

具體介紹歷數Firefox2.0對XML處理的改進的程式碼實例(圖)

Firefox 2.0 在對 XML 的支援方面有幾個重要的改進。目前它的用戶部署如日中天。了解 Firefox 2.0 XML 特性的改進,包括在 RSS Web 提要處理方面有爭議的變化。
被賦予新應用程式平台的角色後,現在 Web 瀏覽器可能是最熱門的軟體。對於軟體開發人員來說這是令人興奮的時
Firefox 2.0 在對 XML 的支援方面有幾個重要的改進。目前它的用戶部署如日中天。了解 Firefox 2.0 XML 特性的改進,包括在 RSS Web 提要處理方面有爭議的變化。
被賦予新應用程式平台的角色後,現在 Web 瀏覽器可能是最熱門的軟體。對於軟體開發人員來說這是令人興奮的時刻,動態HTML 技術以Asynchronous JavaScript XML (Ajax) 獲得重生,Microsoft® Internet Explorer® 的開發得以恢復等等。在過去兩年中,關於 XML 和 Firefox 的 developerWorks 系列文章(請參閱 參考資料)介紹了以 1.8 版本的核心 Mozilla 瀏覽器引擎為基礎的 Firefox 1.5 版。此後,Mozilla 專案永不停歇的開發步伐又催生了 Firefox 2.0,它以 Gecko 1.8.1 Web 呈現引擎為基礎。 Firefox 2.0 的一些改進涉及 XML 處理。本文介紹了最新的 Firefox XML 處理功能,包括開發人員應該記住的可能遇到的主要障礙。
減少了對 Web 提要的控制
Firefox 2.0 一個變更引起了使用者社群的極大驚慌。如果提供 RSS 或 Atom 這類 Web 提要,可能需要包含 XSLT 樣式表為使用者轉換成其他表示形式。清單 1 中的 Atom 提要引用了這樣的轉換。
清單1. 包含樣式表引用的Atom 提要
<?xml version="1.0" encoding="utf-8"?> <?xml-stylesheet type="text/xml" href="atom2html.xslt"?> <feed xmlns="http://www.w3.org/2005/Atom" xml:lang="en" xml:base="http://www.example.org"> <id>http://www.php.cn/;/id> <title>My Simple Feed</title> <updated>2005-07-15T12:00:00Z</updated> <link href="/blog" /> <link rel="self" href="/myfeed" /> <author><name>Uche Ogbuji</name></author> <entry> <id>http://www.php.cn/;/id> <title>A simple blog entry</title> <link href="/blog/2005/07/1" /> <updated>2005-07-14T12:00:00Z</updated> <summary>This is a simple blog entry</summary> </entry> <entry> <id>http://www.php.cn/;/id> <title /> <link href="/blog/2005/07/2" /> <updated>2005-07-15T12:00:00Z</updated> <summary>This is simple blog entry without a title</summary> </entry> </feed>
關鍵是第二行中的樣式表處理指令(PI)。如果用 Firefox 1.5 打開,瀏覽器就會盡責地載入 atom2html.xslt 並顯示結果。本系列文章第 2 部分(請參閱 參考資料)已經提到,查看實際的 XML 必須通過 “查看原始程式碼”。在 Firefox 2.0 中,瀏覽器忽略該樣式表 PI 並使用定制的 Firefox 視圖查看,如圖 1 所示(Firefox 2.0.0.6、Mac OS X 平台上的螢幕截圖)。 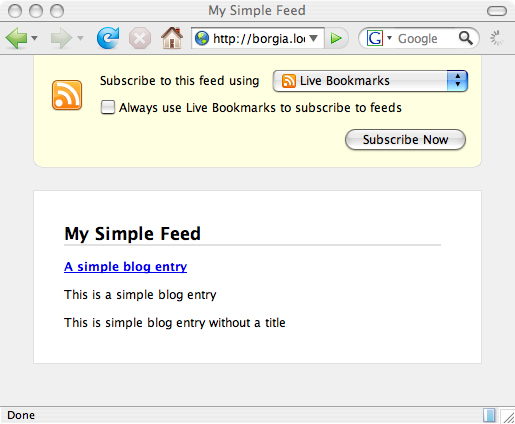
圖1. Firefox 2.0 內建的Web 提要視圖
避免這種情況並強制使用所選樣式表,惟一的辦法就是愚弄頭腦簡單的Firefox,它透過在文件前512在位元組中尋找「rss」 或「feed」 來判定是否為Web 提要。清單 2 採用了一種廣為人知的辦法,專門插入一段註解來填滿這 512 個位元組。
清單 2. 繞過 Firefox 2.0 和 Internet Explorer 7 預設樣式表處理方式的 Atom 提要
<?xml version="1.0" encoding="utf-8"?> <!-- Firefox 2.0 and Internet Explorer 7 use simplistic feed sniffing to override desired presentation behavior for this feed, and thus we are obliged to insert this comment, a bit of a waste of bandwidth, unfortunately. This should ensure that the following stylesheet processing instruction is honored by these new browser versions. For some more background you might want to visit the following bug report: http://www.php.cn/ --> <?xml-stylesheet type="text/xml" href="atom2html.xslt"?> <feed xmlns="http://www.w3.org/2005/Atom" xml:lang="en" xml:base="http://www.example.org"> <!-- content of the feed identical to listing 1, so trimmed --> </feed>
考虑了用户社区的反对意见之后,Firefox 开发人员决定坚持自身的立场,因而这种行为方式将保留到未来的 Firefox 版本之中。我个人不喜欢这种方式,您可以阅读有关的争论再决定喜欢与否。值得一提的是,这种做法与 Internet Explorer 和 Apple Safari 有相似之处。
#p#
微摘要
微摘要(microsummarie),也称为活动标题(Live Title)是 Firefox 2.0 一种简洁的新特性,可以让浏览器用网站中一些有意义的内容来替换标题,特别是在书签中。比如,IBM developerWorks 的微摘要可以用站点上的最新文章标题代替静态文字 “developerWorks : IBM's resource for developers”。网站可以提供一个微摘要,用户也可自行创建。后一种情况称为 “微摘要生成器”,也是本文更关注的一点,因为它要求用户端处理 XML 和 XSLT(不熟悉 XML 的人可以重复使用其他人提供的生成器)。清单 3 中的微摘要生成器提取 developerWorks 主打文章的标题。
清单 3. 使用 IBM developerWorks 主打文章标题的微摘要生成器
<?xml version="1.0" encoding="UTF-8"?> <generator xmlns="http://www.mozilla.org/microsummaries/0.1" name="IBM developerWorks featured article"> <template> <xsl:transform xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0" xmlns:html="http://www.w3.org/1999/xhtml"> <xsl:output method="text"/> <xsl:template match="/"> <xsl:text>Featured article:</xsl:text> <!-- On sites that make wider use of element IDs you can use more direct and efficient XPaths --> <xsl:value-of select="//html:a[@class='feature'][1]"/> </xsl:template> </xsl:transform> </template> <pages> <include>http://www.php.cn/[a-zA-Z0-9]*/?</include> </pages> </generator>
生成器包括两部分:模板和页面信息。模板包括应用于网页的提取微摘要文本的 XSLT 代码。后者指定浏览器把微摘要应用于哪个页面。微摘要是简单的文本,输出指令与此相适应。微摘要的关键在于 XPath //html:a[@class='feature'][1],查找包含主打文章标题的元素。pages 部分的正则表达式保证微摘要可用于网站首页和每个 developerWorks 专区的首页。
参考资料 提供的一篇教程说明了如何安装 清单 3 这样的微摘要生成器。到目前为止,微摘要还是 Mozilla 特有的特性。
SAX 及其他
对于那些开发 Mozilla 扩展的人来说,最有意义的是 Mozilla XPCOM 组件系统现在提供了一个 SAX 解析器框架。如果没有合适的高层处理技术,可以自行开发高效处理 XML 的扩展。XPCOM 集成意味着可以用 C 、JavaScript 或具有 XPCOM 绑定支持的其他任何语言来处理 SAX 事件。
OpenSearch
OpenSearch 是 Amazon A9 孵化器开发的一个 XML 标准。它提供了几种 XML 格式和其他约定来描述和使用搜索引擎。Firefox 一直强力支持可扩展的搜索引擎插件,2.0 引入了 OpenSearch 支持,因而可以通过与 Iternet Explorer 及其他浏览器兼容的机制扩展搜索功能。
Firefox 支持的 OpenSearch 1.1 目前是 beta 版,为保持与 Firefox 和 OpenSearch 的兼容性,可能需要更新。清单 4 提供了对于 IBM developerWorks 的 OpenSearch 描述文档。
清单 4. IBM developerWorks 的 OpenSearch 描述文档
<?xml version="1.0" encoding="UTF-8"?>
<OpenSearchDescription xmlns="http://a9.com/-/spec/opensearch/1.1/">
<ShortName>IBM developerWorks search</ShortName>
<Description>Search IBM developerWorks zones</Description>
<Tags>xml java architecture</Tags>
<InputEncoding>utf-8</InputEncoding>
<Contact>http://www.php.cn/
</Contact>
<!-- The template attribute is split at the "?" for formatting purposes -->
<Url type="text/html"
template="http://www.ibm.com/developerworks/views/xml/
libraryview.jsp?
search_by={searchTerms}"/>
<Attribution>All content Copyright 2007, IBM developerWorks</Attribution>
</OpenSearchDescription>
该文档仅仅说明 IBM developerWorks 提供了一个搜索 URL:
http://www.ibm.com/developerworks/views/xml/libraryview.jsp?search_by={searchTerms}其中的 {searchTerms} 是一个模板参数,搜索工具将使用搜索项目来代替它。如果搜索 “Firefox XML”,URL 将变成:
http://www.ibm.com/developerworks/views/xml/libraryview.jsp?search_by=Firefox XML
OpenSearch 规范了定义了这种 URL 模板系统。OpenSearch 还定义了把结果返回为 RSS 2.0 或 Atom 1.0 提要的约定和几种专用的扩展。Firefox 还不支持这种 Web 提要搜索结果,如果描述不含 Url 元素和 type="text/html"(表示从 URL 返回的内容类型)则返回错误。这种限制很不合理,但也可能是基于多数人仍然通过传统 HTML 表单和结果页面而不是 Web 2.0 机制搜索的现实考量。
在 Firefox 2.0 中,清单 4 这样的 OpenSearch 描述就像是完整的搜索引擎插件。网站可以使用页面头部的链接指定这样的描述,比如:
<link rel="search" type="application/opensearchdescription xml" title="IBM developerWorks" href="/path/to/opensearch/description/document.xml"/>
注意:前面的三行代码通常显示为一行。为了便于显示和打印而分解成多行。
结束语
仍在 alpha 测试阶段的 Firefox 3.0 将带来更重要的 XML 特性。预计将在 2008 年上半年发布完整的版本。包括关于 XML 处理的重要 bug 修正和新的特性,当它成为主流 Firefox 版本的时候我将继续讨论。Mozilla 核心 XML 工具箱仍然在不断改进,对于涉及 XML 技术的开发人员和用户来说是一大福音。对于多数用户和开发人员来说,Web 浏览器是 XML 处理的脸面,本系列文章讲继续追踪和讨论最新 Firefox 版本的相关特性。
以上是具體介紹歷數Firefox2.0對XML處理的改進的程式碼實例(圖)的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 能否用PowerPoint開啟XML文件
Feb 19, 2024 pm 09:06 PM
能否用PowerPoint開啟XML文件
Feb 19, 2024 pm 09:06 PM
XML檔可以用PPT開啟嗎? XML,即可擴展標記語言(ExtensibleMarkupLanguage),是一種廣泛應用於資料交換和資料儲存的通用標記語言。與HTML相比,XML更加靈活,能夠定義自己的標籤和資料結構,使得資料的儲存和交換更加方便和統一。而PPT,即PowerPoint,是微軟公司開發的一種用於創建簡報的軟體。它提供了圖文並茂的方
 使用Python實現XML資料的合併與去重
Aug 07, 2023 am 11:33 AM
使用Python實現XML資料的合併與去重
Aug 07, 2023 am 11:33 AM
使用Python實現XML資料的合併和去重XML(eXtensibleMarkupLanguage)是一種用於儲存和傳輸資料的標記語言。在處理XML資料時,有時候我們需要將多個XML檔案合併成一個,或移除重複的資料。本文將介紹如何使用Python實現XML資料的合併和去重的方法,並給出對應的程式碼範例。一、XML資料合併當我們有多個XML文件,需要將其合
 Python中的XML資料轉換為CSV格式
Aug 11, 2023 pm 07:41 PM
Python中的XML資料轉換為CSV格式
Aug 11, 2023 pm 07:41 PM
Python中的XML資料轉換為CSV格式XML(ExtensibleMarkupLanguage)是一種可擴充標記語言,常用於資料的儲存與傳輸。而CSV(CommaSeparatedValues)則是一種以逗號分隔的文字檔案格式,常用於資料的匯入和匯出。在處理資料時,有時需要將XML資料轉換為CSV格式以便於分析和處理。 Python作為一種功能強大
 使用Python實現XML資料的篩選和排序
Aug 07, 2023 pm 04:17 PM
使用Python實現XML資料的篩選和排序
Aug 07, 2023 pm 04:17 PM
使用Python實現XML資料的篩選和排序引言:XML是一種常用的資料交換格式,它以標籤和屬性的形式儲存資料。在處理XML資料時,我們經常需要對資料進行篩選和排序。 Python提供了許多有用的工具和函式庫來處理XML數據,本文將介紹如何使用Python實現XML資料的篩選和排序。讀取XML檔案在開始之前,我們需要先讀取XML檔案。 Python有許多XML處理函式庫,
 使用PHP將XML資料匯入資料庫
Aug 07, 2023 am 09:58 AM
使用PHP將XML資料匯入資料庫
Aug 07, 2023 am 09:58 AM
使用PHP將XML資料匯入資料庫引言:在開發中,我們經常需要將外部資料匯入到資料庫中進行進一步的處理和分析。而XML作為一種常用的資料交換格式,也常被用來儲存和傳輸結構化資料。本文將介紹如何使用PHP將XML資料匯入資料庫。步驟一:解析XML文件首先,我們需要解析XML文件,擷取所需的資料。 PHP提供了幾種解析XML的方式,其中最常用的是使用Simple
 Python實作XML與JSON之間的轉換
Aug 07, 2023 pm 07:10 PM
Python實作XML與JSON之間的轉換
Aug 07, 2023 pm 07:10 PM
Python實作XML與JSON之間的轉換導語:在日常的開發過程中,我們常常需要將資料在不同的格式之間轉換。 XML和JSON是常見的資料交換格式,在Python中,我們可以使用各種函式庫來實作XML和JSON之間的相互轉換。本文將介紹幾種常用的方法,並附帶程式碼範例。一、XML轉JSON在Python中,我們可以使用xml.etree.ElementTree模
 使用Python處理XML中的錯誤和異常
Aug 08, 2023 pm 12:25 PM
使用Python處理XML中的錯誤和異常
Aug 08, 2023 pm 12:25 PM
使用Python處理XML中的錯誤和異常XML是一種常用的資料格式,用於儲存和表示結構化的資料。當我們使用Python處理XML時,有時可能會遇到一些錯誤和異常。在本篇文章中,我將介紹如何使用Python來處理XML中的錯誤和異常,並提供一些範例程式碼供參考。使用try-except語句捕捉XML解析錯誤當我們使用Python解析XML時,有時候可能會遇到一些
 Python解析XML中的特殊字元和轉義序列
Aug 08, 2023 pm 12:46 PM
Python解析XML中的特殊字元和轉義序列
Aug 08, 2023 pm 12:46 PM
Python解析XML中的特殊字元和轉義序列XML(eXtensibleMarkupLanguage)是一種常用的資料交換格式,用於在不同系統之間傳輸和儲存資料。在處理XML檔案時,經常會遇到包含特殊字元和轉義序列的情況,這可能會導致解析錯誤或誤解資料。因此,在使用Python解析XML檔案時,我們需要了解如何處理這些特殊字元和轉義序列。一、特殊字元和
