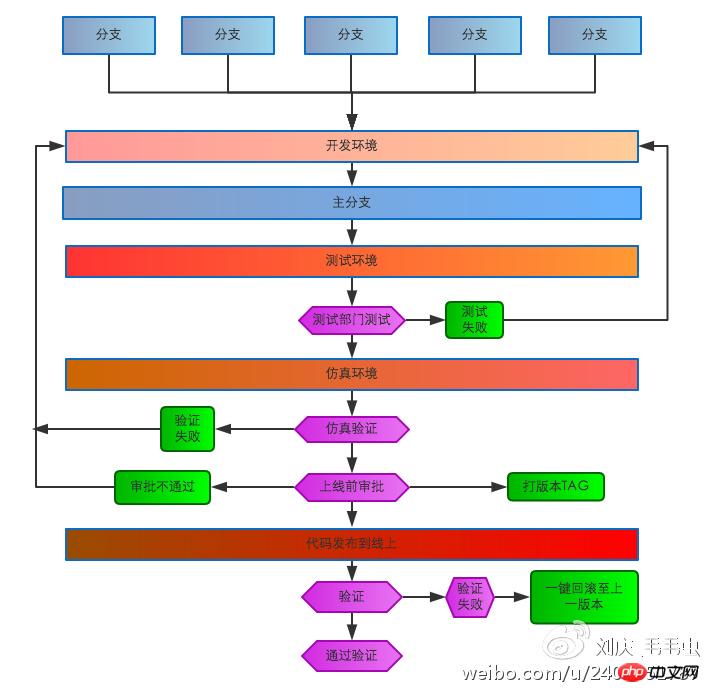
首先要規範化程式碼開發、發布流程,隨著業務成長,系統穩定性可靠性要求也日益增高,開發團隊人員也在增加,已經不能像那種刀耕火種、單打獨鬥的原始社會狀態,所有操作都需做到標準化、流程化。
我們完善了:開發環境,測試環境,模擬環境 , 線上環境 及上線流程。工程師在開發環境自測完畢,提到測試環境,測試部門來進行測試,測試通過之後,提至仿真環境,進行仿真測試,測試通過提至上線系統,上線系統需經過管理員審批通過之後方可以上線,上線完畢進行線上迴歸驗證,驗證通過,程式碼上線流程關閉,如驗證失敗,透過上線系統一鍵回滾至上線前環境。
 程式碼開發及發布流程
程式碼開發及發布流程
那針對第七條:突發大流量高並發我們是怎麼處理的呢?
突發大流量一般我們的定義為,短時間內 熱點及突發事件瞬間帶來大量訪問請求,遠超出系統軟硬體預期負載範圍,如果不做處理可能會對整體服務造成影響。這種情況持續時間比較短,如果臨時新增上線機器已經來不及,等機器上線完畢,流量高峰已過,就變的毫無意義了。如果隨時在線上準備大量備機,那麼平時 99%的時間這些機器都會處於空閒狀態,會浪費大量財力物力資源。
遇到這麼情況我們就需要一個完善的流量調度系統及服務熔斷限流措施。如果突發大流量來自於某些特定區域,或都集中在某個或多個IDC機房,可以把負載較高的機房流量切分一部分至流量空閒機房,一起來分擔壓力。但是如果切分流量不足以解決問題,或所有機房流量負載都比較高,那我們只能透過熔斷限流來保護整體系統服務,首先按照業務模組優先級進行排序,按照低優先級的業務進行依次降級,如果業務降級仍無法解決問題,那就開始依序停用低優先級業務,保住重要功能模組繼續對外服務,極端情況下業務降級不能挺過流量高峰,那我們就採取限流保護措施,暫時捨棄少部分用戶,來保住大部分高價值用戶的可用性。
高可用還有一個重要指標,MTTR 系統平均恢復時間,就是服務出了故障之後多久能夠恢復。
解決這個問題主要有以下幾點:1,發現故障,2,定位故障原因,3,解決故障
這個三點同等重要,首先要及時發現故障,其實出現問題了並不可怕,可怕的是我們很久都沒有發現問題,造成大量用戶流失這才是最嚴重的。那麼怎麼來及時發現故障呢?
監控系統是整個系統環節,甚至整個產品生命週期中最重要的一環,事前及時預警發現故障,事後提供詳細的數據用於追蹤定位問題。
首先要有完善的監控機制,監控是我們的眼睛,但有監控還不夠,還需要及時發出警報,出了問隨時通知相關人員及時處理。在這方面,我們在維運部門的支持下建立了配套監控警報體系。
一般而言一個完善的監控系統主要有這五個面向:1.系統資源,2.伺服器, 3.服務狀態,4.應用異常,5.應用效能,6,異常追蹤系統
# 1,系統資源監控
監控各種網路參數和各伺服器相關資源(cpu,內存,磁碟,網絡,存取請求等),保證伺服器系統的安全運作;並提供異常通知機制以讓系統管理員快速定位/解決存在的各種問題。
2,伺服器監控
伺服器的監控,主要是監控各伺服器,網路節點,網關,等網路設備,的請求回應是否正常。透過定時服務,定時去ping各個網路節點設備,以確認各網路設備是否正常,,若哪個網路設備出現異常,則發出訊息提醒。
3,服務監控
服務監控,指的是各個web服務等平台系統的各項服務是否正常運行,可以透過定時服務,每隔一段時間,就去請求相關的服務,確保平台的各項服務正常運作。
4,應用異常監控
主要有異常逾時日誌,資料格式錯誤,等
5,應用效能監控
監控主要業務的反應時間指標是否正常,顯示主要業務績效曲線走勢,及時發現及預測可能出現的問題。
6,異常追蹤系統
異常追蹤系統主要來監控整個系統上下游依賴的資源,透過監控依賴資源的健康狀況如:反應時間變化,超時率變化等,來對整個系統可能出現的風險做出提前評判及提前處理。也可以對已經發生的故障做到快速定位,是否為某個依賴資源問題導致,來迅速解決故障。
我們目前線上使用的主要監控系統如下:
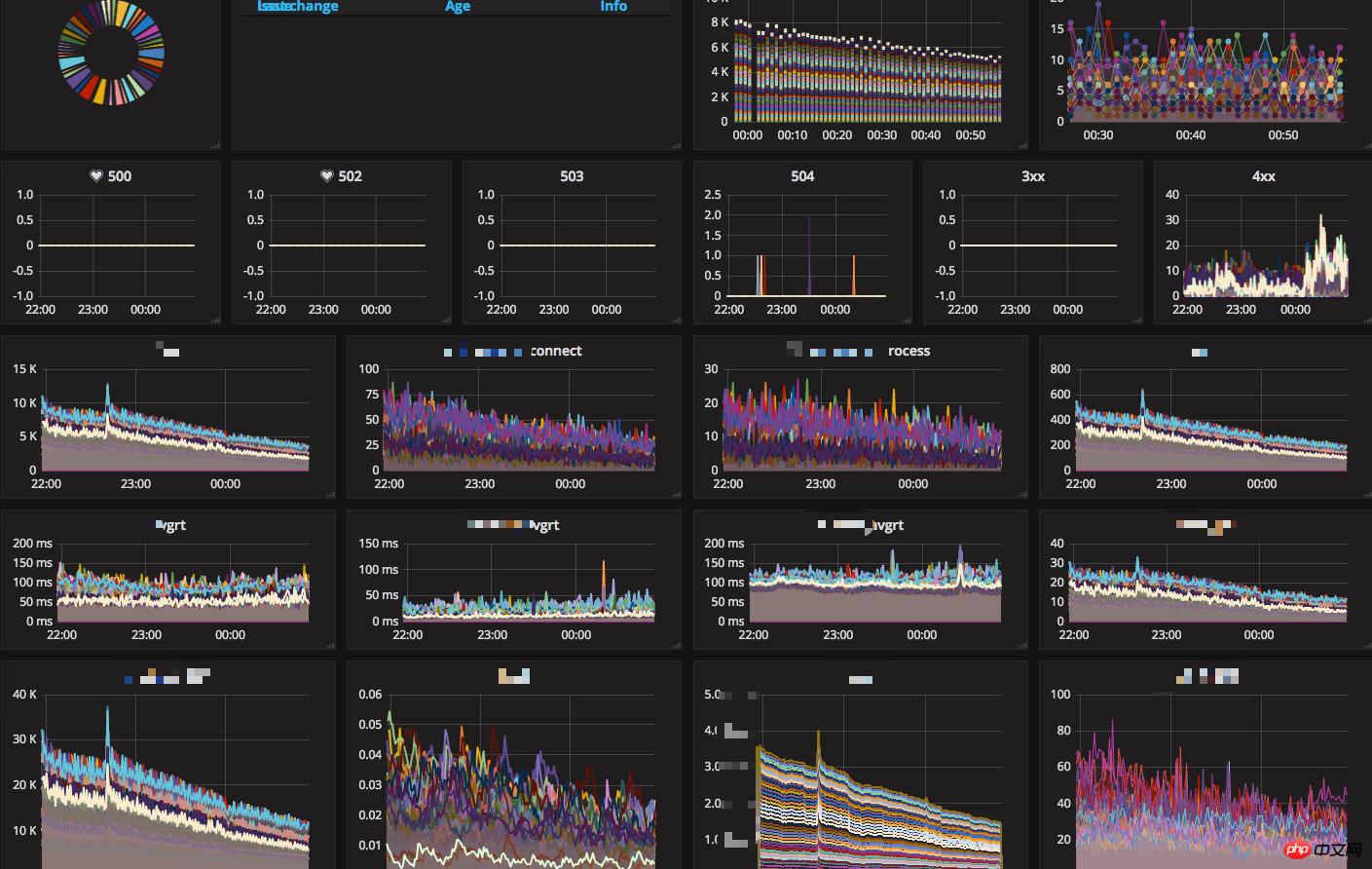 新聞APP後端系統架構成長之路 - 高可用架構設計圖文詳解
新聞APP後端系統架構成長之路 - 高可用架構設計圖文詳解
 #依賴資源逾時監控
#依賴資源逾時監控
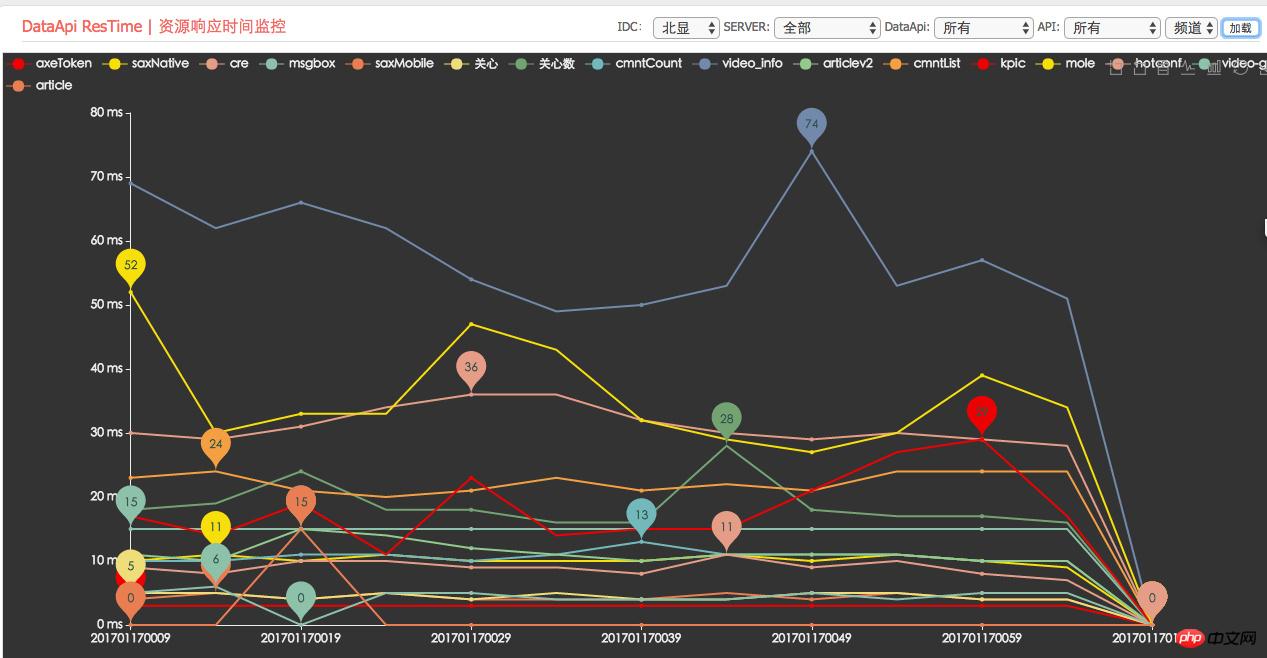 依賴資源平均回應時間監控
依賴資源平均回應時間監控
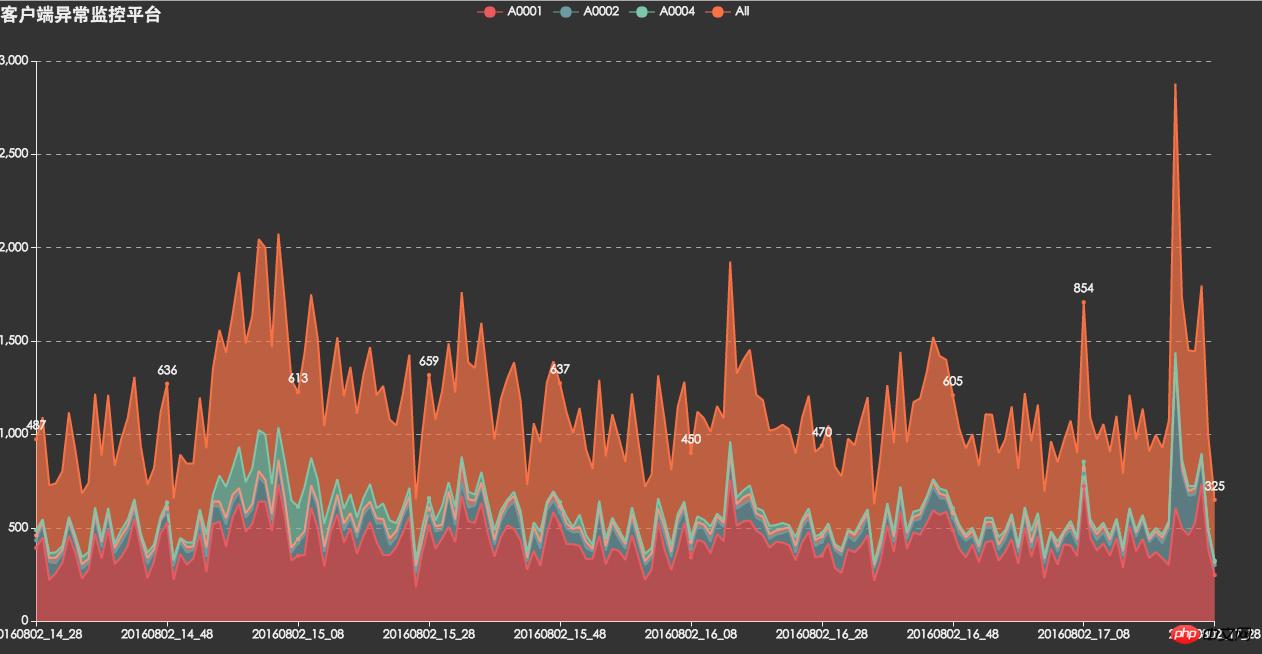 API錯誤監控
API錯誤監控
註:【引用、學習】評斷一個監控系統的好壞主要有以下兩點:1,細緻入微,2,一目了然 。這兩個看似互相衝突,既然細緻入微一定會有很多很多的監控項目,一定做不到一目了然,其實不然。一目了然主要是能及時發現是否有問題,因為不可能有那麼多時間和精力一直盯著幾百個監控圖表來看。那就需要一個完善的 新聞APP後端系統架構成長之路 - 高可用架構設計圖文詳解 總結各項指標是否正常,列出異常指標一目了然發現問題。而細緻入微主要是出現問題後為排除問題點做準備,可以檢查各項監控資料點是否正常,來快速定位問題。
8,飛升:用戶端高可用
【2017年重要目標,用戶端高可用】
最近網路媒體談論HTTPS 的文章很多,原因之一是營運商作惡底線越來越低,動不動就插播廣告, 前些天幾家網路公司聯合發文關於抵制流量劫持等違法行為的聯合聲明痛斥某些運營商。 另一方面也是蘋果 ATS 政策的大力推動,逼迫大家在 APP 中全部使用 HTTPS 通訊。 上 HTTPS 的好處很多:保護用戶的數據不外洩,避免中間人篡改數據, 對企業資訊進行鑑權。 儘管使用了 HTTPS 技術,部分邪惡的運營商,會在HTTPS之前攔一刀,使用 DNS 污染技術,讓域名指向的他們自己服務器 ,進行DNS劫持。 ###### 這個問題不解決,即使HTTPS 的話也不能從根本上解決問題,仍然會有很多用戶的訪問出現問題。輕則對產品不信任,重則直接導致使用者無法使用產品,導致使用者流失。 ###那麼根據第三方數據,對於鵝廠這樣的網路公司來講,域名解析異常的情況到底有多嚴重呢?每天鵝廠的分散式網域解析監測系統都在不停地對全國所有的重點LocalDNS進行偵測,鵝廠網域在全國各地的日解析異常量是已經超過了80萬個。這給業務帶來了巨大的損失。
業者為了賺廣告錢、省網間結算是不擇手段的。 他們普遍使用劫持手段是透過 ISP提供 DNS 偽造網域名稱。
『其實我們也面臨同樣嚴峻的問題』
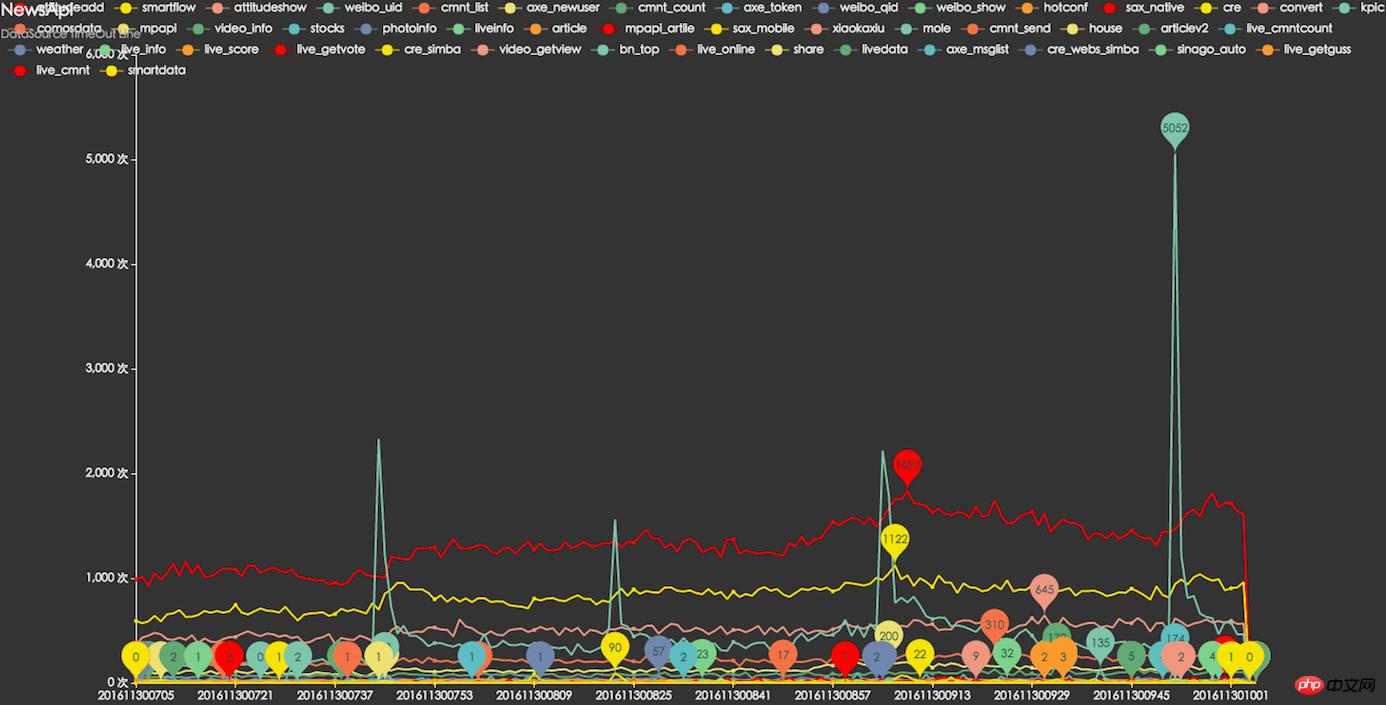
# 透過新聞APP端的日誌監控分析發現:有 1%-2%的使用者有DNS解析異常及介面存取不通的情況。
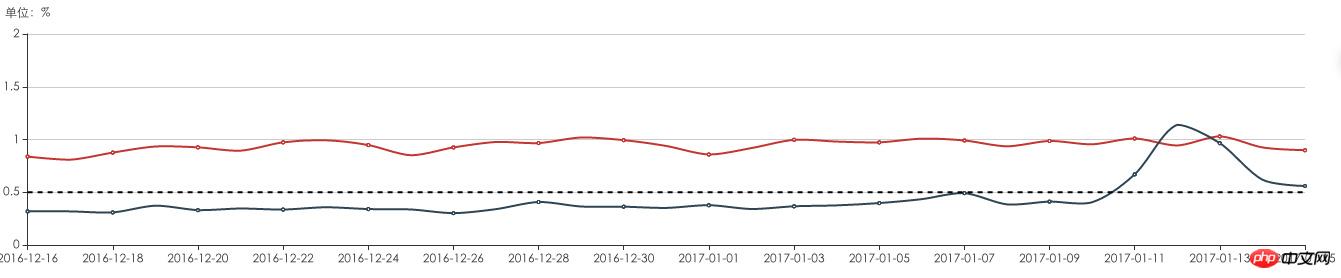
DNS異常,及無法存取介面
# 無形中造成大量用戶流失,特別是在業務飛速發展的時期對業務的體驗造成了非常大的損害。
那麼有沒有一種技術上的方案,能從根源解決網域解析異常及使用者存取跨網的問題和 DNS 劫持呢?
業界有套解決這類場景的方案,即HTTP DNS。
什麼是HttpDNS?
# HttpDNS基於Http協定向DNS伺服器發送網域名稱解析請求,取代了基於DNS協定向電信商LocalDNS發起解析請求的傳統方式,可以避免LocalDNS造成的網域名稱劫持和跨網存取問題,解決行動網際網路服務中網域解析異常帶來的困擾。
HttpDNS解決的問題?
HttpDNS主要解決三類問題:解決行動互聯網中DNS解析異常、LocalDNS網域劫持,平均回應 時間升高,使用者連線失敗率居高不下
1、DNS解析異常及LocalDNS劫持:
# 行動DNS的現況:運營商LocalDNS出口依據權威DNS目標IP位址進行NAT,或將解析請求轉送至其他DNS伺服器,導致權威DNS無法正確辨識業者的LocalDNS IP,引發網域名稱解析錯誤、流量跨網。
網域被劫持的後果:網站無法存取(無法連接伺服器)、彈出廣告、造訪釣魚網站等。
解析結果跨域、跨省、跨運營商、國家的後果:網站訪問緩慢甚至無法訪問。
# 由於HttpDNS是透過ip直接請求http取得伺服器A記錄位址,不存在向本地業者詢問domain解析過程,所以從根本避免了劫持問題。
2、平均存取回應時間升高: 由於是ip直接存取省掉了一次domain解析過程,透過智慧演算法排序後找到最快節點進行存取。
3、用戶連線失敗率下降: 透過演算法降低以往失敗率過高的伺服器排序,透過時間近期存取過的資料提高伺服器排序,透過歷史存取成功記錄提高伺服器排序。如果ip(a)存取錯誤,在下次傳回ip(b)或ip(c) 排序後的記錄。 (LocalDNS很可能在一個ttl時間內(或多個ttl)都是回傳記錄
HTTPS能最大限度的防止業者對流量劫持,包含內容安全不被竄改。
HTTP-DNS能解決用戶端DNS的問題,確保用戶請求直達,且自動直達回應最快的伺服器直達。
HttpDNS實作的原理?
# HTTP DNS 的原理很簡單,將 DNS 這種容易被劫持的協議,轉換為使用 HTTP 協議請求
DomainIP 對映。 在獲得正確 IP 之後,Client 自己組裝 HTTP 協議,從而避免 ISP 篡改資料。
客戶端直接存取HTTPDNS接口,取得網域的最優IP。 (基於容災考慮,保留使用運營商LocalDNS解析網域的方式作為備選。)
## 客戶端取得到業務IP後,就向直接往此IP發送業務協定請求。以Http請求為例,透過在header中指定host字段,向HTTPDNS傳回的IP發送標準的Http請求即可。

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 京東商城APP如何進行實名認證
Mar 19, 2024 pm 02:31 PM
京東商城APP如何進行實名認證
Mar 19, 2024 pm 02:31 PM
京東商城APP實名認證怎麼搞?京東商城是許多朋友常用的網路購物平台,大家在購物前,最好先進行實名認證,這樣才能享受到完整的服務,獲得更好的購物體驗。以下帶來京東商城實名認證方法,希望對網友們有幫助。 1.安裝並開啟京東商城,接著登入個人帳號;2、然後點選頁面下方【我的】,進入個人中心頁面;3、之後再點選右上角的【設定】小圖標,前往設定功能介面;4、選擇【帳號與安全】這一項,來到帳戶設定頁面;5、最後再點擊【實名認證】選項,前往填寫實名資訊;6、安裝系統要求填寫個人真實信息,完成實名認證
 註冊香港AppleID的步驟及注意事項(享受香港AppleStore的獨特優勢)
Sep 02, 2024 pm 03:47 PM
註冊香港AppleID的步驟及注意事項(享受香港AppleStore的獨特優勢)
Sep 02, 2024 pm 03:47 PM
在全球範圍內,Apple公司的產品和服務一直備受用戶喜愛。註冊一個香港AppleID將帶給用戶更多的便利和特權,讓我們一起來了解一下註冊香港AppleID的步驟以及需要注意的事項。如何註冊香港AppleID在使用蘋果設備時,許多應用程式和功能都需要使用AppleID進行登入。如果您想下載香港地區的應用程式或享受香港AppStore的優惠內容,那麼註冊一個香港AppleID就非常必要。本文將詳細介紹如何註冊香港AppleID的步驟以及需要注意的事項。步驟:選擇語言與地區:在蘋果設備上找到「設定」選項,進入
 中國聯通app怎麼退訂流量包 中國聯通怎樣退訂流量包
Mar 18, 2024 pm 10:10 PM
中國聯通app怎麼退訂流量包 中國聯通怎樣退訂流量包
Mar 18, 2024 pm 10:10 PM
中國聯通app能夠輕鬆的滿足大家的使用,多樣的功能,解決你們的需求,想要辦理各種業務,都可以在這裡輕鬆的搞定,有不需要的都可以在這裡及時的退訂掉,有效的避免後續的損失,很多人在使用手機時,有時感覺流量不夠用,就購買了額外的流量包,但下個月又不想要要,就想要馬上的退訂掉,在這裡小編為大家提供退訂的方法,讓需要的朋友們,都可以來使用起來! 在中國聯通app中,找到右下角的「我的」選項,點擊它。 在我的介面裡,滑動我的服務一欄,點擊其中的「我已訂購」選
 app全名是啥
Aug 21, 2023 am 10:29 AM
app全名是啥
Aug 21, 2023 am 10:29 AM
app全名為“Application”,即應用程式的縮寫,是指針對行動裝置開發的一種軟體應用。 app的出現為使用者提供了更多種類的行動應用程式選擇,滿足了使用者在不同場景下的各類需求。 app的開發過程涉及軟體設計、程式設計、測試等多個環節,同時也需要考慮設備相容性、效能最佳化、安全性等方面的問題。
 多點app如何開發票
Mar 14, 2024 am 10:00 AM
多點app如何開發票
Mar 14, 2024 am 10:00 AM
發票作為購物憑證,對於我們的日常生活和工作都至關重要。那麼我們平常在使用多點app進行購物的時候,如何在多點app中輕鬆開立發票呢?下文中本站小編將為大家帶來詳細的多點app開立發票詳細操作步驟攻略,想要了解的用戶們千萬不容錯過,快來跟著文本一起操作了解一下吧!在【發票中心】點選【多點超市/自由購】在已完成的訂單頁中選擇需要開立發票的訂單,點選下一步填寫【發票資訊】,【收件者資訊】,確認無誤後點選提交過個幾分鐘後,進入收件信箱,打開郵件,點選電子發票下載地址最後,下載列印電子發票
 Blackmagic 的專業級視訊應用程式登陸 Android,但您的手機可能無法運行它
Jun 25, 2024 am 07:06 AM
Blackmagic 的專業級視訊應用程式登陸 Android,但您的手機可能無法運行它
Jun 25, 2024 am 07:06 AM
Blackmagic Design 終於將其廣受好評的 Blackmagic Camera 應用程式帶到了 Android 平台。專業攝影機應用程式可免費下載,並提供完整的手動控制。這些控制旨在讓您更輕鬆地獲得專業級 cin
 此應用程式需要Windows應用程式運行時
Feb 28, 2024 pm 05:37 PM
此應用程式需要Windows應用程式運行時
Feb 28, 2024 pm 05:37 PM
WindowsAppRuntime或WinRT就像微軟建立的工具箱。它幫助開發人員在許多設備上建立和運行應用程序,如電腦、平板電腦、手機、Xbox等。在執行應用程式時,如果您收到此應用程式需要WindowsAppRuntime的錯誤訊息,請遵循此貼文以解決該問題。為什麼會出現此錯誤? WindowsAppRuntime是一個強大的工具,可以幫助開發人員在各種裝置上建置和運行應用程序,包括電腦、平板電腦、手機、Xbox和HoloLens。如果您收到提示需要WindowsAppRuntime來執行
 MongoDB與邊緣運算的結合實作與架構設計
Nov 02, 2023 pm 01:44 PM
MongoDB與邊緣運算的結合實作與架構設計
Nov 02, 2023 pm 01:44 PM
隨著物聯網和雲端運算的快速發展,邊緣運算逐漸成為新的熱點。邊緣運算是指將資料處理和運算能力從傳統的雲端運算中心轉移到實體設備的邊緣節點上,以提高資料處理的效率和減少延遲。而MongoDB作為一種強大的NoSQL資料庫,其在邊緣運算領域的應用也越來越受到重視。一、MongoDB與邊緣運算的結合實務在邊緣運算中,設備通常具有有限的運算與儲存資源。而MongoDB
