

Javascript-作用域及作用域鏈及閉包的詳解(圖文)

本文主要介紹了圖解Javascript——作用域、作用域鏈、閉包等知識。具有很好的參考價值。下面跟著小編一起來看吧
什麼是作用域?
作用域是一種規則,在程式碼編譯階段就確定了,規定了變數與函數的可被存取的範圍。全域變數擁有全域作用域,局部變數則擁有局部作用域。 js是一種沒有區塊級作用域的語言(包括if、for等語句的花括號程式碼區塊或單獨的花括號程式碼區塊都不能形成一個局部作用域),所以js的局部作用域的形成有且只有函數的花括號內定義的程式碼區塊形成的,既函數作用域。
什麼是作用域鏈?
作用域鍊是作用域規則的實現,透過作用域鏈的實現,變數在它的作用域內可被訪問,函數在它的作用域內可被呼叫。
作用域鍊是一個只能單向存取的鍊錶,這個鍊錶上的每個節點就是執行上下文的變數物件(程式碼執行時就是活動物件),單向鍊錶的頭部(可被第一個存取的節點)總是目前正在被呼叫執行的函數的變數物件(活動物件),尾部始終是全域活動物件。
作用域鏈的形成?
我們從一段程式碼的執行來看作用域鏈的形成過程。
function fun01 () {
console.log('i am fun01...');
fun02();
}
function fun02 () {
console.log('i am fun02...');
}
fun01();
資料存取流程
#如上圖,當程式存取一個變數時,依照作用域鏈的單向存取特性,先在頭節點的AO中查找,沒有則到下一節點的AO查找,最多查找到尾節點(global AO)。在這個過程中找到了就找到了,沒找到就報錯undefined。
延長作用域鏈
從上面作用域鏈的形成可以看出鏈上的每個節點是在函數被呼叫執行是向鏈頭unshift進目前函數的AO,而節點的形成還有一種方式就是“延長作用域鏈”,既在作用域鏈的頭部插入一個我們想要的物件作用域。延長作用域鏈有兩種方式:
1.with語句
#function fun01 () {
with (document) {
console.log('I am fun01 and I am in document scope...')
}
}
fun01();
##2.try-catch語句的catch區塊
function fun01 () {
try {
console.log('Some exceptions will happen...')
} catch (e) {
console.log(e)
}
}
fun01();
性能優化小建議。
由作用域鏈引發的關於性能優化的一點不成熟的小建議
#1.減少變數的作用域鏈的訪問節點
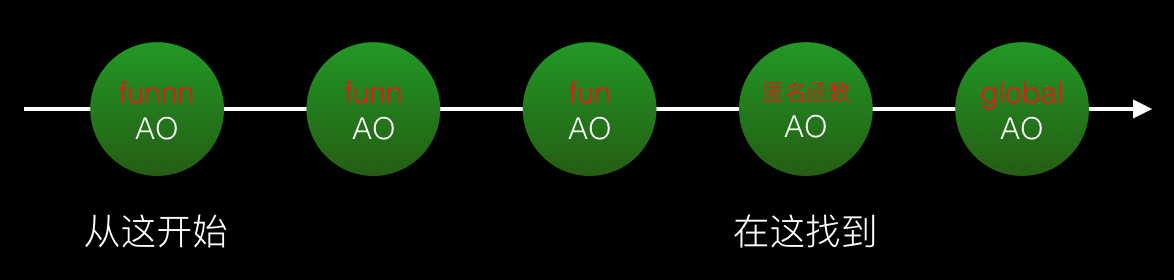
這裡我們自訂一個名次叫做“查找距離”,表示程式存取到一個非undefined變數在作用域鏈中經過的節點數。因為如果在目前節點沒有找到變量,就跳到下一個節點查找,還要進行判斷下一個節點中是否存在被查找變數。 「尋找距離」越長,要做的「跳」動作和「判斷」動作就越多,資源開銷就越大,進而影響表現。這種效能帶來的差距可能少數的幾次變數查找操作不會帶來太多效能問題,但如果是多次進行變數查找,效能對比則比較明顯了。(function(){
console.time()
var find = 1 //这个find变量需要在4个作用域链节点进行查找
function fun () {
function funn () {
var funnv = 1;
var funnvv = 2;
function funnn () {
var i = 0
while(i <= 100000000){
if(find){
i++
}
}
}
funnn()
}
funn()
}
fun()
console.timeEnd()
})()
#
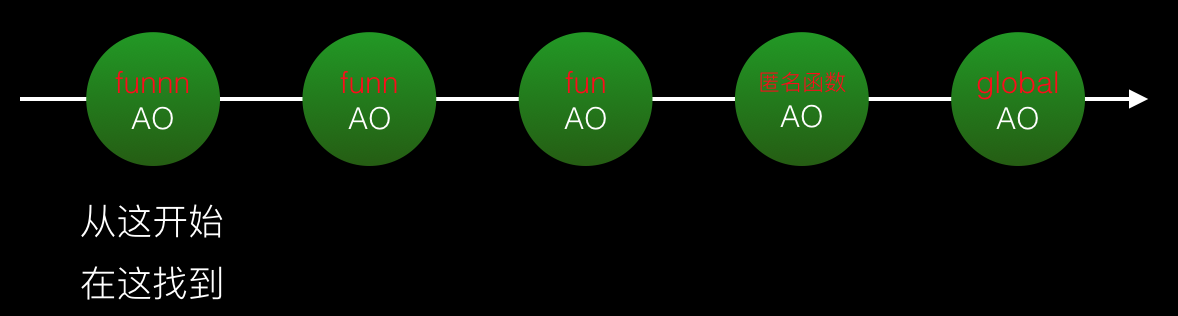
(function(){
console.time()
function fun () {
function funn () {
var funnv = 1;
var funnvv = 2;
function funnn () {
var i = 0
var find = 1 //这个find变量只在当前节点进行查找
while(i <= 100000000){
if(find){
i++
}
}
}
funnn()
}
funn()
}
fun()
console.timeEnd()
})()
2.避免作用域鏈內節點AO上過多的變數定義
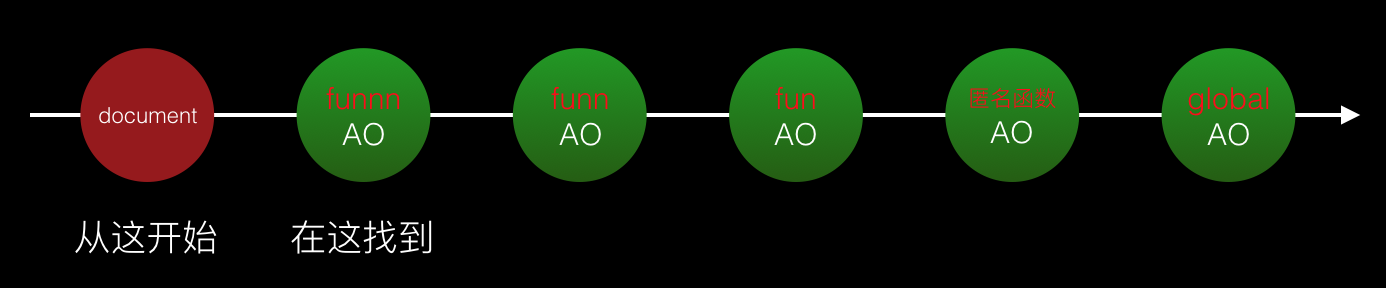
過多的變數定義造成效能問題的原因主要是查找變數過程中的「判斷」操作開銷較大。我們使用with來進行效能比較。(function(){
console.time()
function fun () {
function funn () {
var funnv = 1;
var funnvv = 2;
function funnn () {
var i = 0
var find = 10
with (document) {
while(i <= 1000000){
if(find){
i++
}
}
}
}
funnn()
}
funn()
}
fun()
console.timeEnd()
})()
在mac pro的chrome浏览器下做实验,进行100万次查找运算,借助with使用document进行的延长作用域链,因为document下的变量属性比较多,可以测试在多变量作用域链节点下进行查找的性能差异。
实验结果:5次平均耗时558.802ms,而如果删掉with和document,5次平均耗时0.956ms。
当然,这两个实验是在我们假设的极端环境下进行的,结果仅供参考!
关于闭包
1.什么是闭包?
函数对象可以通过作用域链相互关联起来,函数体内的数据(变量和函数声明)都可以保存在函数作用域内,这种特性在计算机科学文献中被称为“闭包”。既函数体内的数据被隐藏于作用于链内,看起来像是函数将数据“包裹”了起来。从技术角度来说,js的函数都是闭包:函数都是对象,都关联到作用域链,函数内数据都被保存在函数作用域内。
2.闭包的几种实现方式
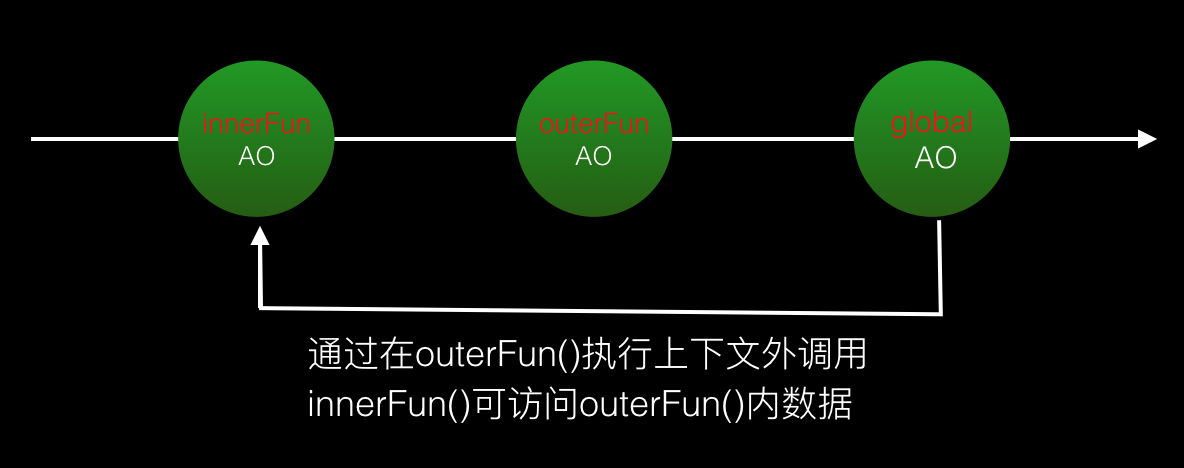
实现方式就是函数A在函数B的内部进行定义了,并且当函数A在执行时,访问了函数B内部的变量对象,那么B就是一个闭包。如下:


如上两图所示,是在chrome浏览器下查看闭包的方法。两种方式的共同点是都有一个外部函数outerFun(),都在外部函数内定义了内部函数innerFun(),内部函数都访问了外部函数的数据。不同的是,第一种方式的innerFun()是在outerFun()内被调用的,既声明和被调用均在同一个执行上下文内。而第二种方式的innerFun()则是在outerFun()外被调用的,既声明和被调用不在同一个执行上下文。第二种方式恰好是js使用闭包常用的特性所在:通过闭包的这种特性,可以在其他执行上下文内访问函数内部数据。
我们更常用的一种方式则是这样的:
//闭包实例
function outerFun () {
var outerV1 = 10
function outerF1 () {
console.log('I am outerF1...')
}
function innerFun () {
var innerV1 = outerV1
outerF1()
}
return innerFun //return回innerFun()内部函数
}
var fn = outerFun() //接到return回的innerFun()函数
fn() //执行接到的内部函数innerFun()此时它的作用域链是这样的:
3.闭包的好处及使用场景
js的垃圾回收机制可以粗略的概括为:如果当前执行上下文执行完毕,且上下文内的数据没有其他引用,则执行上下文pop出call stack,其内数据等待被垃圾回收。而当我们在其他执行上下文通过闭包对执行完的上下文内数据仍然进行引用时,那么被引用的数据则不会被垃圾回收。就像上面代码中的outerV1,放我们在全局上下文通过调用innerFun()仍然访问引用outerV1时,那么outerFun执行完毕后,outerV1也不会被垃圾回收,而是保存在内存中。另外,outerV1看起来像不像一个outerFun的私有内部变量呢?除了innerFun()外,我们无法随意访问outerV1。所以,综上所述,这样闭包的使用情景可以总结为:
(1)进行变量持久化。
(2)使函数对象内有更好的封装性,内部数据私有化。
进行变量持久化方面举个栗子:
我们假设一个需求时写一个函数进行类似id自增或者计算函数被调用的功能,普通青年这样写:
var count = 0
function countFun () {
return count++
}这样写固然实现了功能,但是count被暴露在外,可能被其他代码篡改。这个时候闭包青年就会这样写:
function countFun () {
var count = 0
return function(){
return count++
}
}
var a = countFun()
a()这样count就不会被不小心篡改了,函数调用一次就count加一次1。而如果结合“函数每次被调用都会创建一个新的执行上下文”,这种count的安全性还有如下体现:
function countFun () {
var count = 0
return {
count: function () {
count++
},
reset: function () {
count = 0
},
printCount: function () {
console.log(count)
}
}
}
var a = countFun()
var b = countFun()
a.count()
a.count()
b.count()
b.reset()
a.printCount() //打印:2 因为a.count()被调用了两次
b.printCount() //打印出:0 因为调用了b.reset()以上便是闭包提供的变量持久化和封装性的体现。
4.闭包的注意事项
由於閉包中的變數不會像其他正常變數那種被垃圾回收,而是一直存在記憶體中,所以大量使用閉包可能會造成效能問題。
以上是Javascript-作用域及作用域鏈及閉包的詳解(圖文)的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 c語言中typedef struct的用法
May 09, 2024 am 10:15 AM
c語言中typedef struct的用法
May 09, 2024 am 10:15 AM
typedef struct 在 C 語言中用於建立結構體類型別名,簡化結構體使用。它透過指定結構體別名將一個新的資料類型作為現有結構體的別名。優點包括增強可讀性、程式碼重複使用和類型檢查。注意:在使用別名前必須定義結構體,別名在程式中必須唯一且僅在其宣告的作用域內有效。
 java中的variable expected怎麼解決
May 07, 2024 am 02:48 AM
java中的variable expected怎麼解決
May 07, 2024 am 02:48 AM
Java 中的變數期望值異常可以透過以下方法解決:初始化變數;使用預設值;使用 null 值;使用檢查和賦值;了解局部變數的作用域。
 js中閉包的優缺點
May 10, 2024 am 04:39 AM
js中閉包的優缺點
May 10, 2024 am 04:39 AM
JavaScript 閉包的優點包括維持變數作用域、實作模組化程式碼、延遲執行和事件處理;缺點包括記憶體洩漏、增加了複雜性、效能開銷和作用域鏈影響。
 c++中的include什麼意思
May 09, 2024 am 01:45 AM
c++中的include什麼意思
May 09, 2024 am 01:45 AM
C++ 中的 #include 預處理器指令將外部來源檔案的內容插入到目前原始檔案中,以複製其內容到目前原始檔案的相應位置。主要用於包含頭文件,這些頭文件包含程式碼中所需的聲明,例如 #include <iostream> 是包含標準輸入/輸出函數。
 C++ 智慧指標:全面剖析其生命週期
May 09, 2024 am 11:06 AM
C++ 智慧指標:全面剖析其生命週期
May 09, 2024 am 11:06 AM
C++智慧指標的生命週期:建立:分配記憶體時建立智慧指標。所有權轉移:透過移動操作轉移所有權。釋放:智慧指標離開作用域或被明確釋放時釋放記憶體。物件銷毀:所指向物件被銷毀時,智慧型指標成為無效指標。
 C++ Lambda 表達式如何實作閉包?
Jun 01, 2024 pm 05:50 PM
C++ Lambda 表達式如何實作閉包?
Jun 01, 2024 pm 05:50 PM
C++Lambda表達式支援閉包,即保存函數作用域變數並供函數存取。語法為[capture-list](parameters)->return-type{function-body}。 capture-list定義要捕獲的變量,可以使用[=]按值捕獲所有局部變量,[&]按引用捕獲所有局部變量,或[variable1,variable2,...]捕獲特定變量。 Lambda表達式只能存取捕獲的變量,但無法修改原始值。
 c++中函數的定義和呼叫可以巢狀嗎
May 06, 2024 pm 06:36 PM
c++中函數的定義和呼叫可以巢狀嗎
May 06, 2024 pm 06:36 PM
可以。 C++ 允許函數巢狀定義和呼叫。外部函數可定義內建函數,內部函數可在作用域內直接呼叫。巢狀函數增強了封裝性、可重複用性和作用域控制。但內部函數無法直接存取外部函數的局部變量,且傳回值類型需與外部函數宣告一致,內部函數不能自遞歸。
 vue中let和var的區別
May 08, 2024 pm 04:21 PM
vue中let和var的區別
May 08, 2024 pm 04:21 PM
在 Vue 中,let 和 var 宣告變數時在作用域上存在差異:作用域:var 具有全域作用域,let 具有區塊級作用域。區塊級作用域:var 不會建立區塊級作用域,let 建立區塊級作用域。重新宣告:var 允許在同一作用域內重新宣告變數,let 不允許。
