

Java異常模型的詳細介紹與分析(圖)

一.異常的引入及基礎
發現錯誤的理想時機是在編譯階段,也就是在你試圖執行程式之前。然而,編譯期間編譯器並不能找出所有的錯誤,餘下的錯誤只有在運行期才能發現和解決,這類錯誤就是 Throwable。 這就需要錯誤來源能夠透過某種方式,把適當的訊息傳遞給某個接收者,該接收者將知道如何正確的處理這個問題,這就是Java的錯誤報告機制—— 異常機制。這個機制使得程式把 在正常執行過程中做什麼事的程式碼 與 出了問題怎麼辦的程式碼 分開。
在對異常的處理方面,Java 採用的是 終止模型# 。 在這種模型中,將假設錯誤非常關鍵,以至於程式無法回到異常發生的地方繼續執行。一旦異常被拋出,就表示錯誤已經無法挽回,也不能回來繼續執行。 相對於終止模型,另一種異常處理模型為 恢復模型,它使異常被處理後能夠繼續執行程式。雖然模型很吸引人,但不是很實用,其主要原因是它所導致的耦合:恢復性處理程序需要了解異常的拋出地點,這勢必要包含依賴於拋出位置的非通用代碼,從而大大增加了程式碼編寫和維護的難度。
在異常情況中,異常的拋出伴隨著以下三件事的發生:
二. Java 標準異常1.
# #異常類別層次結構範例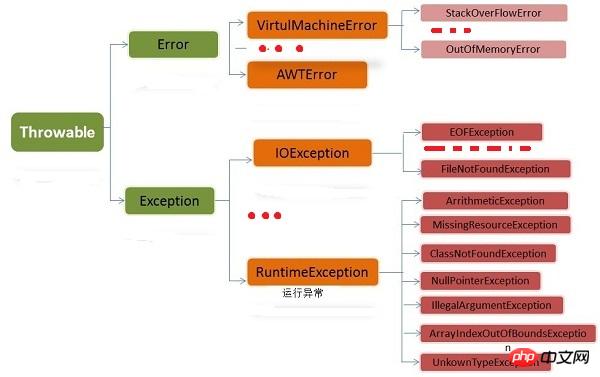
- Throwable:所有的例外類型的根類別
在 Java 中,Throwable 是所有的例外類型的根類別。
Throwable 有兩個直接子類別:Exception 和 Error。二者都是 Java 異常處理的重要子類,各自包含大量子類。
- Error:程式本身無法處理的錯誤
Error 是程式無法處理的錯誤,表示執行應用程式中較嚴重問題。
這些錯誤大部分與程式碼編寫者執行的操作無關,而是與程式碼執行時的 JVM 、資源等有關。例如,Java虛擬機器執行錯誤(Virtual MachineError),當 JVM 不再有繼續執行作業所需的記憶體資源時,就會出現 OutOfMemoryError。這些異常發生時,Java虛擬機器(JVM)一般會選擇執行緒終止。 這些錯誤是不可查的,並且它們在應用程式的控制和處理能力之外。 在 Java 中,錯誤透過Error的子類別來描述。
Exception:程式本身可以處理的錯誤- #
Exception 通常是Java程式設計師所關心的,其在Java類別庫、使用者方法及執行時間故障中都可能拋出。它由兩個分支組成: 運行時異常(派生於RuntimeException 的異常)# 和其他異常 。 分割這兩個例外的規則是:由程式錯誤(一般是邏輯錯誤,如錯誤的型別轉換、陣列越界等,應該避免)導致的異常屬於RuntimeException;而程式本身沒有問題,但由於諸如I/O這類錯誤(eg:試圖開啟一個不存在的檔案)所導致的異常就屬於其他異常。
此外,Java的例外(包括Exception和Error)通常可分為 受檢查的例外(checked exceptions) 和不受檢查的異常(unchecked exceptions)# 兩種類型。
-
不受檢查異常:派生於Error 或RuntimeException 的所有異常
不可查異常是編譯器不要求強制處理的異常,包括運行時異常(RuntimeException與其子類別)和錯誤(Error)。也就是說,當程式中可能出現這類異常,即使沒有用try-catch語句捕獲它,也沒有用throws子句聲明拋出它,也會編譯通過。
-
受檢查例外:除去所有不受檢查例外的例外
受檢查例外是編譯器要求必須處理的異常。 這裡所指的處理方式有兩種: 捕獲並處理異常#和聲明拋出異常 。也就是說,當程式中可能出現這類異常,要么用 try-catch 語句捕獲它,要么用 throws 子句聲明拋出它,否則編譯不會通過。
#:如果程式出現RuntimeException異常,那麼一定是程式設計師的問題
異常與錯誤的差別:異常能被程式本身處理,錯誤則無法處理
三. Java 例外處理機制
-
異常處理
在Java 應用程式中,例外處理機制為:拋出異常 與捕捉異常。
拋出異常: 當一個方法出現錯誤引發異常時,方法創建異常物件並交付運行時系統,異常物件中包含了異常類型和異常出現時的程式狀態等異常訊息。運行時系統負責尋找處理異常的程式碼並執行。擷取例外: 在方法拋出例外之後,執行時間系統將轉換為尋找合適的例外處理器(exception handler)。 潛在的異常處理器是異常發生時依序存留在呼叫堆疊中的方法的集合。 當異常處理器所能處理的例外類型與方法拋出的異常類型相符時,即為合適 的異常處理器。 執行階段系統從發生異常的方法開始,依序回查呼叫堆疊中的方法,直到找到含有合適異常處理器的方法並執行。當運行時系統遍歷呼叫堆疊而未找到合適的異常處理器,則運行時系統終止。同時,意味著 Java 程式的終止。
對於執行階段例外、錯誤或受檢查的例外,Java技術所要求的例外處理方式有所不同:
由於執行階段異常是不受檢查的,Java規定:執行階段例外將由Java執行時間系統自動拋出,允許應用程式忽略執行時間異常;
對於方法運行中可能出現的Error,當運行方法不欲捕捉時,Java允許該方法不做任何拋出聲明。因為,大多數Error是不可恢復的,也屬於合理的應用程式不該捕捉的異常;
-
對於所有受檢查的異常,Java規定:異常必須被捕捉,或進行異常說明。也就是說,當一個方法選擇不捕捉可查異常時,它必須聲明將拋出異常;
任何Java程式碼都可以拋出例外,如:自己寫的程式碼、來自Java開發環境包中程式碼,或是Java執行時間系統。無論是誰,都可以透過Java的 throw 語句拋出異常。
整體來說,Java規定:對於可查異常必須捕捉、或宣告拋出。允許忽略不可查的 RuntimeException 和 Error。
2、 例外說明
# 對於受檢查例外而言, Java提供了對應的語法,使你能告知客戶端程式設計師某個方法可能會拋出的異常類型,然後客戶端程式設計師就可以進行對應的處理。這就是異常說明,它屬於方法聲明的一部分,緊跟在形式參數列表之後,如下面的程式碼所示:
void f() throws TooBig, TooSmall, pZero { ... }表示方法f 可能會拋出TooBig, TooSmall, pZero三種異常,而
void g() { ... ... }表示方法g 不會拋出任何例外。
程式碼必須與例外說明一致。 若方法中的程式碼產生了受檢查異常卻沒有進行處理,編譯器就會發現這個問題並提醒你:要嘛處理這個異常,要嘛在異常說明中表示此方法將產生異常。 不過,我們可以宣告方法將拋出異常,但實際上並不會拋出。
3、捕獲異常
監控區域:它是一段可能產生異常的程式碼,並且後面跟著處理這些異常的程式碼,由try…catch… 子句 實作。
(1) try 子句
如果方法內部拋出了異常,這個方法將在拋出異常的過程中結束。若不希望方法就此結束,可以在方法內設定一個特殊的區塊來捕捉異常。其中,在這個區塊裡,嘗試各種方法呼叫的部分稱為try 區塊:
try {
// Code that might generate exceptions } (2) catch 子句– 例外處理程序
拋出的例外必須處理,而且針對每個要捕獲的異常,都必須準備相應的異常處理程序。 異常處理程序必須緊接在try區塊之後,以catch 關鍵字表示:
try {
// Code that might generate exceptions } catch(Type1 id1)|{
// Handle exceptions of Type1 } catch(Type2 id2) {
// Handle exceptions of Type2 } catch(Type3 id3) {
// Handle exceptions of Type3 } 異常處理程序可能用不到識別碼(id1,id2, …),因為異常的類型本身就已經給出了足夠的資訊來處理異常,但標識符不可省。 當例外例外被拋出時,例外處理機制將負責搜尋參數與例外類型相符的第一個處理程序。然後進入對應的catch自居執行,此時認為異常得到處理。一旦catch子句結束,則處理程序的尋找結束(與 switch…case…不同)。
特別需要注意的是:
異常匹配原則:#拋出例外時,異常處理系統會依照程式碼的書寫順序找出最近符合(衍生類別的物件可以符合其基底類別的處理程序)的處理程序。一旦找到,它就認為異常將得到處理,然後停止查找;
#不可屏蔽派生類別異常:捕獲基類異常的catch子句必須放在捕獲其衍生類別例外的catch子句之後,否則編譯不會通過;
catch子句必須與try子句連用。
(3) finally 子句
The finally Block Description
The finally block always executes when the try block exits. This ensures that the finally block is executed even if an unexpected exception occurs. But finally is useful for more than just exception handling — it allows the programmer to avoid having cleanup code accidentally bypassed by a return,continue, or break. Putting cleanup code in a finally block is always a good practice, even when no exceptions are anticipated.
Note: If the JVM exits while the try or catch code is being executed, then the finally block may not execute. Likewise, if the thread executing the try or catch code is interrupted or killed, the finally block may not execute even though the application as a whole continues.
finally 子句 总会被执行(前提:对应的 try子句 执行)
下面代码就没有执行 finally 子句:
public class Test {
public static void main(String[] args) {
System.out.println("return value of test(): " + test());
}
public static int test() {
int i = 1;
System.out.println("the previous statement of try block");
i = i / 0;
try {
System.out.println("try block");
return i;
}finally {
System.out.println("finally block");
}
}
}/* Output:
the previous statement of try block
Exception in thread "main" java.lang.ArithmeticException: / by zero
at com.bj.charlie.Test.test(Test.java:15)
at com.bj.charlie.Test.main(Test.java:6)
*///:~当代码抛出一个异常时,就会终止方法中剩余代码的执行,同时退出该方法的执行。如果该方法获得了一些本地资源,并且这些资源(eg:已经打开的文件或者网络连接等)在退出方法之前必须被回收,那么就会产生资源回收问题。这时,就会用到finally子句,示例如下:
InputStream in = new FileInputStream(...);try{
...
}catch (IOException e){
...
}finally{
in.close();
}finally 子句与控制转移语句的执行顺序
A finally clause can also be used to clean up for break, continue and return, which is one reason you will sometimes see a try clause with no catch clauses. When any control transfer statement is executed, all relevant finally clauses are executed. There is no way to leave a try block without executing its finally clause.
先看四段代码:
// 代码片段1
public class Test {
public static void main(String[] args) {
try {
System.out.println("try block");
return ;
} finally {
System.out.println("finally block");
}
}
}/* Output:
try block
finally block
*///:~// 代码片段2public class Test {
public static void main(String[] args) {
System.out.println("reture value of test() : " + test());
}
public static int test(){
int i = 1;
try {
System.out.println("try block");
i = 1 / 0;
return 1;
}catch (Exception e){
System.out.println("exception block");
return 2;
}finally {
System.out.println("finally block");
}
}
}/* Output:
try block
exception block
finally block
reture value of test() : 2
*///:~// 代码片段3public class ExceptionSilencer {
public static void main(String[] args) {
try {
throw new RuntimeException();
} finally {
// Using ‘return’ inside the finally block
// will silence any thrown exception.
return;
}
}
} ///:~// 代码片段4class VeryImportantException extends Exception {
public String toString() {return "A very important exception!"; }
}
class HoHumException extends Exception {
public String toString() {
return "A trivial exception";
}
}
public class LostMessage {
void f() throws VeryImportantException {
throw new VeryImportantException();
}
void dispose() throws HoHumException {
throw new HoHumException();
}
public static void main(String[] args) {
try {
LostMessage lm = new LostMessage();
try {
lm.f();
} finally {
lm.dispose();
}
} catch(Exception e) {
System.out.println(e);
}
}
} /* Output:
A trivial exception
*///:~从上面的四个代码片段,我们可以看出,finally子句 是在 try 或者 catch 中的 return 语句之前执行的。更加一般的说法是,finally子句 应该是在控制转移语句之前执行,控制转移语句除了 return 外,还有 break 和 continue。另外,throw 语句也属于控制转移语句。虽然 return、throw、break 和 continue 都是控制转移语句,但是它们之间是有区别的。其中 return 和 throw 把程序控制权转交给它们的调用者(invoker),而 break 和 continue 的控制权是在当前方法内转移。
下面,再看两个代码片段:
// 代码片段5public class Test {
public static void main(String[] args) {
System.out.println("return value of getValue(): " + getValue());
}
public static int getValue() {
try {
return 0;
} finally {
return 1;
}
}
}/* Output:
return value of getValue(): 1
*///:~// 代码片段6public class Test {
public static void main(String[] args) {
System.out.println("return value of getValue(): " + getValue());
}
public static int getValue() {
int i = 1;
try {
return i;
} finally {
i++;
}
}
}/* Output:
return value of getValue(): 1
*///:~ 利用我们上面分析得出的结论:finally子句 是在 try子句 或者 catch子句 中的 return 语句之前执行的。 由此,可以轻松的理解代码片段 5 的执行结果是 1。因为 finally 中的 return 1;语句要在 try 中的 return 0;语句之前执行,那么 finally 中的 return 1;语句执行后,把程序的控制权转交给了它的调用者 main()函数,并且返回值为 1。
那为什么代码片段 6 的返回值不是 2,而是 1 呢? 按照代码片段 5 的分析逻辑,finally 中的 i++;语句应该在 try 中的 return i;之前执行啊? i 的初始值为 1,那么执行 i++;之后为 2,再执行 return i;那不就应该是 2 吗?怎么变成 1 了呢?
关于 Java 虚拟机是如何编译 finally 子句的问题,有兴趣的读者可以参考《 The JavaTM Virtual Machine Specification, Second Edition 》中 7.13 节 Compiling finally。那里详细介绍了 Java 虚拟机是如何编译 finally 子句。实际上,Java 虚拟机会把 finally 子句作为 subroutine 直接插入到 try 子句或者 catch 子句的控制转移语句之前。但是,还有另外一个不可忽视的因素,那就是在执行 subroutine(也就是 finally 子句)之前,try 或者 catch 子句会保留其返回值到本地变量表(Local Variable Table)中。待 subroutine 执行完毕之后,再恢复保留的返回值到操作数栈中,然后通过 return 或者 throw 语句将其返回给该方法的调用者(invoker)。
请注意,前文中我们曾经提到过 return、throw 和 break、continue 的区别,对于这条规则(保留返回值),只适用于 return 和 throw 语句,不适用于 break 和 continue 语句,因为它们根本就没有返回值。
下面再看最后三个代码片段:
// 代码片段7public class Test {
public static void main(String[] args) {
System.out.println("return value of getValue(): " + getValue());
}
@SuppressWarnings("finally")
public static int getValue() {
int i = 1;
try {
i = 4;
} finally {
i++;
return i;
}
}
}/* Output:
return value of getValue(): 5
*///:~// 代码片段8public class Test {
public static void main(String[] args) {
System.out.println("return value of getValue(): " + getValue());
}
public static int getValue() {
int i = 1;
try {
i = 4;
} finally {
i++;
}
return i;
}
}/* Output:
return value of getValue(): 5
*///:~// 代码片段9public class Test {
public static void main(String[] args) {
System.out.println(test());
}
public static String test() {
try {
System.out.println("try block");
return test1();
} finally {
System.out.println("finally block");
}
}
public static String test1() {
System.out.println("return statement");
return "after return";
}
}/* Output:
try block
return statement
finally block
after return
*///:~请注意,最后个案例的唯一一个需要注意的地方就是,return test1(); 这条语句等同于 :
String tmp = test1(); return tmp;
因而会产生上述输出。
特别需要注意的是,在以下4种特殊情况下,finally子句不会被(完全)执行:
1)在 finally 语句块中发生了异常;
2)在前面的代码中用了 System.exit()【JVM虚拟机停止】退出程序;
3)程序所在的线程死亡;
4)关闭 CPU;
四. 异常的限制
当覆盖方法时,只能抛出在基类方法的异常说明里列出的那些异常。这意味着,当基类使用的代码应用到其派生类对象时,一样能够工作。
class BaseballException extends Exception {}
class Foul extends BaseballException {}
class Strike extends BaseballException {}
abstract class Inning {
public Inning() throws BaseballException {}
public void event() throws BaseballException {
// Doesn’t actually have to throw anything
}
public abstract void atBat() throws Strike, Foul;
public void walk() {} // Throws no checked exceptions }
class StormException extends Exception {}
class RainedOut extends StormException {}
class PopFoul extends Foul {}
interface Storm {
public void event() throws RainedOut;
public void rainHard() throws RainedOut;
}
public class StormyInning extends Inning implements Storm {
// OK to add new exceptions for constructors, but you must deal with the base constructor exceptions:
public StormyInning() throws RainedOut, BaseballException {}
public StormyInning(String s) throws Foul, BaseballException {}
// Regular methods must conform to base class:
void walk() throws PopFoul {} //Compile error
// Interface CANNOT add exceptions to existing methods from the base class:
public void event() throws RainedOut {}
// If the method doesn’t already exist in the base class, the exception is OK:
public void rainHard() throws RainedOut {}
// You can choose to not throw any exceptions, even if the base version does:
public void event() {}
// Overridden methods can throw inherited exceptions:
public void atBat() throws PopFoul {}
public static void main(String[] args) {
try {
StormyInning si = new StormyInning();
si.atBat();
} catch(PopFoul e) {
System.out.println("Pop foul");
} catch(RainedOut e) {
System.out.println("Rained out");
} catch(BaseballException e) {
System.out.println("Generic baseball exception");
}
// Strike not thrown in derived version.
try {
// What happens if you upcast? ----印证“编译器的类型检查是静态的,是针对引用的!!!”
Inning i = new StormyInning();
i.atBat();
// You must catch the exceptions from the base-class version of the method:
} catch(Strike e) {
System.out.println("Strike");
} catch(Foul e) {
System.out.println("Foul");
} catch(RainedOut e) {
System.out.println("Rained out");
} catch(BaseballException e) {
System.out.println("Generic baseball exception");
}
}
} ///:~异常限制对构造器不起作用
子类构造器不必理会基类构造器所抛出的异常。然而,因为基类构造器必须以这样或那样的方式被调用(这里默认构造器将自动被调用),派生类构造器的异常说明必须包含基类构造器的异常说明。
派生类构造器不能捕获基类构造器抛出的异常
因为 super() 必须位于子类构造器的第一行,而若要捕获父类构造器的异常的话,则第一行必须是 try 子句,这样会导致编译不会通过。
派生类所重写的方法抛出的异常列表不能大于父类该方法的异常列表,即前者必须是后者的子集
通过强制派生类遵守基类方法的异常说明,对象的可替换性得到了保证。需要指出的是,派生类方法可以不抛出任何异常,即使基类中对应方法具有异常说明。也就是说,一个出现在基类方法的异常说明中的异常,不一定会出现在派生类方法的异常说明里。
异常说明不是方法签名的一部分
尽管在继承过程中,编译器会对异常说明做强制要求,但异常说明本身并不属于方法类型的一部分,方法类型是由方法的名字及其参数列表组成。因此,不能基于异常说明来重载方法。
五. 自定义异常
使用Java内置的异常类可以描述在编程时出现的大部分异常情况。除此之外,用户还可以自定义异常。用户自定义异常类,只需继承Exception类即可。
在程序中使用自定义异常类,大体可分为以下几个步骤:
(1)创建自定义异常类;
(2)在方法中通过throw关键字抛出异常对象;
(3)如果在当前抛出异常的方法中处理异常,可以使用try-catch语句捕获并处理;否则在方法的声明处通过throws关键字指明要抛出给方法调用者的异常,继续进行下一步操作;
(4)在出现异常方法的调用者中捕获并处理异常。
六. 异常栈与异常链
1、栈轨迹
printStackTrace() 方法可以打印Throwable和Throwable的调用栈轨迹。调用栈显示了由异常抛出点向外扩散的所经过的所有方法,即方法调用序列(main方法 通常是方法调用序列中的最后一个)。
2、重新抛出异常
catch(Exception e) {
System.out.println("An exception was thrown");
throw e;
} 既然已经得到了对当前异常对象的引用,那么我们就可以像上面一样将其重新抛出。重新抛出的异常会把异常抛给上一级环境中的异常处理程序,同一个try子句的后续catch子句将被忽略。此外,如果只是把当前异常对象重新抛出,那么printStackTrace() 方法显示的仍是原来异常抛出点的调用栈信息,而并非重新抛出点的信息。要想更新这个信息,可以调用fillInStackTrace() 方法,这将返回一个Throwable对象,它是通过把当前调用栈信息填入原来那个异常对象而建立的。
看下面示例:
public class Rethrowing {
public static void f() throws Exception {
System.out.println("originating the exception in f()");
throw new Exception("thrown from f()");
}
public static void g() throws Exception {
try {
f();
} catch(Exception e) {
System.out.println("Inside g(),e.printStackTrace()");
e.printStackTrace(System.out);
throw e;
}
}
public static void h() throws Exception { try {
f();
} catch(Exception e) {
System.out.println("Inside h(),e.printStackTrace()");
e.printStackTrace(System.out);
throw (Exception)e.fillInStackTrace();
}
}
public static void main(String[] args) {
try {
g();
} catch(Exception e) {
System.out.println("main: printStackTrace()");
e.printStackTrace(System.out);
}
try {
h();
} catch(Exception e) {
System.out.println("main: printStackTrace()");
e.printStackTrace(System.out);
}
}
} /* Output:
originating the exception in f()
Inside g(),e.printStackTrace()
java.lang.Exception: thrown from f()
at Rethrowing.f(Rethrowing.java:7)
at Rethrowing.g(Rethrowing.java:11)
at Rethrowing.main(Rethrowing.java:29)
main: printStackTrace()
java.lang.Exception: thrown from f()
at Rethrowing.f(Rethrowing.java:7)
at Rethrowing.g(Rethrowing.java:11)
at Rethrowing.main(Rethrowing.java:29)
originating the exception in f()
Inside h(),e.printStackTrace()
java.lang.Exception: thrown from f()
at Rethrowing.f(Rethrowing.java:7)
at Rethrowing.h(Rethrowing.java:20)
at Rethrowing.main(Rethrowing.java:35)
main: printStackTrace()
java.lang.Exception: thrown from f()
at Rethrowing.h(Rethrowing.java:24)
at Rethrowing.main(Rethrowing.java:35)
*///:~3、异常链
异常链:在捕获一个异常后抛出另一个异常,并且希望把原始异常的信息保存下来。
这可以使用带有cause参数的构造器(在Throwable的子类中,只有Error,Exception和RuntimeException三个类提供了带有cause的构造器)或者使用initcause()方法把原始异常传递给新的异常,使得即使在当前位置创建并抛出了新的异常,也能通过这个异常链追踪到异常最初发生的位置,例如:
class DynamicFieldsException extends Exception {}
...
DynamicFieldsException dfe = new DynamicFieldsException();
dfe.initCause(new NullPointerException());
throw dfe;
...//捕获该异常并打印其调用站轨迹为:/**
DynamicFieldsException
at DynamicFields.setField(DynamicFields.java:64)
at DynamicFields.main(DynamicFields.java:94)
Caused by: java.lang.NullPointerException
at DynamicFields.setField(DynamicFields.java:66)
... 1 more
*/以 RuntimeException 及其子类NullPointerException为例,其源码分别为:
RuntimeException 源码包含四个构造器,有两个可接受cause:
public class RuntimeException extends Exception {
static final long serialVersionUID = -7034897190745766939L;
/** Constructs a new runtime exception with <code>null</code> as its
* detail message. The cause is not initialized, and may subsequently be
* initialized by a call to {@link #initCause}.
*/
public RuntimeException() { super();
} /** Constructs a new runtime exception with the specified detail message.
* The cause is not initialized, and may subsequently be initialized by a
* call to {@link #initCause}.
*
* @param message the detail message. The detail message is saved for
* later retrieval by the {@link #getMessage()} method.
*/
public RuntimeException(String message) { super(message);
} /**
* Constructs a new runtime exception with the specified detail message and
* cause. <p>Note that the detail message associated with
* <code>cause</code> is <i>not</i> automatically incorporated in
* this runtime exception's detail message.
*
* @param message the detail message (which is saved for later retrieval
* by the {@link #getMessage()} method).
* @param cause the cause (which is saved for later retrieval by the
* {@link #getCause()} method). (A <tt>null</tt> value is
* permitted, and indicates that the cause is nonexistent or
* unknown.)
* @since 1.4
*/
public RuntimeException(String message, Throwable cause) { super(message, cause);
} /** Constructs a new runtime exception with the specified cause and a
* detail message of <tt>(cause==null ? null : cause.toString())</tt>
* (which typically contains the class and detail message of
* <tt>cause</tt>). This constructor is useful for runtime exceptions
* that are little more than wrappers for other throwables.
*
* @param cause the cause (which is saved for later retrieval by the
* {@link #getCause()} method). (A <tt>null</tt> value is
* permitted, and indicates that the cause is nonexistent or
* unknown.)
* @since 1.4
*/
public RuntimeException(Throwable cause) { super(cause);
}
}NullPointerException 源码仅包含两个构造器,均不可接受cause:
public class NullPointerException extends RuntimeException {
/**
* Constructs a <code>NullPointerException</code> with no detail message.
*/
public NullPointerException() { super();
} /**
* Constructs a <code>NullPointerException</code> with the specified
* detail message.
*
* @param s the detail message.
*/
public NullPointerException(String s) { super(s);
}
}注意:
所有的标准异常类都有两个构造器:一个是默认构造器;另一个是接受字符串作为异常说明信息的构造器。
以上是Java異常模型的詳細介紹與分析(圖)的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題








 突破或從Java 8流返回?
Feb 07, 2025 pm 12:09 PM
突破或從Java 8流返回?
Feb 07, 2025 pm 12:09 PM
Java 8引入了Stream API,提供了一種強大且表達力豐富的處理數據集合的方式。然而,使用Stream時,一個常見問題是:如何從forEach操作中中斷或返回? 傳統循環允許提前中斷或返回,但Stream的forEach方法並不直接支持這種方式。本文將解釋原因,並探討在Stream處理系統中實現提前終止的替代方法。 延伸閱讀: Java Stream API改進 理解Stream forEach forEach方法是一個終端操作,它對Stream中的每個元素執行一個操作。它的設計意圖是處

 Java程序查找膠囊的體積
Feb 07, 2025 am 11:37 AM
Java程序查找膠囊的體積
Feb 07, 2025 am 11:37 AM
膠囊是一種三維幾何圖形,由一個圓柱體和兩端各一個半球體組成。膠囊的體積可以通過將圓柱體的體積和兩端半球體的體積相加來計算。本教程將討論如何使用不同的方法在Java中計算給定膠囊的體積。 膠囊體積公式 膠囊體積的公式如下: 膠囊體積 = 圓柱體體積 兩個半球體體積 其中, r: 半球體的半徑。 h: 圓柱體的高度(不包括半球體)。 例子 1 輸入 半徑 = 5 單位 高度 = 10 單位 輸出 體積 = 1570.8 立方單位 解釋 使用公式計算體積: 體積 = π × r2 × h (4
