

1 小時學會 MySQL 資料庫

隨著行動互聯網的結束與人工智慧的到來大數據變成越來越重要,下一個成功者應該是擁有大量數據的,數據與資料庫你應該知道。
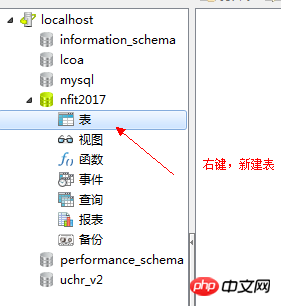
一、資料庫概要
資料庫(Database)是儲存與管理資料的軟體系統,就像一個存入資料的物流倉庫。
在商業領域,資訊意味著商機,取得資訊的一個非常重要的途徑就是對資料進行分析處理,這就催生了各種專業的資料管理軟體,資料庫就是其中的一種。當然,資料庫管理系統也不是一下子就建立起來,它也是經過了不斷的豐富與發展,才有了今天的模樣。

# 1.1、發展歷史
1.1.1、手動處理階段
# 在1950年代中期以前的電腦誕生初期,其處理能力很有限,只能夠完成一些簡單的運算,數據處理能力也很有限,這使得當時的計算機只能夠用於科學和工程計算。電腦上沒有專用的管理資料的軟體,資料由電腦或處理它的程式自行攜帶。當資料的儲存格式、讀寫路徑或方法改變的時候,其處理程序也必須做出相應的改變以保持程式的正確性。
1.1.2、檔案系統
# 從1950年代後期到1960年代中期,隨著硬體和軟體技術的發展,電腦不僅用於科學計算,還大量用於商業管理。在這段時期,資料和程式在儲存位置上已經完全分開,資料被單獨組織成檔案保存到外部儲存裝置上,這樣資料檔案就可以為多個不同的程式在不同的時間所使用。
雖然程式和資料在儲存位置上分開了,而且作業系統也可以幫助我們對完成了資料的儲存位置和存取路徑的管理,但是程式設計仍然受到資料儲存格式和方法的影響,不能夠完全獨立於數據,而且數據的冗餘較大。
1.1.3、資料庫管理系統
# 自1970年代以來,電腦軟硬體技術取得了飛躍式的發展,這段時期最主要的發展就是產生了真正意義上的資料庫管理系統,它使得應用程式和資料之間真正的實現的介面統一、資料共享等,這樣應用程式都可以按照統一的方式直接操作數據,也就是應用程式和數據都具有了高度的獨立性。

圖1:追溯資料庫的發展歷程
# 1.2、常見資料庫技術品牌、服務與架構
發展了這麼多年市場上出現了許多的資料庫系統,最強的個人認為是Oracle,當然還有許多如:DB2、Microsoft SQL Server、MySQL、SyBase等,下圖列出常見資料庫技術品牌、服務與架構。

圖2:常見資料庫技術品牌、服務與架構
# 1.3、資料庫分類
資料庫通常分為層次式資料庫、網路式資料庫和關係式資料庫三種。
而不同的資料庫是依照不同的資料結構來聯繫和組織的。
而在現今的網際網路中,最常見的資料庫模型主要是兩種,即關聯式資料庫和非關係型資料庫。
1.3.1、關係型資料庫
# 目前在成熟應用且服務與各種系統的主力資料庫還是關係型資料庫。
# 代表:Oracle、SQL Server、MySQL
1.3.2、非關係型資料庫
# 隨著時代的進步與發展的需要,非關係型資料庫應運而生。
代表:Redis、Mongodb
# NoSQL資料庫在儲存速度與彈性方面有優勢,也常用於快取。
1.4、資料庫規範化
經過一系列的步驟,我們現在終於將客戶的需求轉換為資料表並確立這些表之間的關係,那麼是否我們現在就可以在開發中使用呢?答案否定的,為什麼呢!同一個項目,很多人參與了需求的分析,資料庫的設計,不同的人有不同的想法,不同的部門有不同的業務需求,我們以此設計的資料庫將不可避免的包含大量相同的數據,在結構上也有可能產生衝突,在開發上造成不便。
1.4.1. 什麼是範式
要設計規範化的資料庫,就要求我們根據資料庫設計範式――也就是資料庫設計的規範原則來做。範式可以引導我們更好地設計資料庫的表結構,減少冗餘的數據,藉此可以提高資料庫的儲存效率,資料完整性和可擴展性。
設計關聯式資料庫時,遵從不同的規範要求,設計出合理的關係型資料庫,這些不同的規範要求稱為不同的範式,各種範式呈現次規範,越高的範式資料庫冗餘越小。目前關聯式資料庫有六種範式:第一範式(1NF)、第二範式(2NF)、第三範式(3NF)、巴德斯科範式(BCNF)、第四範式(4NF)和第五範式(5NF ,又稱完美範式)。滿足最低要求的範式是第一個範式(1NF)。在第一範式的基礎上進一步滿足更多規範要求的稱為第二範式(2NF),其餘範式以次類推。一般說來,資料庫只要滿足第三範式(3NF)就行了。
1.4.2. 三大範式
第一範式(1NF)
所謂第一範式(1NF)是指在關係模型中,對列所新增的一個規範要求,所有的列都應該是原子性的,即資料庫表的每一列都是不可分割的原子資料項,而不能是集合,數組,記錄等非原子資料項。即實體中的某個屬性有多個值時,必須拆分為不同的屬性。在符合第一範式(1NF)表中的每個域值只能是實體的一個屬性或一個屬性的一部分。簡而言之,第一個範式就是無重複的域。
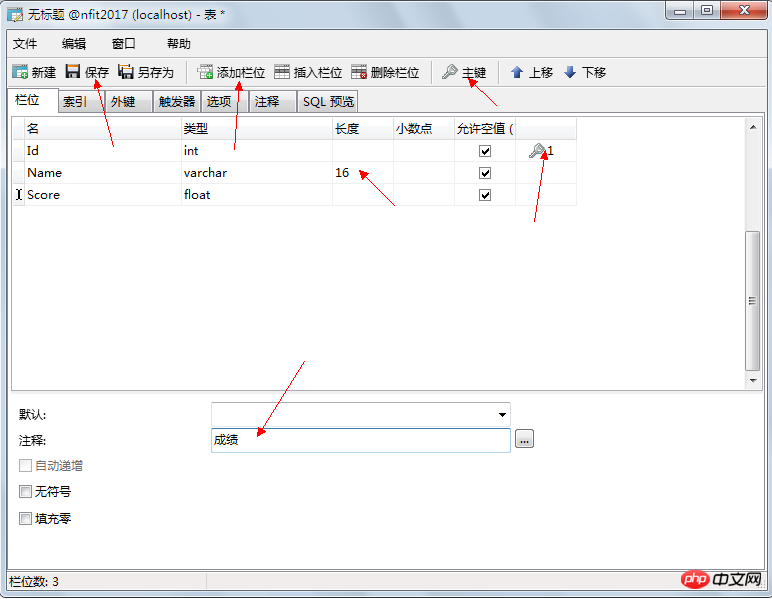
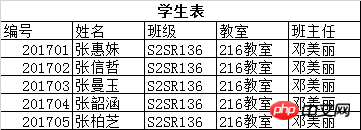
例如:表1-1中,其中”工程地址”欄位還可以細分為省份,城市等。在國外,更多的程序把」姓名」欄位也分成2列,即」姓」和「名」。
雖然第一範式要求各列要保存原子性,不能再分,但是這種要求和我們的需求是相關聯的,如上表中我們對”工程地址”沒有省份,城市這樣方面的查詢和應用需求,則不需拆分,」姓名」欄位也是如此。
表1-1 原始表
#工程編號 |
工程名稱 |
工程地址 |
#員工編號 |
員工名稱 |
薪資待遇 |
職務 |
P001 |
# 港珠澳大橋 |
廣東珠海 |
E0001 |
# Jack |
6000/月 |
工人 |
P001 |
# 港珠澳大橋 |
廣東珠海 |
E0002 |
# Join |
7800/月 |
工人 |
P001 |
# 港珠澳大橋 |
廣東珠海 |
E0003 |
# Apple |
8000/月 |
高階技工 |
P002 |
# 南海航太 |
# 海南三亞 |
# E0001 |
# Jack |
5000/月 |
工人 |
第二範式(2NF)
在1NF的基礎上,非Key屬性必須完全依賴主鍵。第二範式(2NF)是在第一範式(1NF)的基礎上建立起來的,即滿足第二範式(2NF)必須先滿足第一範式(1NF)。第二範式(2NF)要求資料庫表中的每個實例或記錄必須可以被唯一地區分。選取一個能區分每個實體的屬性或屬性群組,作為實體的唯一識別。
第二範式(2NF)要求實體的屬性完全依賴主關鍵字。所謂完全依賴是指不能存在只依賴主關鍵字一部分的屬性,如果存在,那麼這個屬性和主關鍵字的這一部分應該分離出來形成一個新的實體,新實體與原實體之間是一對多的關係。為實現區分通常需要為表格加上一個列,以儲存各個實例的唯一識別。簡言之,第二範式就是在第一範式的基礎上屬性完全依賴主鍵。
例如:表1-1中,一個表描述了工程信息,員工資訊等。這樣就造成了大量數據的重複。依照第二範式,我們可以將表1-1拆分成表1-2和表1-3:
l 工程資訊表:(工程編號,工程名稱,工程地址):
# 表1-2 工程資訊表
#工程編號 |
工程名稱 |
工程位址 |
| ## P001 | 港珠澳大橋||
| 廣東珠海 | P002 | 南海航太
# 海南三亞
表1-3 員工資訊表 |
#員工編號 |
員工姓名 |
職務 |
| #薪資水平 | ## E0001 | ||
# Jack |
工人 |
3000/月 |
# E0002 |
# Join |
工人 |
3000/月 |
# E0003 |
這樣,表1-1就變成了兩張表,每個表只描述一件事,清晰明了。
第三範式(3NF)
# 第三範式是在第二範式上,更進一層,第三範式的目標是確保表中各列與主鍵列直接相關,而非間接相關。即各列與主鍵列都是一種直接依賴關係,則滿足第三範式。
第三範式要求各列與主鍵列直接相關,我們可以這樣理解,假設張三是李四的兵,王五則是張三的兵,這時王五是不是李四的兵呢?從這個關係中我們可以看出,王五也是李四的兵,因為王五依賴張三,而張三是李四的兵,所以王五也是。這中間就存在著一種間接依賴的關係而非我們第三範式中所強調的直接依賴。
現在我們來看看在第二範式的講解中,我們將表1-1拆分成了兩張表。這兩個表是否符合第三範式呢。在員工資訊表中包含:“員工編號”、“員工名稱”、”職務”、“薪資水平”,而我們知道,薪資水平是有職務決定,這裡”薪資水平”通過”職務”與員工相關,則不符合第三範式。我們需要將員工資訊表進一步拆分,如下:
# 員工資訊表:員工編號,員工名稱,職務
# 職務表:職務編號,職務名稱,薪資等級
現在我們已經了解了資料庫規範化設計的三大範式,以下我們再來看看對錶1-1優化後的資料表:
員工資訊表(Employee)
#員工編號 |
員工姓名 |
職務編號 |
# E0001 |
# Jack |
1 |
E0002 |
# Join |
1 |
E0003 |
# Apple |
2 |
工程資訊表(ProjectInfo)
工程編號 |
工程名稱 |
工程位址 |
# P001 |
# 港珠澳大橋 |
廣東珠海 |
# P002 |
# 南海航太 |
# 海南三亞 |
職務表(Duty)
職務編號 |
職稱 |
薪資待遇 |
# 1 |
工人 |
3000/月 |
# 2 |
高階技工 |
# 6000/月 |
工程參與人員記錄表(Project_ Employee_info)
編號 |
##。編號 |
人員編號 |
|
| 1 | P001 | # E0001 | |
| # 2 | P001 | # E0002 | |
| # 3 | P002 | # E0003 |



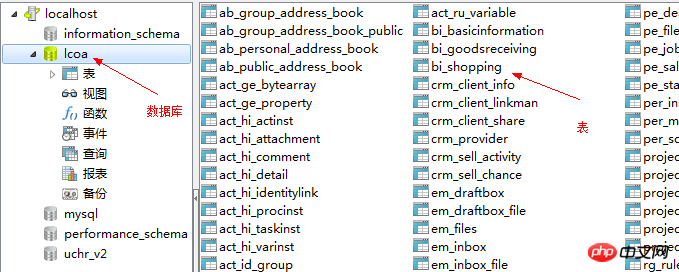
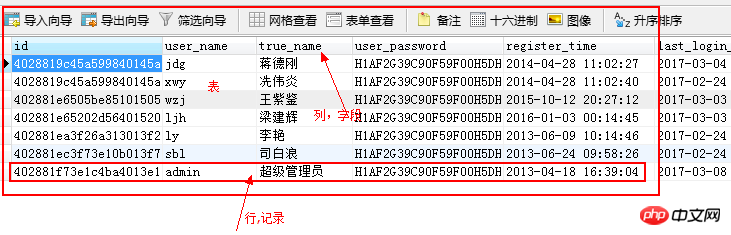


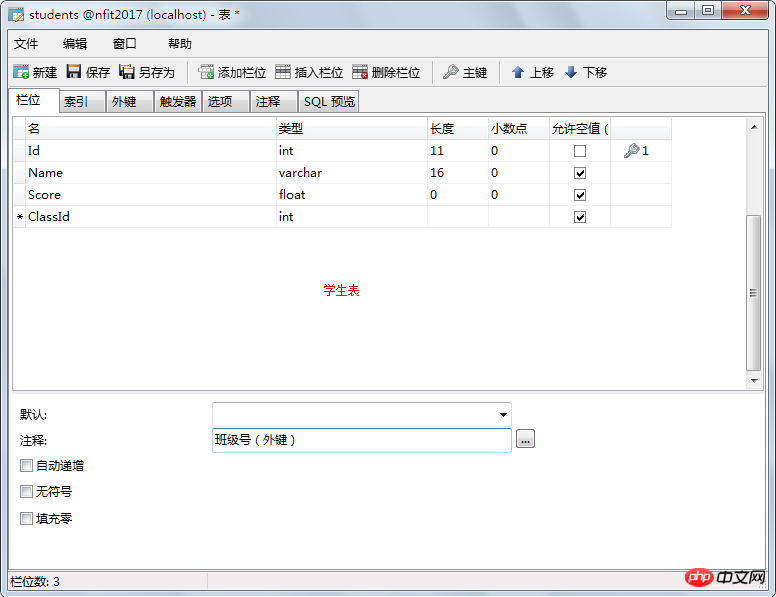
№ | 類型 | #描述 | |
1 | EMPNO | # int | 僱員的編號,主鍵,自動增長 |
2 | # ENAME | # VARCHAR(10) | 僱員的姓名,由10位元字元組成,不為空,唯一鍵 |
3 | JOB | VARCHAR(9) | 僱員的職位 |
4 | MGR | int | 僱員對應的領導編號,領導也是僱員,可空(可刪除這一列) |
# 5 | HIREDATE | # TimeStamp | # 僱員的僱用日期,預設為目前日期 |
# 6 | SAL | NUMBER(7,2) | 基本工資,其中有兩位小數,五位整數,一共是七位 |
# 7 | COMM | NUMBER(7,2) | 獎金,佣金 |
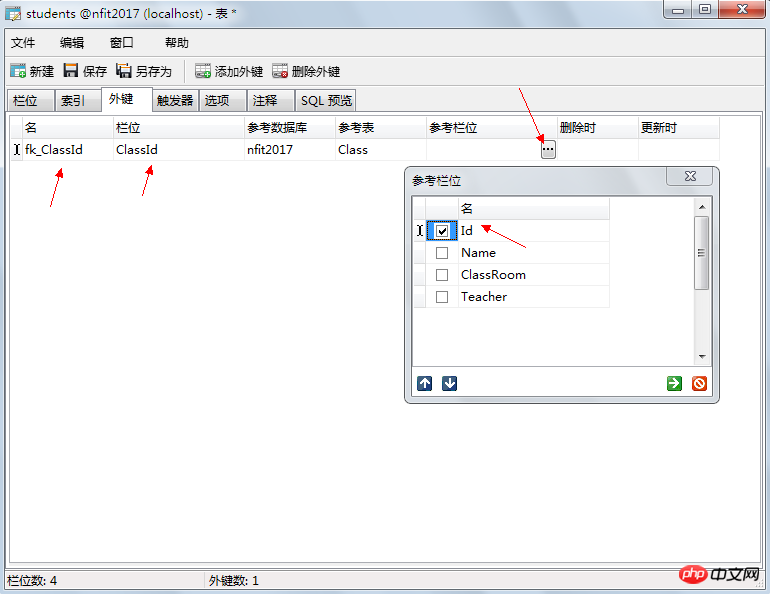
# 8 | DEPTNO | # int | 僱員所在的部門編號,可空,外鍵fk_deptno |
# 9 | DETAIL | # Text | 備註,可空 |
# Dept,部門表
№ | 類型 | #描述 | |
| 1 | DeptNO | # int | |
| 2 | DNAME | VARCHAR(10) | |
| 3 | DTel | VARCHAR(10) |
2、根據上面的表結構完成表格的創建,表名為emp
3.在表中加入5條以上的資料
4、完成下列查詢要求
4.1查詢所有員工資訊
4.2查詢所有薪資介於2000-5000間的員工姓名、職位與薪資
# 4.3查詢所有姓「張」的員工
4.4 依薪資降序查詢出2014年到2015年間入職的員工
# 4.5、將薪資普遍調高20%
4.6、將薪資低於3000元的員工獎金修改為薪資的2.8倍
# 4.7、刪除編號為5或姓「王」的員工
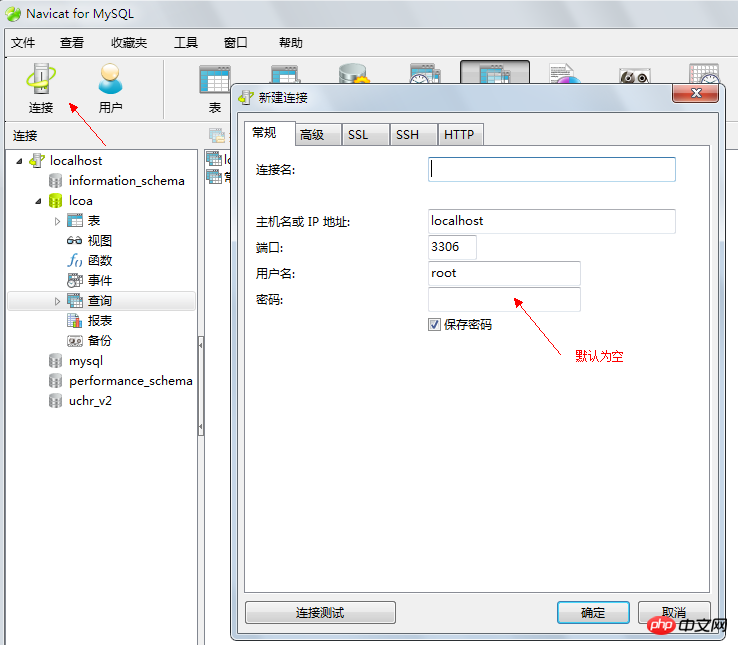
五、使用SQL存取MySQL資料庫
# 5.1、增加數據
insert 語句可以用來將一行或多行資料插到資料庫表中, 使用的一般形式如下:
# Insert into 表名(欄位清單) values (值列表);
# insert [into] 表名 [(列名1, 列名2, 列名3, ...)] values (值1, 值2, 值3, ...);
insert into students values(NULL, "張三", "男", 20, "18889009876");
有時我們只需要插入部分資料, 或不按照列的順序進行插入, 可以使用這樣的形式進行插入:
# insert into students (name, sex, age) values(“李四”, “女”, 21);
5.2、查詢資料
select 語句常用來根據一定的查詢規則到資料庫中取得資料, 其基本的用法為:
# select 欄位名稱 from 表名稱 [查詢條件];
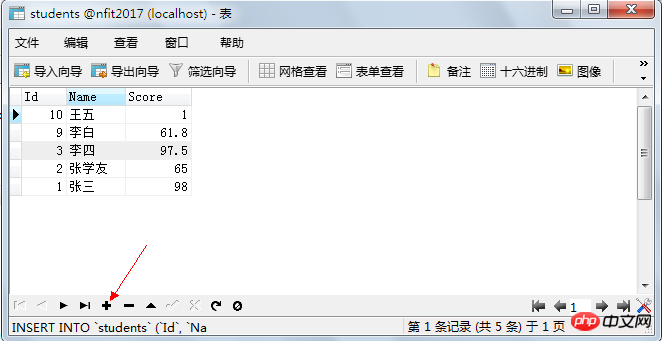
查詢學生表中的所有資訊:select * from students;
# 查詢學生表中所有的name與age資訊:select name, age from students;
# 也可以使用通配符 * 查詢表中所有的內容, 語句: select * from students;
5.2.1、表達式與條件查詢

圖5:資料庫運算子
# where 關鍵字用於指定查詢條件, 用法形式為: select 列名稱 from 表名稱 where 條件;
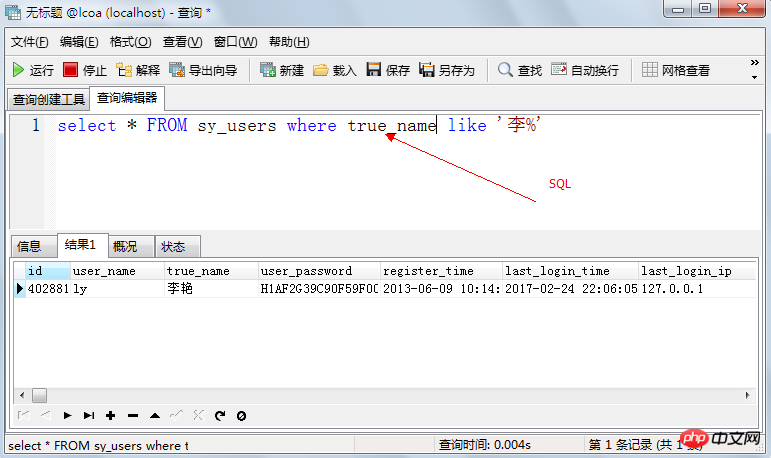
以查詢所有性別為女的資訊為例, 輸入查詢語句: select * from students where sex=”女”;
# where 子句不只支援「where 列名= 值」 這種名等於值的查詢形式, 對一般的比較運算的運算子都是支援的, 例如=、>、<、>=、< 、!= 以及一些擴充運算子is [not] null、in、like 等等。 還可以對查詢條件使用 or 和 and 進行組合查詢, 以後還會學到更加高級的條件查詢方式, 這裡不再多做介紹。
範例:
查詢年齡在21歲以上的所有人資訊: select * from students where age > 21;
查詢名字中帶有 “王” 字的所有人資訊: select * from students where name like “%王%”;
# 查詢id小於5且年齡大於20的所有人資訊: select * from students where id<5 and age>20;
5.2.2、聚合函數

#圖6:常見Group函數
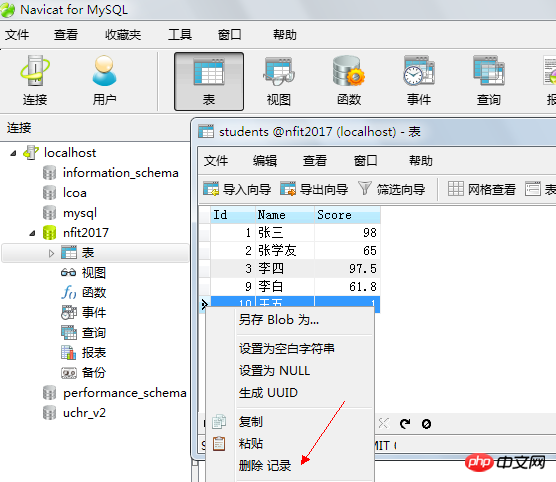
5.3、刪除資料
delete from 表名 [刪除條件];
# 刪除表中所有資料:delete from students;
刪除id為10的行: delete from students where id=10;
# 刪除所有年齡小於88歲的資料: delete from students where age<88;
5.4、更新資料
update 語句可用來修改表中的資料, 基本的使用形式為:
update 表格名稱 set 列名稱=新值 where 更新條件;
# Update 表名 set 欄位=值 清單 更新條件
使用範例:
# 將id為5的手機號碼改為預設的”-”: update students set tel=default where id=5;
將所有人的年齡增加1: update students set age=age+1;
# 將手機號碼 13723887766 的姓名改為 “張果”, 年齡改為 19: update students set name=”張果”, age=19 where tel=”13723887766″;
# 5.5、修改表格
alter table 語句用於建立後對表格的修改, 基礎用法如下:
5.5.1、新增列
# 基本形式: alter table 表名 add 列名 列資料型別 [after 插入位置];
# 範例:
在表格的最後追加列 address: alter table students add address char(60);
在名為 age 的欄位後面插入欄位 birthday: alter table students add birthday date after age;
# 5.5.2、修改列
# 基本形式: alter table 表名 change 列名稱 列新名稱 新資料型別;
範例:
將表格 tel 欄位改名為 phone: alter table students change tel phone char(12) default “-”;
將 name 欄位的資料型別改為 char(9): alter table students change name name char(9) not null;
5.5.3、删除列
基本形式: alter table 表名 drop 列名称;
示例:
删除 age 列: alter table students drop age;
5.5.4、重命名表
基本形式: alter table 表名 rename 新表名;
示例:
重命名 students 表为temp: alter table students rename temp;
5.5.5、删除表
基本形式: drop table 表名;
示例: 删除students表: drop table students;
5.5.6、删除数据库
基本形式: drop database 数据库名;
示例: 删除lcoa数据库: drop database lcoa;
5.5.7、一千行MySQL笔记
/* 启动MySQL */
net start mysql
/* 连接与断开服务器 */
mysql -h 地址 -P 端口 -u 用户名 -p 密码
/* 跳过权限验证登录MySQL */
mysqld --skip-grant-tables
-- 修改root密码
密码加密函数password()
update mysql.user set password=password('root');
SHOW PROCESSLIST -- 显示哪些线程正在运行
SHOW VARIABLES --
/* 数据库操作 */ ------------------
-- 查看当前数据库
select database();
-- 显示当前时间、用户名、数据库版本
select now(), user(), version();
-- 创建库
create database[ if not exists] 数据库名 数据库选项
数据库选项:
CHARACTER SET charset_name
COLLATE collation_name
-- 查看已有库
show databases[ like 'pattern']
-- 查看当前库信息
show create database 数据库名
-- 修改库的选项信息
alter database 库名 选项信息
-- 删除库
drop database[ if exists] 数据库名
同时删除该数据库相关的目录及其目录内容
/* 表的操作 */ ------------------
-- 创建表
create [temporary] table[ if not exists] [库名.]表名 ( 表的结构定义 )[ 表选项]
每个字段必须有数据类型
最后一个字段后不能有逗号
temporary 临时表,会话结束时表自动消失
对于字段的定义:
字段名 数据类型 [NOT NULL | NULL] [DEFAULT default_value] [AUTO_INCREMENT] [UNIQUE [KEY] | [PRIMARY] KEY] [COMMENT 'string']
-- 表选项
-- 字符集
CHARSET = charset_name
如果表没有设定,则使用数据库字符集
-- 存储引擎
ENGINE = engine_name
表在管理数据时采用的不同的数据结构,结构不同会导致处理方式、提供的特性操作等不同
常见的引擎:InnoDB MyISAM Memory/Heap BDB Merge Example CSV MaxDB Archive
不同的引擎在保存表的结构和数据时采用不同的方式
MyISAM表文件含义:.frm表定义,.MYD表数据,.MYI表索引
InnoDB表文件含义:.frm表定义,表空间数据和日志文件
SHOW ENGINES -- 显示存储引擎的状态信息
SHOW ENGINE 引擎名 {LOGS|STATUS} -- 显示存储引擎的日志或状态信息
-- 数据文件目录
DATA DIRECTORY = '目录'
-- 索引文件目录
INDEX DIRECTORY = '目录'
-- 表注释
COMMENT = 'string'
-- 分区选项
PARTITION BY ... (详细见手册)
-- 查看所有表
SHOW TABLES[ LIKE 'pattern']
SHOW TABLES FROM 表名
-- 查看表机构
SHOW CREATE TABLE 表名 (信息更详细)
DESC 表名 / DESCRIBE 表名 / EXPLAIN 表名 / SHOW COLUMNS FROM 表名 [LIKE 'PATTERN']
SHOW TABLE STATUS [FROM db_name] [LIKE 'pattern']
-- 修改表
-- 修改表本身的选项
ALTER TABLE 表名 表的选项
EG: ALTER TABLE 表名 ENGINE=MYISAM;
-- 对表进行重命名
RENAME TABLE 原表名 TO 新表名
RENAME TABLE 原表名 TO 库名.表名 (可将表移动到另一个数据库)
-- RENAME可以交换两个表名
-- 修改表的字段机构
ALTER TABLE 表名 操作名
-- 操作名
ADD[ COLUMN] 字段名 -- 增加字段
AFTER 字段名 -- 表示增加在该字段名后面
FIRST -- 表示增加在第一个
ADD PRIMARY KEY(字段名) -- 创建主键
ADD UNIQUE [索引名] (字段名)-- 创建唯一索引
ADD INDEX [索引名] (字段名) -- 创建普通索引
ADD
DROP[ COLUMN] 字段名 -- 删除字段
MODIFY[ COLUMN] 字段名 字段属性 -- 支持对字段属性进行修改,不能修改字段名(所有原有属性也需写上)
CHANGE[ COLUMN] 原字段名 新字段名 字段属性 -- 支持对字段名修改
DROP PRIMARY KEY -- 删除主键(删除主键前需删除其AUTO_INCREMENT属性)
DROP INDEX 索引名 -- 删除索引
DROP FOREIGN KEY 外键 -- 删除外键
-- 删除表
DROP TABLE[ IF EXISTS] 表名 ...
-- 清空表数据
TRUNCATE [TABLE] 表名
-- 复制表结构
CREATE TABLE 表名 LIKE 要复制的表名
-- 复制表结构和数据
CREATE TABLE 表名 [AS] SELECT * FROM 要复制的表名
-- 检查表是否有错误
CHECK TABLE tbl_name [, tbl_name] ... [option] ...
-- 优化表
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
-- 修复表
REPAIR [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ... [QUICK] [EXTENDED] [USE_FRM]
-- 分析表
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
/* 数据操作 */ ------------------
-- 增
INSERT [INTO] 表名 [(字段列表)] VALUES (值列表)[, (值列表), ...]
-- 如果要插入的值列表包含所有字段并且顺序一致,则可以省略字段列表。
-- 可同时插入多条数据记录!
REPLACE 与 INSERT 完全一样,可互换。
INSERT [INTO] 表名 SET 字段名=值[, 字段名=值, ...]
-- 查
SELECT 字段列表 FROM 表名[ 其他子句]
-- 可来自多个表的多个字段
-- 其他子句可以不使用
-- 字段列表可以用*代替,表示所有字段
-- 删
DELETE FROM 表名[ 删除条件子句]
没有条件子句,则会删除全部
-- 改
UPDATE 表名 SET 字段名=新值[, 字段名=新值] [更新条件]
/* 字符集编码 */ ------------------
-- MySQL、数据库、表、字段均可设置编码
-- 数据编码与客户端编码不需一致
SHOW VARIABLES LIKE 'character_set_%' -- 查看所有字符集编码项
character_set_client 客户端向服务器发送数据时使用的编码
character_set_results 服务器端将结果返回给客户端所使用的编码
character_set_connection 连接层编码
SET 变量名 = 变量值
set character_set_client = gbk;
set character_set_results = gbk;
set character_set_connection = gbk;
SET NAMES GBK; -- 相当于完成以上三个设置
-- 校对集
校对集用以排序
SHOW CHARACTER SET [LIKE 'pattern']/SHOW CHARSET [LIKE 'pattern'] 查看所有字符集
SHOW COLLATION [LIKE 'pattern'] 查看所有校对集
charset 字符集编码 设置字符集编码
collate 校对集编码 设置校对集编码
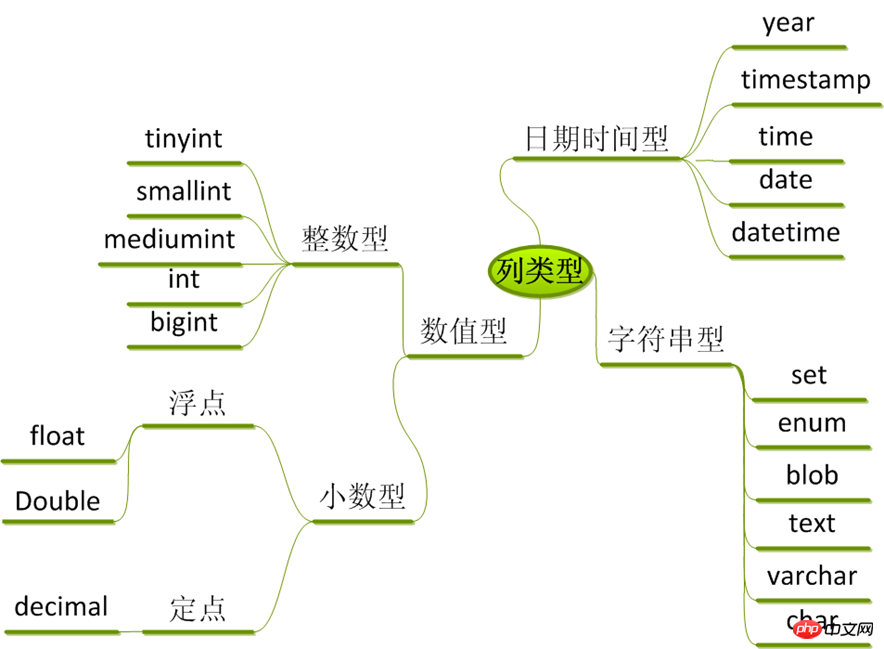
/* 数据类型(列类型) */ ------------------
1. 数值类型
-- a. 整型 ----------
类型 字节 范围(有符号位)
tinyint 1字节 -128 ~ 127 无符号位:0 ~ 255
smallint 2字节 -32768 ~ 32767
mediumint 3字节 -8388608 ~ 8388607
int 4字节
bigint 8字节
int(M) M表示总位数
- 默认存在符号位,unsigned 属性修改
- 显示宽度,如果某个数不够定义字段时设置的位数,则前面以0补填,zerofill 属性修改
例:int(5) 插入一个数'123',补填后为'00123'
- 在满足要求的情况下,越小越好。
- 1表示bool值真,0表示bool值假。MySQL没有布尔类型,通过整型0和1表示。常用tinyint(1)表示布尔型。
-- b. 浮点型 ----------
类型 字节 范围
float(单精度) 4字节
double(双精度) 8字节
浮点型既支持符号位 unsigned 属性,也支持显示宽度 zerofill 属性。
不同于整型,前后均会补填0.
定义浮点型时,需指定总位数和小数位数。
float(M, D) double(M, D)
M表示总位数,D表示小数位数。
M和D的大小会决定浮点数的范围。不同于整型的固定范围。
M既表示总位数(不包括小数点和正负号),也表示显示宽度(所有显示符号均包括)。
支持科学计数法表示。
浮点数表示近似值。
-- c. 定点数 ----------
decimal -- 可变长度
decimal(M, D) M也表示总位数,D表示小数位数。
保存一个精确的数值,不会发生数据的改变,不同于浮点数的四舍五入。
将浮点数转换为字符串来保存,每9位数字保存为4个字节。
2. 字符串类型
-- a. char, varchar ----------
char 定长字符串,速度快,但浪费空间
varchar 变长字符串,速度慢,但节省空间
M表示能存储的最大长度,此长度是字符数,非字节数。
不同的编码,所占用的空间不同。
char,最多255个字符,与编码无关。
varchar,最多65535字符,与编码有关。
一条有效记录最大不能超过65535个字节。
utf8 最大为21844个字符,gbk 最大为32766个字符,latin1 最大为65532个字符
varchar 是变长的,需要利用存储空间保存 varchar 的长度,如果数据小于255个字节,则采用一个字节来保存长度,反之需要两个字节来保存。
varchar 的最大有效长度由最大行大小和使用的字符集确定。
最大有效长度是65532字节,因为在varchar存字符串时,第一个字节是空的,不存在任何数据,然后还需两个字节来存放字符串的长度,所以有效长度是64432-1-2=65532字节。
例:若一个表定义为 CREATE TABLE tb(c1 int, c2 char(30), c3 varchar(N)) charset=utf8; 问N的最大值是多少? 答:(65535-1-2-4-30*3)/3
-- b. blob, text ----------
blob 二进制字符串(字节字符串)
tinyblob, blob, mediumblob, longblob
text 非二进制字符串(字符字符串)
tinytext, text, mediumtext, longtext
text 在定义时,不需要定义长度,也不会计算总长度。
text 类型在定义时,不可给default值
-- c. binary, varbinary ----------
类似于char和varchar,用于保存二进制字符串,也就是保存字节字符串而非字符字符串。
char, varchar, text 对应 binary, varbinary, blob.
3. 日期时间类型
一般用整型保存时间戳,因为PHP可以很方便的将时间戳进行格式化。
datetime 8字节 日期及时间 1000-01-01 00:00:00 到 9999-12-31 23:59:59
date 3字节 日期 1000-01-01 到 9999-12-31
timestamp 4字节 时间戳 19700101000000 到 2038-01-19 03:14:07
time 3字节 时间 -838:59:59 到 838:59:59
year 1字节 年份 1901 - 2155
datetime “YYYY-MM-DD hh:mm:ss”
timestamp “YY-MM-DD hh:mm:ss”
“YYYYMMDDhhmmss”
“YYMMDDhhmmss”
YYYYMMDDhhmmss
YYMMDDhhmmss
date “YYYY-MM-DD”
“YY-MM-DD”
“YYYYMMDD”
“YYMMDD”
YYYYMMDD
YYMMDD
time “hh:mm:ss”
“hhmmss”
hhmmss
year “YYYY”
“YY”
YYYY
YY
4. 枚举和集合
-- 枚举(enum) ----------
enum(val1, val2, val3...)
在已知的值中进行单选。最大数量为65535.
枚举值在保存时,以2个字节的整型(smallint)保存。每个枚举值,按保存的位置顺序,从1开始逐一递增。
表现为字符串类型,存储却是整型。
NULL值的索引是NULL。
空字符串错误值的索引值是0。
-- 集合(set) ----------
set(val1, val2, val3...)
create table tab ( gender set('男', '女', '无') );
insert into tab values ('男, 女');
最多可以有64个不同的成员。以bigint存储,共8个字节。采取位运算的形式。
当创建表时,SET成员值的尾部空格将自动被删除。
/* 选择类型 */
-- PHP角度
1. 功能满足
2. 存储空间尽量小,处理效率更高
3. 考虑兼容问题
-- IP存储 ----------
1. 只需存储,可用字符串
2. 如果需计算,查找等,可存储为4个字节的无符号int,即unsigned
1) PHP函数转换
ip2long可转换为整型,但会出现携带符号问题。需格式化为无符号的整型。
利用sprintf函数格式化字符串
sprintf("%u", ip2long('192.168.3.134'));
然后用long2ip将整型转回IP字符串
2) MySQL函数转换(无符号整型,UNSIGNED)
INET_ATON('127.0.0.1') 将IP转为整型
INET_NTOA(2130706433) 将整型转为IP
/* 列属性(列约束) */ ------------------
1. 主键
- 能唯一标识记录的字段,可以作为主键。
- 一个表只能有一个主键。
- 主键具有唯一性。
- 声明字段时,用 primary key 标识。
也可以在字段列表之后声明
例:create table tab ( id int, stu varchar(10), primary key (id));
- 主键字段的值不能为null。
- 主键可以由多个字段共同组成。此时需要在字段列表后声明的方法。
例:create table tab ( id int, stu varchar(10), age int, primary key (stu, age));
2. unique 唯一索引(唯一约束)
使得某字段的值也不能重复。
3. null 约束
null不是数据类型,是列的一个属性。
表示当前列是否可以为null,表示什么都没有。
null, 允许为空。默认。
not null, 不允许为空。
insert into tab values (null, 'val');
-- 此时表示将第一个字段的值设为null, 取决于该字段是否允许为null
4. default 默认值属性
当前字段的默认值。
insert into tab values (default, 'val'); -- 此时表示强制使用默认值。
create table tab ( add_time timestamp default current_timestamp );
-- 表示将当前时间的时间戳设为默认值。
current_date, current_time
5. auto_increment 自动增长约束
自动增长必须为索引(主键或unique)
只能存在一个字段为自动增长。
默认为1开始自动增长。可以通过表属性 auto_increment = x进行设置,或 alter table tbl auto_increment = x;
6. comment 注释
例:create table tab ( id int ) comment '注释内容';
7. foreign key 外键约束
用于限制主表与从表数据完整性。
alter table t1 add constraint `t1_t2_fk` foreign key (t1_id) references t2(id);
-- 将表t1的t1_id外键关联到表t2的id字段。
-- 每个外键都有一个名字,可以通过 constraint 指定
存在外键的表,称之为从表(子表),外键指向的表,称之为主表(父表)。
作用:保持数据一致性,完整性,主要目的是控制存储在外键表(从表)中的数据。
MySQL中,可以对InnoDB引擎使用外键约束:
语法:
foreign key (外键字段) references 主表名 (关联字段) [主表记录删除时的动作] [主表记录更新时的动作]
此时需要检测一个从表的外键需要约束为主表的已存在的值。外键在没有关联的情况下,可以设置为null.前提是该外键列,没有not null。
可以不指定主表记录更改或更新时的动作,那么此时主表的操作被拒绝。
如果指定了 on update 或 on delete:在删除或更新时,有如下几个操作可以选择:
1. cascade,级联操作。主表数据被更新(主键值更新),从表也被更新(外键值更新)。主表记录被删除,从表相关记录也被删除。
2. set null,设置为null。主表数据被更新(主键值更新),从表的外键被设置为null。主表记录被删除,从表相关记录外键被设置成null。但注意,要求该外键列,没有not null属性约束。
3. restrict,拒绝父表删除和更新。
注意,外键只被InnoDB存储引擎所支持。其他引擎是不支持的。
/* 建表规范 */ ------------------
-- Normal Format, NF
- 每个表保存一个实体信息
- 每个具有一个ID字段作为主键
- ID主键 + 原子表
-- 1NF, 第一范式
字段不能再分,就满足第一范式。
-- 2NF, 第二范式
满足第一范式的前提下,不能出现部分依赖。
消除符合主键就可以避免部分依赖。增加单列关键字。
-- 3NF, 第三范式
满足第二范式的前提下,不能出现传递依赖。
某个字段依赖于主键,而有其他字段依赖于该字段。这就是传递依赖。
将一个实体信息的数据放在一个表内实现。
/* select */ ------------------
select [all|distinct] select_expr from -> where -> group by [合计函数] -> having -> order by -> limit
a. select_expr
-- 可以用 * 表示所有字段。
select * from tb;
-- 可以使用表达式(计算公式、函数调用、字段也是个表达式)
select stu, 29+25, now() from tb;
-- 可以为每个列使用别名。适用于简化列标识,避免多个列标识符重复。
- 使用 as 关键字,也可省略 as.
select stu+10 as add10 from tb;
b. from 子句
用于标识查询来源。
-- 可以为表起别名。使用as关键字。
select * from tb1 as tt, tb2 as bb;
-- from子句后,可以同时出现多个表。
-- 多个表会横向叠加到一起,而数据会形成一个笛卡尔积。
select * from tb1, tb2;
c. where 子句
-- 从from获得的数据源中进行筛选。
-- 整型1表示真,0表示假。
-- 表达式由运算符和运算数组成。
-- 运算数:变量(字段)、值、函数返回值
-- 运算符:
=, <=>, <>, !=, <=, <, >=, >, !, &&, ||,
in (not) null, (not) like, (not) in, (not) between and, is (not), and, or, not, xor
is/is not 加上ture/false/unknown,检验某个值的真假
<=>与<>功能相同,<=>可用于null比较
d. group by 子句, 分组子句
group by 字段/别名 [排序方式]
分组后会进行排序。升序:ASC,降序:DESC
以下[合计函数]需配合 group by 使用:
count 返回不同的非NULL值数目 count(*)、count(字段)
sum 求和
max 求最大值
min 求最小值
avg 求平均值
group_concat 返回带有来自一个组的连接的非NULL值的字符串结果。组内字符串连接。
e. having 子句,条件子句
与 where 功能、用法相同,执行时机不同。
where 在开始时执行检测数据,对原数据进行过滤。
having 对筛选出的结果再次进行过滤。
having 字段必须是查询出来的,where 字段必须是数据表存在的。
where 不可以使用字段的别名,having 可以。因为执行WHERE代码时,可能尚未确定列值。
where 不可以使用合计函数。一般需用合计函数才会用 having
SQL标准要求HAVING必须引用GROUP BY子句中的列或用于合计函数中的列。
f. order by 子句,排序子句
order by 排序字段/别名 排序方式 [,排序字段/别名 排序方式]...
升序:ASC,降序:DESC
支持多个字段的排序。
g. limit 子句,限制结果数量子句
仅对处理好的结果进行数量限制。将处理好的结果的看作是一个集合,按照记录出现的顺序,索引从0开始。
limit 起始位置, 获取条数
省略第一个参数,表示从索引0开始。limit 获取条数
h. distinct, all 选项
distinct 去除重复记录
默认为 all, 全部记录
/* UNION */ ------------------
将多个select查询的结果组合成一个结果集合。
SELECT ... UNION [ALL|DISTINCT] SELECT ...
默认 DISTINCT 方式,即所有返回的行都是唯一的
建议,对每个SELECT查询加上小括号包裹。
ORDER BY 排序时,需加上 LIMIT 进行结合。
需要各select查询的字段数量一样。
每个select查询的字段列表(数量、类型)应一致,因为结果中的字段名以第一条select语句为准。
/* 子查询 */ ------------------
- 子查询需用括号包裹。
-- from型
from后要求是一个表,必须给子查询结果取个别名。
- 简化每个查询内的条件。
- from型需将结果生成一个临时表格,可用以原表的锁定的释放。
- 子查询返回一个表,表型子查询。
select * from (select * from tb where id>0) as subfrom where id>1;
-- where型
- 子查询返回一个值,标量子查询。
- 不需要给子查询取别名。
- where子查询内的表,不能直接用以更新。
select * from tb where money = (select max(money) from tb);
-- 列子查询
如果子查询结果返回的是一列。
使用 in 或 not in 完成查询
exists 和 not exists 条件
如果子查询返回数据,则返回1或0。常用于判断条件。
select column1 from t1 where exists (select * from t2);
-- 行子查询
查询条件是一个行。
select * from t1 where (id, gender) in (select id, gender from t2);
行构造符:(col1, col2, ...) 或 ROW(col1, col2, ...)
行构造符通常用于与对能返回两个或两个以上列的子查询进行比较。
-- 特殊运算符
!= all() 相当于 not in
= some() 相当于 in。any 是 some 的别名
!= some() 不等同于 not in,不等于其中某一个。
all, some 可以配合其他运算符一起使用。
/* 连接查询(join) */ ------------------
将多个表的字段进行连接,可以指定连接条件。
-- 内连接(inner join)
- 默认就是内连接,可省略inner。
- 只有数据存在时才能发送连接。即连接结果不能出现空行。
on 表示连接条件。其条件表达式与where类似。也可以省略条件(表示条件永远为真)
也可用where表示连接条件。
还有 using, 但需字段名相同。 using(字段名)
-- 交叉连接 cross join
即,没有条件的内连接。
select * from tb1 cross join tb2;
-- 外连接(outer join)
- 如果数据不存在,也会出现在连接结果中。
-- 左外连接 left join
如果数据不存在,左表记录会出现,而右表为null填充
-- 右外连接 right join
如果数据不存在,右表记录会出现,而左表为null填充
-- 自然连接(natural join)
自动判断连接条件完成连接。
相当于省略了using,会自动查找相同字段名。
natural join
natural left join
natural right join
select info.id, info.name, info.stu_num, extra_info.hobby, extra_info.sex from info, extra_info where info.stu_num = extra_info.stu_id;
/* 导入导出 */ ------------------
select * into outfile 文件地址 [控制格式] from 表名; -- 导出表数据
load data [local] infile 文件地址 [replace|ignore] into table 表名 [控制格式]; -- 导入数据
生成的数据默认的分隔符是制表符
local未指定,则数据文件必须在服务器上
replace 和 ignore 关键词控制对现有的唯一键记录的重复的处理
-- 控制格式
fields 控制字段格式
默认:fields terminated by '\t' enclosed by '' escaped by '\\'
terminated by 'string' -- 终止
enclosed by 'char' -- 包裹
escaped by 'char' -- 转义
-- 示例:
SELECT a,b,a+b INTO OUTFILE '/tmp/result.text'
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'
FROM test_table;
lines 控制行格式
默认:lines terminated by '\n'
terminated by 'string' -- 终止
/* insert */ ------------------
select语句获得的数据可以用insert插入。
可以省略对列的指定,要求 values () 括号内,提供给了按照列顺序出现的所有字段的值。
或者使用set语法。
insert into tbl_name set field=value,...;
可以一次性使用多个值,采用(), (), ();的形式。
insert into tbl_name values (), (), ();
可以在列值指定时,使用表达式。
insert into tbl_name values (field_value, 10+10, now());
可以使用一个特殊值 default,表示该列使用默认值。
insert into tbl_name values (field_value, default);
可以通过一个查询的结果,作为需要插入的值。
insert into tbl_name select ...;
可以指定在插入的值出现主键(或唯一索引)冲突时,更新其他非主键列的信息。
insert into tbl_name values/set/select on duplicate key update 字段=值, …;
/* delete */ ------------------
DELETE FROM tbl_name [WHERE where_definition] [ORDER BY ...] [LIMIT row_count]
按照条件删除
指定删除的最多记录数。Limit
可以通过排序条件删除。order by + limit
支持多表删除,使用类似连接语法。
delete from 需要删除数据多表1,表2 using 表连接操作 条件。
/* truncate */ ------------------
TRUNCATE [TABLE] tbl_name
清空数据
删除重建表
区别:
1,truncate 是删除表再创建,delete 是逐条删除
2,truncate 重置auto_increment的值。而delete不会
3,truncate 不知道删除了几条,而delete知道。
4,当被用于带分区的表时,truncate 会保留分区
/* 备份与还原 */ ------------------
备份,将数据的结构与表内数据保存起来。
利用 mysqldump 指令完成。
-- 导出
1. 导出一张表
mysqldump -u用户名 -p密码 库名 表名 > 文件名(D:/a.sql)
2. 导出多张表
mysqldump -u用户名 -p密码 库名 表1 表2 表3 > 文件名(D:/a.sql)
3. 导出所有表
mysqldump -u用户名 -p密码 库名 > 文件名(D:/a.sql)
4. 导出一个库
mysqldump -u用户名 -p密码 -B 库名 > 文件名(D:/a.sql)
可以-w携带备份条件
-- 导入
1. 在登录mysql的情况下:
source 备份文件
2. 在不登录的情况下
mysql -u用户名 -p密码 库名 < 备份文件
/* 视图 */ ------------------
什么是视图:
视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储的数据值集形式存在。行和列数据来自由定义视图的查询所引用的表,并且在引用视图时动态生成。
视图具有表结构文件,但不存在数据文件。
对其中所引用的基础表来说,视图的作用类似于筛选。定义视图的筛选可以来自当前或其它数据库的一个或多个表,或者其它视图。通过视图进行查询没有任何限制,通过它们进行数据修改时的限制也很少。
视图是存储在数据库中的查询的sql语句,它主要出于两种原因:安全原因,视图可以隐藏一些数据,如:社会保险基金表,可以用视图只显示姓名,地址,而不显示社会保险号和工资数等,另一原因是可使复杂的查询易于理解和使用。
-- 创建视图
CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] VIEW view_name [(column_list)] AS select_statement
- 视图名必须唯一,同时不能与表重名。
- 视图可以使用select语句查询到的列名,也可以自己指定相应的列名。
- 可以指定视图执行的算法,通过ALGORITHM指定。
- column_list如果存在,则数目必须等于SELECT语句检索的列数
-- 查看结构
SHOW CREATE VIEW view_name
-- 删除视图
- 删除视图后,数据依然存在。
- 可同时删除多个视图。
DROP VIEW [IF EXISTS] view_name ...
-- 修改视图结构
- 一般不修改视图,因为不是所有的更新视图都会映射到表上。
ALTER VIEW view_name [(column_list)] AS select_statement
-- 视图作用
1. 简化业务逻辑
2. 对客户端隐藏真实的表结构
-- 视图算法(ALGORITHM)
MERGE 合并
将视图的查询语句,与外部查询需要先合并再执行!
TEMPTABLE 临时表
将视图执行完毕后,形成临时表,再做外层查询!
UNDEFINED 未定义(默认),指的是MySQL自主去选择相应的算法。
/* 事务(transaction) */ ------------------
事务是指逻辑上的一组操作,组成这组操作的各个单元,要不全成功要不全失败。
- 支持连续SQL的集体成功或集体撤销。
- 事务是数据库在数据晚自习方面的一个功能。
- 需要利用 InnoDB 或 BDB 存储引擎,对自动提交的特性支持完成。
- InnoDB被称为事务安全型引擎。
-- 事务开启
START TRANSACTION; 或者 BEGIN;
开启事务后,所有被执行的SQL语句均被认作当前事务内的SQL语句。
-- 事务提交
COMMIT;
-- 事务回滚
ROLLBACK;
如果部分操作发生问题,映射到事务开启前。
-- 事务的特性
1. 原子性(Atomicity)
事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
2. 一致性(Consistency)
事务前后数据的完整性必须保持一致。
- 事务开始和结束时,外部数据一致
- 在整个事务过程中,操作是连续的
3. 隔离性(Isolation)
多个用户并发访问数据库时,一个用户的事务不能被其它用户的事物所干扰,多个并发事务之间的数据要相互隔离。
4. 持久性(Durability)
一个事务一旦被提交,它对数据库中的数据改变就是永久性的。
-- 事务的实现
1. 要求是事务支持的表类型
2. 执行一组相关的操作前开启事务
3. 整组操作完成后,都成功,则提交;如果存在失败,选择回滚,则会回到事务开始的备份点。
-- 事务的原理
利用InnoDB的自动提交(autocommit)特性完成。
普通的MySQL执行语句后,当前的数据提交操作均可被其他客户端可见。
而事务是暂时关闭“自动提交”机制,需要commit提交持久化数据操作。
-- 注意
1. 数据定义语言(DDL)语句不能被回滚,比如创建或取消数据库的语句,和创建、取消或更改表或存储的子程序的语句。
2. 事务不能被嵌套
-- 保存点
SAVEPOINT 保存点名称 -- 设置一个事务保存点
ROLLBACK TO SAVEPOINT 保存点名称 -- 回滚到保存点
RELEASE SAVEPOINT 保存点名称 -- 删除保存点
-- InnoDB自动提交特性设置
SET autocommit = 0|1; 0表示关闭自动提交,1表示开启自动提交。
- 如果关闭了,那普通操作的结果对其他客户端也不可见,需要commit提交后才能持久化数据操作。
- 也可以关闭自动提交来开启事务。但与START TRANSACTION不同的是,
SET autocommit是永久改变服务器的设置,直到下次再次修改该设置。(针对当前连接)
而START TRANSACTION记录开启前的状态,而一旦事务提交或回滚后就需要再次开启事务。(针对当前事务)
/* 锁表 */
表锁定只用于防止其它客户端进行不正当地读取和写入
MyISAM 支持表锁,InnoDB 支持行锁
-- 锁定
LOCK TABLES tbl_name [AS alias]
-- 解锁
UNLOCK TABLES
/* 触发器 */ ------------------
触发程序是与表有关的命名数据库对象,当该表出现特定事件时,将激活该对象
监听:记录的增加、修改、删除。
-- 创建触发器
CREATE TRIGGER trigger_name trigger_time trigger_event ON tbl_name FOR EACH ROW trigger_stmt
参数:
trigger_time是触发程序的动作时间。它可以是 before 或 after,以指明触发程序是在激活它的语句之前或之后触发。
trigger_event指明了激活触发程序的语句的类型
INSERT:将新行插入表时激活触发程序
UPDATE:更改某一行时激活触发程序
DELETE:从表中删除某一行时激活触发程序
tbl_name:监听的表,必须是永久性的表,不能将触发程序与TEMPORARY表或视图关联起来。
trigger_stmt:当触发程序激活时执行的语句。执行多个语句,可使用BEGIN...END复合语句结构
-- 删除
DROP TRIGGER [schema_name.]trigger_name
可以使用old和new代替旧的和新的数据
更新操作,更新前是old,更新后是new.
删除操作,只有old.
增加操作,只有new.
-- 注意
1. 对于具有相同触发程序动作时间和事件的给定表,不能有两个触发程序。
-- 字符连接函数
concat(str1[, str2,...])
-- 分支语句
if 条件 then
执行语句
elseif 条件 then
执行语句
else
执行语句
end if;
-- 修改最外层语句结束符
delimiter 自定义结束符号
SQL语句
自定义结束符号
delimiter ; -- 修改回原来的分号
-- 语句块包裹
begin
语句块
end
-- 特殊的执行
1. 只要添加记录,就会触发程序。
2. Insert into on duplicate key update 语法会触发:
如果没有重复记录,会触发 before insert, after insert;
如果有重复记录并更新,会触发 before insert, before update, after update;
如果有重复记录但是没有发生更新,则触发 before insert, before update
3. Replace 语法 如果有记录,则执行 before insert, before delete, after delete, after insert
/* SQL编程 */ ------------------
--// 局部变量 ----------
-- 变量声明
declare var_name[,...] type [default value]
这个语句被用来声明局部变量。要给变量提供一个默认值,请包含一个default子句。值可以被指定为一个表达式,不需要为一个常数。如果没有default子句,初始值为null。
-- 赋值
使用 set 和 select into 语句为变量赋值。
- 注意:在函数内是可以使用全局变量(用户自定义的变量)
--// 全局变量 ----------
-- 定义、赋值
set 语句可以定义并为变量赋值。
set @var = value;
也可以使用select into语句为变量初始化并赋值。这样要求select语句只能返回一行,但是可以是多个字段,就意味着同时为多个变量进行赋值,变量的数量需要与查询的列数一致。
还可以把赋值语句看作一个表达式,通过select执行完成。此时为了避免=被当作关系运算符看待,使用:=代替。(set语句可以使用= 和 :=)。
select @var:=20;
select @v1:=id, @v2=name from t1 limit 1;
select * from tbl_name where @var:=30;
select into 可以将表中查询获得的数据赋给变量。
-| select max(height) into @max_height from tb;
-- 自定义变量名
为了避免select语句中,用户自定义的变量与系统标识符(通常是字段名)冲突,用户自定义变量在变量名前使用@作为开始符号。
@var=10;
- 变量被定义后,在整个会话周期都有效(登录到退出)
--// 控制结构 ----------
-- if语句
if search_condition then
statement_list
[elseif search_condition then
statement_list]
...
[else
statement_list]
end if;
-- case语句
CASE value WHEN [compare-value] THEN result
[WHEN [compare-value] THEN result ...]
[ELSE result]
END
-- while循环
[begin_label:] while search_condition do
statement_list
end while [end_label];
- 如果需要在循环内提前终止 while循环,则需要使用标签;标签需要成对出现。
-- 退出循环
退出整个循环 leave
退出当前循环 iterate
通过退出的标签决定退出哪个循环
--// 内置函数 ----------
-- 数值函数
abs(x) -- 绝对值 abs(-10.9) = 10
format(x, d) -- 格式化千分位数值 format(1234567.456, 2) = 1,234,567.46
ceil(x) -- 向上取整 ceil(10.1) = 11
floor(x) -- 向下取整 floor (10.1) = 10
round(x) -- 四舍五入去整
mod(m, n) -- m%n m mod n 求余 10%3=1
pi() -- 获得圆周率
pow(m, n) -- m^n
sqrt(x) -- 算术平方根
rand() -- 随机数
truncate(x, d) -- 截取d位小数
-- 时间日期函数
now(), current_timestamp(); -- 当前日期时间
current_date(); -- 当前日期
current_time(); -- 当前时间
date('yyyy-mm-dd hh:ii:ss'); -- 获取日期部分
time('yyyy-mm-dd hh:ii:ss'); -- 获取时间部分
date_format('yyyy-mm-dd hh:ii:ss', '%d %y %a %d %m %b %j'); -- 格式化时间
unix_timestamp(); -- 获得unix时间戳
from_unixtime(); -- 从时间戳获得时间
-- 字符串函数
length(string) -- string长度,字节
char_length(string) -- string的字符个数
substring(str, position [,length]) -- 从str的position开始,取length个字符
replace(str ,search_str ,replace_str) -- 在str中用replace_str替换search_str
instr(string ,substring) -- 返回substring首次在string中出现的位置
concat(string [,...]) -- 连接字串
charset(str) -- 返回字串字符集
lcase(string) -- 转换成小写
left(string, length) -- 从string2中的左边起取length个字符
load_file(file_name) -- 从文件读取内容
locate(substring, string [,start_position]) -- 同instr,但可指定开始位置
lpad(string, length, pad) -- 重复用pad加在string开头,直到字串长度为length
ltrim(string) -- 去除前端空格
repeat(string, count) -- 重复count次
rpad(string, length, pad) --在str后用pad补充,直到长度为length
rtrim(string) -- 去除后端空格
strcmp(string1 ,string2) -- 逐字符比较两字串大小
-- 流程函数
case when [condition] then result [when [condition] then result ...] [else result] end 多分支
if(expr1,expr2,expr3) 双分支。
-- 聚合函数
count()
sum();
max();
min();
avg();
group_concat()
-- 其他常用函数
md5();
default();
--// 存储函数,自定义函数 ----------
-- 新建
CREATE FUNCTION function_name (参数列表) RETURNS 返回值类型
函数体
- 函数名,应该合法的标识符,并且不应该与已有的关键字冲突。
- 一个函数应该属于某个数据库,可以使用db_name.funciton_name的形式执行当前函数所属数据库,否则为当前数据库。
- 参数部分,由"参数名"和"参数类型"组成。多个参数用逗号隔开。
- 函数体由多条可用的mysql语句,流程控制,变量声明等语句构成。
- 多条语句应该使用 begin...end 语句块包含。
- 一定要有 return 返回值语句。
-- 删除
DROP FUNCTION [IF EXISTS] function_name;
-- 查看
SHOW FUNCTION STATUS LIKE 'partten'
SHOW CREATE FUNCTION function_name;
-- 修改
ALTER FUNCTION function_name 函数选项
--// 存储过程,自定义功能 ----------
-- 定义
存储存储过程 是一段代码(过程),存储在数据库中的sql组成。
一个存储过程通常用于完成一段业务逻辑,例如报名,交班费,订单入库等。
而一个函数通常专注与某个功能,视为其他程序服务的,需要在其他语句中调用函数才可以,而存储过程不能被其他调用,是自己执行 通过call执行。
-- 创建
CREATE PROCEDURE sp_name (参数列表)
过程体
参数列表:不同于函数的参数列表,需要指明参数类型
IN,表示输入型
OUT,表示输出型
INOUT,表示混合型
注意,没有返回值。
/* 存储过程 */ ------------------
存储过程是一段可执行性代码的集合。相比函数,更偏向于业务逻辑。
调用:CALL 过程名
-- 注意
- 没有返回值。
- 只能单独调用,不可夹杂在其他语句中
-- 参数
IN|OUT|INOUT 参数名 数据类型
IN 输入:在调用过程中,将数据输入到过程体内部的参数
OUT 输出:在调用过程中,将过程体处理完的结果返回到客户端
INOUT 输入输出:既可输入,也可输出
-- 语法
CREATE PROCEDURE 过程名 (参数列表)
BEGIN
过程体
END
/* 用户和权限管理 */ ------------------
用户信息表:mysql.user
-- 刷新权限
FLUSH PRIVILEGES
-- 增加用户
CREATE USER 用户名 IDENTIFIED BY [PASSWORD] 密码(字符串)
- 必须拥有mysql数据库的全局CREATE USER权限,或拥有INSERT权限。
- 只能创建用户,不能赋予权限。
- 用户名,注意引号:如 'user_name'@'192.168.1.1'
- 密码也需引号,纯数字密码也要加引号
- 要在纯文本中指定密码,需忽略PASSWORD关键词。要把密码指定为由PASSWORD()函数返回的混编值,需包含关键字PASSWORD
-- 重命名用户
RENAME USER old_user TO new_user
-- 设置密码
SET PASSWORD = PASSWORD('密码') -- 为当前用户设置密码
SET PASSWORD FOR 用户名 = PASSWORD('密码') -- 为指定用户设置密码
-- 删除用户
DROP USER 用户名
-- 分配权限/添加用户
GRANT 权限列表 ON 表名 TO 用户名 [IDENTIFIED BY [PASSWORD] 'password']
- all privileges 表示所有权限
- *.* 表示所有库的所有表
- 库名.表名 表示某库下面的某表
-- 查看权限
SHOW GRANTS FOR 用户名
-- 查看当前用户权限
SHOW GRANTS; 或 SHOW GRANTS FOR CURRENT_USER; 或 SHOW GRANTS FOR CURRENT_USER();
-- 撤消权限
REVOKE 权限列表 ON 表名 FROM 用户名
REVOKE ALL PRIVILEGES, GRANT OPTION FROM 用户名 -- 撤销所有权限
-- 权限层级
-- 要使用GRANT或REVOKE,您必须拥有GRANT OPTION权限,并且您必须用于您正在授予或撤销的权限。
全局层级:全局权限适用于一个给定服务器中的所有数据库,mysql.user
GRANT ALL ON *.*和 REVOKE ALL ON *.*只授予和撤销全局权限。
数据库层级:数据库权限适用于一个给定数据库中的所有目标,mysql.db, mysql.host
GRANT ALL ON db_name.*和REVOKE ALL ON db_name.*只授予和撤销数据库权限。
表层级:表权限适用于一个给定表中的所有列,mysql.talbes_priv
GRANT ALL ON db_name.tbl_name和REVOKE ALL ON db_name.tbl_name只授予和撤销表权限。
列层级:列权限适用于一个给定表中的单一列,mysql.columns_priv
当使用REVOKE时,您必须指定与被授权列相同的列。
-- 权限列表
ALL [PRIVILEGES] -- 设置除GRANT OPTION之外的所有简单权限
ALTER -- 允许使用ALTER TABLE
ALTER ROUTINE -- 更改或取消已存储的子程序
CREATE -- 允许使用CREATE TABLE
CREATE ROUTINE -- 创建已存储的子程序
CREATE TEMPORARY TABLES -- 允许使用CREATE TEMPORARY TABLE
CREATE USER -- 允许使用CREATE USER, DROP USER, RENAME USER和REVOKE ALL PRIVILEGES。
CREATE VIEW -- 允许使用CREATE VIEW
DELETE -- 允许使用DELETE
DROP -- 允许使用DROP TABLE
EXECUTE -- 允许用户运行已存储的子程序
FILE -- 允许使用SELECT...INTO OUTFILE和LOAD DATA INFILE
INDEX -- 允许使用CREATE INDEX和DROP INDEX
INSERT -- 允许使用INSERT
LOCK TABLES -- 允许对您拥有SELECT权限的表使用LOCK TABLES
PROCESS -- 允许使用SHOW FULL PROCESSLIST
REFERENCES -- 未被实施
RELOAD -- 允许使用FLUSH
REPLICATION CLIENT -- 允许用户询问从属服务器或主服务器的地址
REPLICATION SLAVE -- 用于复制型从属服务器(从主服务器中读取二进制日志事件)
SELECT -- 允许使用SELECT
SHOW DATABASES -- 显示所有数据库
SHOW VIEW -- 允许使用SHOW CREATE VIEW
SHUTDOWN -- 允许使用mysqladmin shutdown
SUPER -- 允许使用CHANGE MASTER, KILL, PURGE MASTER LOGS和SET GLOBAL语句,mysqladmin debug命令;允许您连接(一次),即使已达到max_connections。
UPDATE -- 允许使用UPDATE
USAGE -- “无权限”的同义词
GRANT OPTION -- 允许授予权限
/* 表维护 */
-- 分析和存储表的关键字分布
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE 表名 ...
-- 检查一个或多个表是否有错误
CHECK TABLE tbl_name [, tbl_name] ... [option] ...
option = {QUICK | FAST | MEDIUM | EXTENDED | CHANGED}
-- 整理数据文件的碎片
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
/* 杂项 */ ------------------
1. 可用反引号(`)为标识符(库名、表名、字段名、索引、别名)包裹,以避免与关键字重名!中文也可以作为标识符!
2. 每个库目录存在一个保存当前数据库的选项文件db.opt。
3. 注释:
单行注释 # 注释内容
多行注释 /* 注释内容 */
单行注释 -- 注释内容 (标准SQL注释风格,要求双破折号后加一空格符(空格、TAB、换行等))
4. 模式通配符:
_ 任意单个字符
% 任意多个字符,甚至包括零字符
单引号需要进行转义 \'
5. CMD命令行内的语句结束符可以为 ";", "\G", "\g",仅影响显示结果。其他地方还是用分号结束。delimiter 可修改当前对话的语句结束符。
6. SQL对大小写不敏感
7. 清除已有语句:\c5.5.8、常用的SQL
/*==============================================================*/
/* DBMS name: MySQL 5.0 */
/* Created on: 2017/3/5 10:29:05 */
/*==============================================================*/
drop table if exists Address;
drop table if exists ArticleComment;
drop table if exists ArticleType;
drop table if exists Articles;
drop table if exists DictSub;
drop table if exists DictTop;
drop table if exists OrderPdt;
drop table if exists Orders;
drop table if exists ProductComment;
drop table if exists Products;
drop table if exists Users;
/*==============================================================*/
/* Table: Address */
/*==============================================================*/
create table Address
(
`AddressId` int not null auto_increment comment '收货地址编号',
`UserId` int not null comment '用户编号',
`Province` varchar(50) not null comment '省',
`City` varchar(50) not null comment '市',
`County` varchar(50) not null comment '县/区',
`Street` varchar(300) not null comment '详细地址',
`RevName` varchar(30) not null comment '收货人姓名',
`PostCode` varchar(20) comment '邮政编码',
`Mobile` varchar(50) not null comment '手机',
`Phone` varchar(50) comment '电话',
`IsDefault` bool comment '是否为默认地址',
primary key (AddressId)
);
alter table Address comment '收货地址';
/*==============================================================*/
/* Table: ArticleComment */
/*==============================================================*/
create table ArticleComment
(
`ArticleCommentId` int not null auto_increment comment '文章评论编号',
`ArticleId` int not null comment '文章编号',
`UserId` int not null comment '用户编号',
`ArticleCommentContent` varchar(4000) not null comment '文章评论内容',
`ArticleCommentDate` timestamp default CURRENT_TIMESTAMP comment '文章评论时间',
`ArticleCommentState` int default 1 comment '状态',
`ArticleRemark` int comment '打分',
`ArticleCommentReserver1` varchar(4000) comment '备用1',
`ArticleCommentReserver2` varchar(4000) comment '备用2',
primary key (ArticleCommentId)
);
alter table ArticleComment comment '文章评论';
/*==============================================================*/
/* Table: ArticleType */
/*==============================================================*/
create table ArticleType
(
`ArticleTypeId` int not null auto_increment comment '文章栏目编号',
`ArticleTypeName` varchar(200) comment '文章栏目名称',
`ArticleTypeState` int default 1 comment '状态',
`ArticleTypeDesc` varchar(4000) comment '文章栏目描述',
`ArticleTypePicture` varchar(400) comment '文章栏目图片',
`ArticleTypeReserve1` varchar(4000) comment '备用1',
`ArticleTypeReserve2` varchar(4000) comment '备用2',
primary key (ArticleTypeId)
);
alter table ArticleType comment '文章栏目';
/*==============================================================*/
/* Table: Articles */
/*==============================================================*/
create table Articles
(
`ArticleId` int not null auto_increment comment '文章编号',
`ArticleTypeId` int not null comment '文章栏目编号',
`ArticleTitle` varchar(400) not null comment '文章标题',
`ArticleContent` text comment '文章内容',
`ArticleDate` timestamp default CURRENT_TIMESTAMP comment '文章发布时间',
`ArticleAuthor` varchar(200) comment '文章发布者',
`ArticleFileName` varchar(100) comment '静态文件名',
`ArticleThumbNail` varchar(200) comment '缩略图片',
`ArticleAddition` varchar(200) comment '附件名称',
`ArticleLevel` int comment '显示的优先级',
`ArticleIsAllowComment` integer default 1 comment '是否允许评论',
`ArticleState` int default 1 comment '状态',
`ArticleHotCount` int comment '点击次数',
`ArticleReserve1` varchar(4000) comment '备用1',
`ArticleReserve2` varchar(4000) comment '备用2',
`ArticleReserve3` numeric(8,0) comment '备用3',
primary key (ArticleId)
);
alter table Articles comment '文章';
/*==============================================================*/
/* Table: DictSub */
/*==============================================================*/
create table DictSub
(
`SubId` int not null auto_increment comment '子项编号',
`DictId` int not null comment '字典编号',
`SubName` varchar(200) not null comment '子项名称',
`SubDesc` varchar(4000) comment '子项描述',
`SubReserve1` varchar(4000) comment '保留备用1',
primary key (SubId)
);
alter table DictSub comment '字典子项';
/*==============================================================*/
/* Table: DictTop */
/*==============================================================*/
create table DictTop
(
`DictId` int not null auto_increment comment '字典编号',
`DictName` varchar(100) not null comment '字典名称',
`DictDesc` varchar(4000) comment '字典描述',
`DictReserve1` varchar(4000) comment '保留备用',
primary key (DictId)
);
alter table DictTop comment '字典';
/*==============================================================*/
/* Table: OrderPdt */
/*==============================================================*/
create table OrderPdt
(
`OrderPdtId` int not null auto_increment comment '订单商品编号',
`Id` int not null comment '编号',
`UserId` int not null comment '用户编号',
`OrderId` int comment '订单号',
`PdtAmount` int comment '订购数量',
`PdtPrice` decimal comment '单价',
`PdtReserve1` varchar(2000) comment '备用1',
`PdtReserve2` varchar(4000) comment '备用2',
primary key (OrderPdtId)
);
alter table OrderPdt comment '订单商品';
/*==============================================================*/
/* Table: Orders */
/*==============================================================*/
create table Orders
(
`OrderId` int not null auto_increment comment '订单号',
`AddressId` int not null comment '收货地址编号',
`OrderState` int default 1 comment '订单状态',
`ExpressNO` varchar(50) comment '快递编号',
`ExpressName` varchar(50) comment '快递名称',
`PayMoney` decimal comment '应支付',
`PayedMoney` decimal comment '已支付',
`SendInfo` varchar(300) comment '发货人信息',
`BuyDate` timestamp default CURRENT_TIMESTAMP comment '下单时间',
`PayDate` datetime comment '支付时间',
`SendDate` datetime comment '发货时间',
`ReceivDate` datetime comment '收货时间',
`OrderMessage` varchar(4000) comment '附言',
`UserId` integer comment '用户编号',
`OrderReserve1` varchar(4000) comment '备用1',
`OrderReserve2` varchar(4000) comment '备用2',
`OrderReserve3` decimal comment '备用3',
primary key (OrderId)
);
alter table Orders comment '订单';
/*==============================================================*/
/* Table: ProductComment */
/*==============================================================*/
create table ProductComment
(
`ProductCommentId` int not null auto_increment comment '商品评论编号',
`ProductId` int not null comment '商品编号',
`UserId` int not null comment '用户编号',
`ProductCommentContent` varchar(4000) comment '商品评论内容',
`ProductCommentDate` timestamp default CURRENT_TIMESTAMP comment '商品评论时间',
`ProductCommentState` int comment '状态',
`ProductCommentRemark` int comment '打分',
`ProductCommentReserve1` varchar(4000) comment '备用1',
`ProductCommentReserve2` varchar(4000) comment '备用2',
primary key (ProductCommentId)
);
alter table ProductComment comment '商品评论';
/*==============================================================*/
/* Table: Products */
/*==============================================================*/
create table Products
(
`Id` int not null auto_increment comment '编号',
`Name` varchar(200) not null comment '名称',
`SubIdColor` int not null comment '所属颜色',
`SubIdBrand` int not null comment '所属品牌',
`SubIdInlay` int not null comment '所属镶嵌',
`SubIdMoral` int not null comment '所属寓意',
`SubIdMaterial` int not null comment '所属种水',
`SubIdTopLevel` int not null comment '一级分类编号',
`MarketPrice` decimal comment '市场参考价',
`MyPrice` decimal not null comment '玉源直销价',
`Discount` decimal default 1 comment '折扣',
`Picture` varchar(200) comment '图片',
`Amount` int comment '库存量',
`Description` text comment '详细描述',
`State` int default 1 comment '状态',
`AddDate` timestamp default CURRENT_TIMESTAMP comment '上货日期',
`Hang` int comment '挂件',
`RawStone` int comment '赌石',
`Size` varchar(200) comment '尺寸',
`ExpressageName` varchar(100) comment '快递名称',
`Expressage` decimal comment '快递费',
`AllowComment` int default 1 comment '是否允许评论',
`Reserve1` varchar(4000) comment '保留备用1',
`Reserve2` varchar(4000) comment '保留备用2',
`Reserve3` decimal(0) comment '保留备用3',
primary key (Id)
);
alter table Products comment '商品';
/*==============================================================*/
/* Table: Users */
/*==============================================================*/
create table Users
(
`UserId` int not null auto_increment comment '用户编号',
`UserName` varchar(200) not null comment '用户名',
`Password` varchar(512) not null comment '密码',
`Email` varchar(100) not null comment '邮箱',
`Sex` varchar(10) comment '性别',
`State` int default 1 comment '状态',
`RightCode` int comment '权限状态',
`RegDate` timestamp default CURRENT_TIMESTAMP comment '注册时间',
`RegIP` varchar(200) comment '注册IP',
`LastLoginDate` datetime comment '最近登录时间',
`UserReserve1` varchar(4000) comment '保留备用1',
`UserReserve2` varchar(4000) comment '保留备用2',
`UserReserve3` varchar(4000) comment '保留备用3',
primary key (UserId)
);
alter table Users comment '用户';
alter table Address add constraint FK_AddressBelongUser foreign key (UserId)
references Users (UserId) on delete restrict on update restrict;
alter table ArticleComment add constraint FK_ArticleCommentForArticle foreign key (ArticleId)
references Articles (ArticleId) on delete restrict on update restrict;
alter table ArticleComment add constraint FK_ArticleCommentForUser foreign key (UserId)
references Users (UserId) on delete restrict on update restrict;
alter table Articles add constraint FK_ArticleBelongType foreign key (ArticleTypeId)
references ArticleType (ArticleTypeId) on delete restrict on update restrict;
alter table DictSub add constraint FK_BelongDict foreign key (DictId)
references DictTop (DictId) on delete cascade on update cascade;
alter table OrderPdt add constraint FK_BelongOrder foreign key (OrderId)
references Orders (OrderId) on delete cascade on update cascade;
alter table OrderPdt add constraint FK_CartForUser foreign key (UserId)
references Users (UserId) on delete restrict on update restrict;
alter table OrderPdt add constraint FK_OrderDepProduct foreign key (Id)
references Products (Id) on delete restrict on update restrict;
alter table Orders add constraint FK_OrderBelongAddress foreign key (AddressId)
references Address (AddressId) on delete restrict on update restrict;
alter table ProductComment add constraint FK_ProductCommentBelongUsers foreign key (UserId)
references Users (UserId) on delete restrict on update restrict;
alter table ProductComment add constraint FK_ProductCommentForProduct foreign key (ProductId)
references Products (Id) on delete restrict on update restrict;
alter table Products add constraint FK_BelongBrand foreign key (SubIdMaterial)
references DictSub (SubId) on delete restrict on update restrict;
alter table Products add constraint FK_BelongColor foreign key (SubIdBrand)
references DictSub (SubId) on delete restrict on update restrict;
alter table Products add constraint FK_BelongInlay foreign key (SubIdInlay)
references DictSub (SubId) on delete restrict on update restrict;
alter table Products add constraint FK_BelongMaterial foreign key (SubIdColor)
references DictSub (SubId) on delete restrict on update restrict;
alter table Products add constraint FK_BelongMoral foreign key (SubIdTopLevel)
references DictSub (SubId) on delete restrict on update restrict;
alter table Products add constraint FK_BelongTopLevel foreign key (SubIdMoral)
references DictSub (SubId) on delete restrict on update restrict;六、下载程序、帮助、视频
文档中没有您可以查帮助:

图7:1 小時學會 MySQL 資料庫

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 mysql:簡單的概念,用於輕鬆學習
Apr 10, 2025 am 09:29 AM
mysql:簡單的概念,用於輕鬆學習
Apr 10, 2025 am 09:29 AM
MySQL是一個開源的關係型數據庫管理系統。 1)創建數據庫和表:使用CREATEDATABASE和CREATETABLE命令。 2)基本操作:INSERT、UPDATE、DELETE和SELECT。 3)高級操作:JOIN、子查詢和事務處理。 4)調試技巧:檢查語法、數據類型和權限。 5)優化建議:使用索引、避免SELECT*和使用事務。
 phpmyadmin怎麼打開
Apr 10, 2025 pm 10:51 PM
phpmyadmin怎麼打開
Apr 10, 2025 pm 10:51 PM
可以通過以下步驟打開 phpMyAdmin:1. 登錄網站控制面板;2. 找到並點擊 phpMyAdmin 圖標;3. 輸入 MySQL 憑據;4. 點擊 "登錄"。
 MySQL:世界上最受歡迎的數據庫的簡介
Apr 12, 2025 am 12:18 AM
MySQL:世界上最受歡迎的數據庫的簡介
Apr 12, 2025 am 12:18 AM
MySQL是一種開源的關係型數據庫管理系統,主要用於快速、可靠地存儲和檢索數據。其工作原理包括客戶端請求、查詢解析、執行查詢和返回結果。使用示例包括創建表、插入和查詢數據,以及高級功能如JOIN操作。常見錯誤涉及SQL語法、數據類型和權限問題,優化建議包括使用索引、優化查詢和分錶分區。
 為什麼要使用mysql?利益和優勢
Apr 12, 2025 am 12:17 AM
為什麼要使用mysql?利益和優勢
Apr 12, 2025 am 12:17 AM
選擇MySQL的原因是其性能、可靠性、易用性和社區支持。 1.MySQL提供高效的數據存儲和檢索功能,支持多種數據類型和高級查詢操作。 2.採用客戶端-服務器架構和多種存儲引擎,支持事務和查詢優化。 3.易於使用,支持多種操作系統和編程語言。 4.擁有強大的社區支持,提供豐富的資源和解決方案。
 redis怎麼使用單線程
Apr 10, 2025 pm 07:12 PM
redis怎麼使用單線程
Apr 10, 2025 pm 07:12 PM
Redis 使用單線程架構,以提供高性能、簡單性和一致性。它利用 I/O 多路復用、事件循環、非阻塞 I/O 和共享內存來提高並發性,但同時存在並發性受限、單點故障和不適合寫密集型工作負載的局限性。
 MySQL和SQL:開發人員的基本技能
Apr 10, 2025 am 09:30 AM
MySQL和SQL:開發人員的基本技能
Apr 10, 2025 am 09:30 AM
MySQL和SQL是開發者必備技能。 1.MySQL是開源的關係型數據庫管理系統,SQL是用於管理和操作數據庫的標準語言。 2.MySQL通過高效的數據存儲和檢索功能支持多種存儲引擎,SQL通過簡單語句完成複雜數據操作。 3.使用示例包括基本查詢和高級查詢,如按條件過濾和排序。 4.常見錯誤包括語法錯誤和性能問題,可通過檢查SQL語句和使用EXPLAIN命令優化。 5.性能優化技巧包括使用索引、避免全表掃描、優化JOIN操作和提升代碼可讀性。
 MySQL的位置:數據庫和編程
Apr 13, 2025 am 12:18 AM
MySQL的位置:數據庫和編程
Apr 13, 2025 am 12:18 AM
MySQL在數據庫和編程中的地位非常重要,它是一個開源的關係型數據庫管理系統,廣泛應用於各種應用場景。 1)MySQL提供高效的數據存儲、組織和檢索功能,支持Web、移動和企業級系統。 2)它使用客戶端-服務器架構,支持多種存儲引擎和索引優化。 3)基本用法包括創建表和插入數據,高級用法涉及多表JOIN和復雜查詢。 4)常見問題如SQL語法錯誤和性能問題可以通過EXPLAIN命令和慢查詢日誌調試。 5)性能優化方法包括合理使用索引、優化查詢和使用緩存,最佳實踐包括使用事務和PreparedStatemen
 SQL刪除行後如何恢復數據
Apr 09, 2025 pm 12:21 PM
SQL刪除行後如何恢復數據
Apr 09, 2025 pm 12:21 PM
直接從數據庫中恢復被刪除的行通常是不可能的,除非有備份或事務回滾機制。關鍵點:事務回滾:在事務未提交前執行ROLLBACK可恢復數據。備份:定期備份數據庫可用於快速恢復數據。數據庫快照:可創建數據庫只讀副本,在數據誤刪後恢復數據。慎用DELETE語句:仔細檢查條件,避免誤刪數據。使用WHERE子句:明確指定要刪除的數據。使用測試環境:在執行DELETE操作前進行測試。