
本文主要介紹了C#線程同步的相關知識。具有很好的參考價值,下面跟著小編一起來看下吧
多線程內容大致分兩部分,其一是異步操作,可通過專用,線程池,Task,Parallel,PLINQ等,而這裡又涉及工作線程與IO線程;其二是線程同步問題,鄙人現在學習與探究的是線程同步問題。
透過學習《CLR via C#》裡面的內容,對線程同步形成了脈絡較清晰的體系結構,在多線程中實現線程同步的是線程同步構造,這個構造分兩大類,一個是基元構造,一個是混合構造。所謂基元則是在程式碼中使用最簡單的構造。基原構造又分成兩類,一個是使用者模式,另一個是核心模式。而混合建構則是在內部會使用基元建構的使用者模式和核心模式,使用它的模式會有一定的策略,因為使用者模式和核心模式各有利弊,混合建構則是為了平衡兩者的利與弊而設計出來。以下則列舉整個執行緒同步體系結構
基元
1.1 使用者模式
1.1.1 volatile
1.1.2 Interlock
1.2 核心模式
## 1.2.1 WaitHandle 1.2.2 ManualResetEvent與AutoResetEvent 1.2.3 #. 4 Mutex混合
2.1 各種Slim
2.2 Monitor## 2.1 各種Slim
2.2 Monitor
## 2.1 各種Slim 2.2 Monitor# 2. ReaderWriterLock 2.5 Barier(少用)
2.6 CoutdownEvent(少用)
先從線程同步問題的原因說起,當記憶體中有一個整形的
變數A,裡面存放的值是2,當執行緒1執行的時候它會把A的值從記憶體中取出存放到CPU的暫存器中,並把A賦值為3,此時剛好執行緒1的時間片結束;接著CPU把時間片分給線程2,線程2同樣把A從內存中的值取出來放到內存中,但是由於線程1並沒有把變量A的新值3放回內存,故線程2讀到的仍然是舊的值(也就是髒數據)2,然後線程2要是需要對A值進行一些判斷之類的就會出現一些非預期的結果了。
而針對上面這種對資源的共享問題處理,往往會使用各種方法。以下則逐一介紹
先說說基元構造中的使用者模式,凡是使用者模式的優點是它的執行相對較快,因為它是透過一系列CPU指令來協調,它造成的阻塞只是極短時間的阻塞,對作業系統而言這個執行緒是一直在運行,從未被阻塞。缺點就是只有系統核心才能停止這樣的一個執行緒運行。另一方面就是由於執行緒在自旋而非阻塞,那麼它還會佔用這CPU的時間,造成CPU時間的浪費。
首先是基元用戶模式構造中的volatile構造,這個構造網上很多說法是讓CPU對指定字段(Field,也就是變量)的讀都是從內存讀,每次寫都是往記憶體寫。然而它和編譯器的程式碼最佳化有關係。先看看如下程式碼
public class StrageClass
{
vo int mFlag = 0;
int mValue = 0;
public void Thread1()
{
mValue = 5;
mFlag = 1;
}
public void Thread2()
{
if (mFlag == 1)
Console.WriteLine(mValue);
}
}在懂得多執行緒同步問題的同學都會知道如果用兩個執行緒分別去執行上面兩個方法時,得到的結果有兩個:
1.不輸出任何東西;2.輸出5。但在CSC編譯器編譯成IL語言或JIT編譯成機器語言的過程中,會進行程式碼最佳化,在方法Thread1中,編譯器會覺得給兩個欄位賦值會沒什麼所謂,它只會站在單一執行緒執行的角度來看,完全不會顧及多執行緒的問題,因此它有可能會把兩行程式碼的執行順序調亂,導致先給mFlag賦值為1,再給mValue賦值為5,這就導致了第三種結果,輸出0。可惜這種結果我一直無法測試出來。
解決這個現象的就是volatile構造,使用了這種構造的效果是,凡是對使用了此構造的字段進行讀取操作時,該操作都保證在原有代碼順序下會在最先執行;或者是凡是對使用了此構造的欄位進行寫入操作時,該操作都保證在原有程式碼順序下會在最後執行。
實現了volatile的建構現在來說有三個,其一是Thread的兩個
靜態###方法VolatileRead和VolatileWrite,在MSND上的解析如下#######Thread. VolatileRead 讀取欄位值。 無論處理器的數目或處理器快取的狀態如何,該值都是由電腦的任何處理器寫入的最新值。 ######Thread.VolatileWrite 立即向欄位寫入一個值,以使該值對電腦中的所有處理器都可見。 ###在多处理器系统上, VolatileRead 获得由任何处理器写入的内存位置的最新值。 这可能需要刷新处理器缓存;VolatileWrite 确保写入内存位置的值立即可见的所有处理器。 这可能需要刷新处理器缓存。
即使在单处理器系统上, VolatileRead 和 VolatileWrite 确保值为读取或写入内存,并不缓存 (例如,在处理器寄存器中)。 因此,您可以使用它们可以由另一个线程,或通过硬件更新的字段对访问进行同步。
从上面的文字看不出他和代码优化有任何关联,那接着往下看。
volatile关键字则是volatile构造的另外一种实现方式,它是VolatileRead和VolatileWrite的简化版,使用 volatile 修饰符对字段可以保证对该字段的所有访问都使用 VolatileRead 或 VolatileWrite。MSDN中对volatile关键字的说明是
volatile 关键字指示一个字段可以由多个同时执行的线程修改。 声明为 volatile 的字段不受编译器优化(假定由单个线程访问)的限制。 这样可以确保该字段在任何时间呈现的都是最新的值。
从这里可以看出跟代码优化有关系了。而纵观上面的介绍得出两个结论:
1.使用了volatile构造的字段读写都是直接对内存操作,不涉及CPU寄存器,使得所有线程对它的读写都是同步,不存在脏读了。读操作是原子的,写操作也是原子的。
2.使用了volatile构造修饰(或访问)字段,它会严格按照代码编写的顺序执行,读操作将会在最早执行,写操作将会最迟执行。
最后一个volatile构造是在.NET Framework中新增的,里面包含的方法都是Read和Write,它实际上就相当于Thread的VolatileRead 和VolatileWrite 。这需要拿源码来说明了,随便拿一个Volatile的Read方法来看
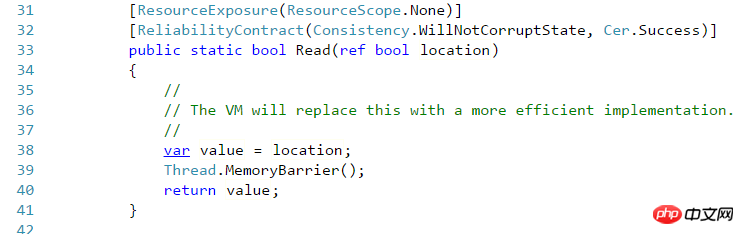
而再看看Thraed的VolatileRead方法

另一个用户模式构造是Interlocked,这个构造是保证读和写都是在原子操作里面,这是与上面volatile最大的区别,volatile只能确保单纯的读或者单纯的写。
为何Interlocked是这样,看一下Interlocaked的方法就知道了
Add(ref int,int)// 调用ExternAdd 外部方法 CompareExchange(ref Int32,Int32,Int32)//1与3是否相等,相等则替换2,返回1的原始值 Decrement(ref Int32)//递减并返回 调用add Exchange(ref Int32,Int32)//将2设置到1并返回 Increment(ref Int32)//自增 调用add
就随便拿其中一个方法Add(ref int,int)来说(Increment和Decrement这两个方法实际上内部调用了Add方法),它会先读到第一个参数的值,在与第二个参数求和后,把结果写到给第一参数中。首先这整个过程是一个原子操作,在这个操作里面既包含了读,也包含了写。至于如何保证这个操作的原子性,估计需要查看Rotor源码才行。在代码优化方面来说,它确保了所有写操作都在Interlocked之前去执行,这保证了Interlocked里面用到的值是最新的;而任何变量的读取都在Interlocked之后读取,这保证了后面用到的值都是最新更改过的。
CompareExchange方法相当重要,虽然Interlocked提供的方法甚少,但基于这个可以扩展出其他更多方法,下面就是个例子,求出两个值的最大值,直接抄了Jeffrey的源码

查看上面代码,在进入循环之前先声明每次循环开始时target的值,在求出最值之后,核对一下target的值是否有变化,如果有变化则需要再记录新值,按照新值来再求一次最值,直到target不变为止,这就满足了Interlocked中所说的,写都在Interlocked之前发生,Interlocked往后就能读到最新的值。
基元内核模式
核心模式則是靠作業系統的核心物件來處理執行緒的同步問題。先說其弊端,它的速度會相對慢。原因有兩個,其一由於它是由作業系統核心物件來實現的,需要作業系統內部去協調,另外一個原因是核心對像都是一些非託管對象,在了解了AppDo# main之後就會知道,訪問的物件不在當前AppDomain中的要么就進行按值封送,要么就進行按引用封送。經過觀察這部分的非託管資源是按引用封送,這就會有效能影響。綜合上面兩方面的兩點得出內核模式的弊端。但是他也是有利的方面:1.線程在等待資源的時候不會"自旋"而是阻塞,這個節省了CPU時間,並且這個阻塞可以設定一個超時值。 2.可以實現Window執行緒和CLR執行緒的同步,也可同步不同行程中的執行緒(前者未體驗到,而對於後者則知道semaphores中有邊界值資源)。 3.可應用安全性設置,為經授權帳戶禁止存取(這個不知道是咋回事)。
核心模式的所有物件的基底類別是WaitHandle。核心模式的所有類別層次如下
WaitHandle
EventWaitHandle
#AutoResetEvent
#ManualResetEvent
#Semaphore
Mutex
WaitHandle繼承MarshalByRefObject,這就是依照參考封送了非託管物件。 WaitHandle裡面主要是各種Wait方法,呼叫了Wait方法在沒有收到訊號之前會被阻塞。 WaitOne則是等待一個訊號,WaitAny(WaitHandle[] waitHandles)則是收到任何一個waitHandles的訊號,WaitAll(WaitHandle[] waitHandles)則是等待所有waitHandles的訊號。這些方法都有一個版本允許設定一個超時時間。其他的核心模式構造都有類似的Wait方法。
EventWaitHandle的內部維護一個布林值,而Wait方法會在這個布林值為false時執行緒就會被阻塞,直到該布林值為true時執行緒才被釋放。操縱這個布林值的方法有Set()和Reset(),前者是把布林值設為true;後者則設成false。這相當於一個開關,呼叫了Reset之後執行緒執行到Wait就暫停了,直到Set才恢復。它有兩個子類,使用的方式類似,差異在於AutoResetEvent呼叫Set之後自動呼叫Reset,使得開關馬上恢復關閉狀態;而ManualResetEvent就需要手動呼叫Set讓開關關閉。這樣就達到一個效果一般情況下AutoResetEvent每次釋放的時候能讓一條線程通過;而ManualResetEvent在手動調用Reset之前有可能會讓多條線程通過。
Semaphore的內部是維護一個整形,當構造一個Semaphore物件時會指定最大的信號量與初始信號量值,每當調用一次WaitOne,信號量就會加1,當加到最大值時,線程就會被阻塞,當調用Release的時候就會釋放一個或多個信號量,此時被阻塞掉的一個或多個線程就會被釋放。這個就符合生產者與消費者問題了,當生產者不斷往產品隊列中加入產品時,他就會WaitOne,當隊列滿了,就相當於信號量滿了,生成者就會被阻塞,當消費者消費掉一個商品時,就會Release釋放掉產品隊列中的一個空間,此時因沒有空間存放產品的生產者又可以開始工作往產品隊列中存放產品了。
Mutex的內部與規則相對前面兩者稍微複雜一點,先說與前面相似的地方就是同樣都會通過WaitOne來阻塞當前線程,透過ReleastMutex來釋放對線程的阻塞。差別在於WaitOne的允許第一個呼叫的線程通過,其餘後面的線程調用到WaitOne就會被阻塞,通過了WaitOne的線程可以重複調用WaitOne多次,但是必須調用同樣次數的ReleaseMutex來釋放,否則會因為次數不對等導致別的執行緒一直處於阻塞的狀態。相較於之前的幾個構造,這個構造會有執行緒所有權與遞歸這兩個概念,這個是單純靠前面的構造都無法實現的,額外封裝除外。
混合建構
#上面的基元建構是用了最簡單的實作方式,使用者模式有使用者模式的快,但是它會帶來CPU時間的浪費;核心模式解決了這個問題,但是會帶來效能上的損失,各有利弊,而混合構造則是集合了兩者的利,它會在內部通過一定策略適當的時機使用用戶模式,再另一種情況下又會使用內核模式。但是這些層層判斷帶來的是記憶體上的開銷。在多執行緒同步中沒有完美的構造,各個構造都有利弊,存在即有意義,結合具體的應用場景就會有最優的構造可供使用。只是在於我們能否按照具體的場景來權衡利弊而已。
各種Slim後綴的類,在System.Threading命名空間中,可以看到若干個以Slim後綴結尾的類別:ManualResetEventSlim,SemaphoreSlim,ReaderWriterLockSlim。除了最後一個,其餘兩個都是在基元內核模式中有一樣的構造,但是這三個類別都是原有構造的簡化版,尤其是前兩個,使用方式跟原有的一樣,但是盡量避免使用作業系統的內核對象,而達到了輕量級的效果。例如在SemaphoreSlim中使用了內核構造ManualResetEvent,但是這個構造是透過延遲初始化,沒達到非不得已時都不使用。至於ReaderWriterLockSlim則在後面再介紹。
Monitor與lock,lock關鍵字可謂是最廣為人知的一種實現多執行緒同步的手段,那麼下面則又從一段程式碼說起

這個方法相當簡單且無實際意義,它只是為了看編譯器把這段程式碼編譯成什麼樣子,透過查看IL如下

留意到IL程式碼中出現了try…finally語句區塊、Monitor.Enter與Monotor.Exit方法。然後把程式碼改一下再編譯看看IL

IL程式碼
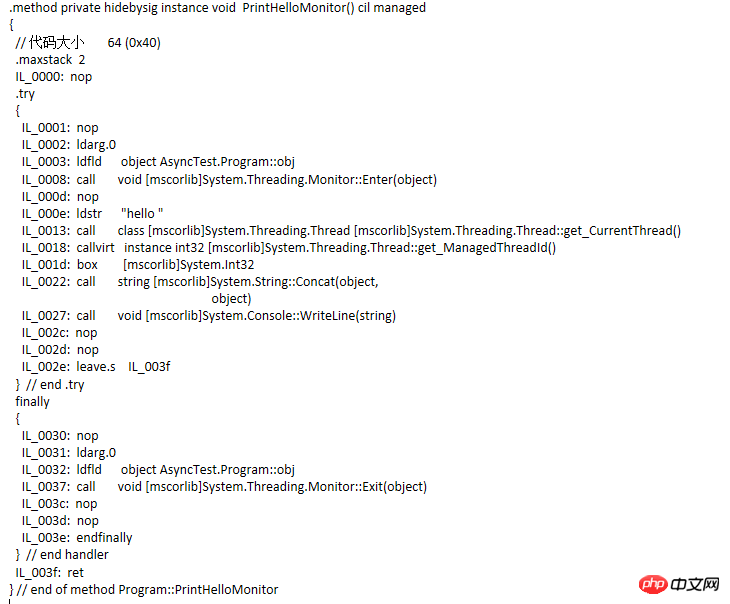

索引。這個索引指向一個同步區塊陣列的元素,Monitor對執行緒加鎖就是靠這個同步區塊。根據Jeffrey(CLR via C#的作者)的說法同步區塊中有三個字段,所有權的線程Id,等待線程的數量,遞歸的次數。然而我透過另一批文章了解到線程同步塊的成員並非單純這幾個,有興趣的同學可以去閱讀《揭示同步塊索引》的文章,有兩篇。 當Monitor需要為某個物件obj加鎖時,它會檢查obj的同步塊索引有否為數組的某個索引,如果是-1的,則從數組中找出一個空閒的同步塊與之關聯,同時同步區塊的所有權執行緒Id就記錄下目前執行緒的Id;當再次有執行緒呼叫Monitor的時候就會檢查同步區塊的所有權Id和目前執行緒Id是否對應上,能對應上的就讓其通過,在遞歸次數上加1,如果對應不上的就把該線程扔到一個就緒隊列(這個隊列實際上也是存在同步塊裡面)中,並將其阻塞;這個同步塊會在調用Exit的時候檢查遞歸次數確保遞歸完了就清除所有權執行緒Id。透過等待執行緒數量得知是否有執行緒在等待,如果有則從等待佇列中取出執行緒並釋放,否則就解除與同步區塊的關聯,讓同步區塊等待被下個被加鎖的物件使用。
Monitor中還有一對方法Wait與Pulse。前者可以使得獲得到鎖的線程短暫地將鎖釋放,而當前線程就會被阻塞而放入等待隊列中。直到其他執行緒呼叫了Pulse方法,才會從等待佇列中把執行緒放到就緒佇列中,等待下次鎖被釋放時,才有機會被再次取得鎖,具體能否取得就要看等待佇列中的情況了。 ReaderWriterLock讀寫鎖,傳統的lock關鍵字(即等價於Monitor的Enter和Exit),他對共享資源的鎖是全互斥鎖,一經加鎖的資源其他資源完全不能訪問。而ReaderWriterLock对互斥资源的加的锁分读锁与写锁,类似于数据库中提到的共享锁和排他锁。大致情况是加了读锁的资源允许多个线程对其访问,而加了写锁的资源只有一个线程可以对其访问。两种加了不同缩的线程都不能同时访问资源,而严格来说,加了读锁的线程只要在同一个队列中的都能访问资源,而不同队列的则不能访问;加了写锁的资源只能在一个队列中,而写锁队列中只有一个线程能访问资源。区分读锁的线程是否在于统一个队列中的判断标准是,本次加读锁的线程与上次加读锁的线程这个时间段中,有否别的线程加了写锁,没没别的线程加写锁,则这两个线程都在同一个读锁队列中。
ReaderWriterLockSlim和ReaderWriterLock类似,是后者的升级版,出现在.NET Framework3.5,据说是优化了递归和简化了操作。在此递归策略我尚未深究过。目前大概列举一下它们通常用的方法
ReaderWriterLock常用的方法
Acqurie或Release ReaderLock或WriteLock 的排列组合
UpGradeToWriteLock/DownGradeFromWriteLock 用于在读锁中升级到写锁。当然在这个升级的过程中也涉及到线程从读锁队列切换到写锁队列中,因此需要等待。
ReleaseLock/RestoreLock 释放所有锁和恢复锁状态
ReaderWriterLock实现IDispose接口,其方法则是以下模式
TryEnter/Enter/Exit ReadLock/WriteLock/UpGradeableReadLock
CoutdownEvent比较少用的混合构造,这个跟Semaphore相反,体现在Semaphore是在内部计数(也就是信号量)达到最大值的时候让线程阻塞,而CountdownEvent是在内部计数达到0的时候才让线程阻塞。其方法有
AddCount //计数递增; Signal //计数递减; Reset //计数重设为指定或初始; Wait //当且仅当计数为0才不阻塞,否则就阻塞。
Barrier也是一个比较少用的混合构造,用于处理多线程在分步骤的操作中协作问题。它内部维护着一个计数,该计数代表这次协作的参与者数量,当不同的线程调用SignalAndWait的时候会给这个计数加1并且把调用的线程阻塞,直到计数达到最大值的时候,才会释放所有被阻塞的线程。假设还是不明白的话就看一下MSND上面的示例代码
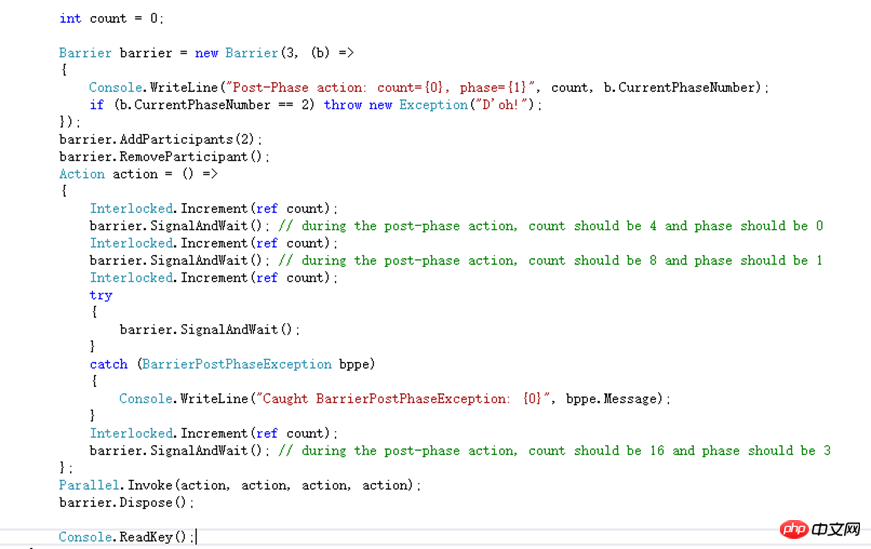
这里给Barrier初始化的参与者数量是3,同时每完成一个步骤的时候会调用委托,该方法是输出count的值步骤索引。参与者数量后来增加了两个又减少了一个。每个参与者的操作都是相同,给count进行原子自增,自增完则调用SgnalAndWait告知Barrier当前步骤已完成并等待下一个步骤的开始。但是第三次由于回调方法里抛出了一个异常,每个参与者在调用SignalAndWait的时候都会抛出一个异常。通过Parallel开始了一个并行操作。假设并行开的作业数跟Barrier参与者数量不一样就会导致在SignalAndWait会有非预期的情况出现。
接下来说两个Attribute,这个估计不算是同步构造,但是也能在线程同步中发挥作用
MethodImplAttribute这个Attribute适用于方法的,当给定的参数是MethodImplOptions.Synchronized,它会对整个方法的方法体进行加锁,凡是调用这个方法的线程在没有获得锁的时候就会被阻塞,直到拥有锁的线程释放了才将其唤醒。对静态方法而言它就相当于把该类的类型对象给锁了,即lock(typeof(ClassType));对于实例方法他就相当于把该对象的实例给锁了,即lock(this)。最开始对它内部调用了lock这个结论存在猜疑,于是用IL编译了一下,发现方法体的代码没啥异样,查看了一些源码也好无头绪,后来发现它的IL方法头跟普通的方法有区别,多了一个synchronized
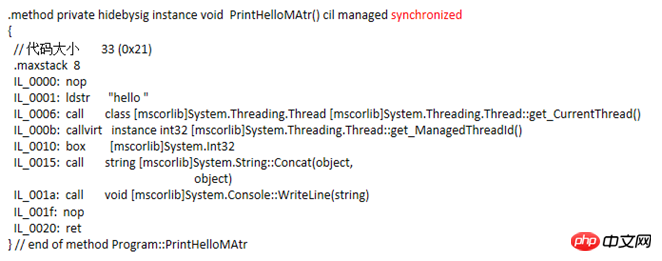
于是网上找各种资料,最后发现"junchu25"的博客[1][2]里提到用WinDbg来查看JIT生成的代码。
调用Attribute的
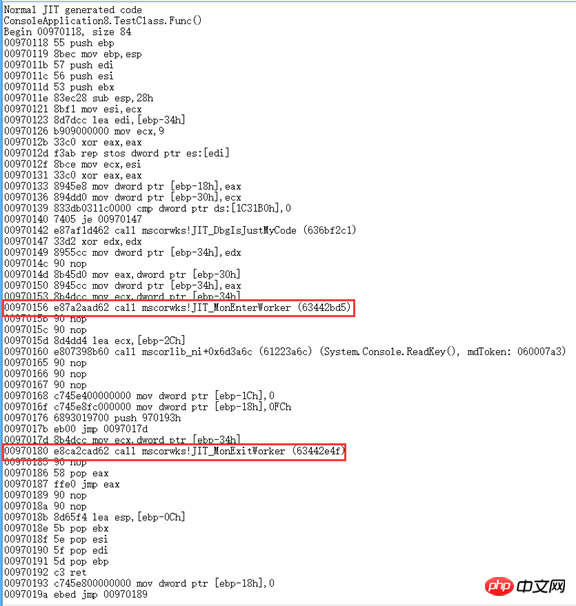
调用lock的
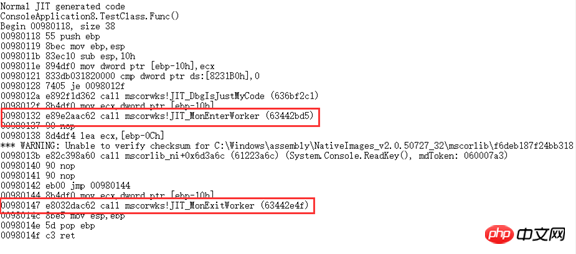
对于用这个Attribute实现的线程同步连Jeffrey都不推荐使用。
System.Runtime.Remoting.Contexts.SynchronizationAttribute這個Attribute適用於類,在類的定義中加了這個Attribute並繼承與ContextBoundOject的類,它會對類中的所有方法都加上同一個鎖,對比MethodImplAttribute它的範圍更廣,當一個執行緒呼叫此類的任何方法時,如果沒有獲得鎖,那麼該執行緒就會被阻塞。有個說法是它本質上調用了lock,對於這個說法的求證就更不容易,國內的資源少之又少,裡面又涉及到AppDomain,線程上下文,最後核心的就是由SynchronizedServerContextSink這個類去實現的。 AppDomain應該要另立篇進行介紹。但這裡也要稍微說一下,以前以為內存中就是有線程棧與堆內存,而這只是很基本的劃分,堆內存還會劃分成若干個AppDomain,在每個AppDomain中也至少有一個上下文,每個物件都會從屬與一個AppDomain裡面的一個上下文。跨AppDomain的物件是不能直接存取的,要嘛進行按值封送(相當於深複製一個物件到呼叫的AppDomain),要嘛就按引用封送。對於按引用封送則需要該類別繼承MarshalByRefObject。對繼承了這個類別的物件進行呼叫時都不是呼叫類別的本身,而是透過代理的形式進行呼叫。那麼跨上下文的也需要進行按值封送操作。平常建構的一個物件都是在進程預設AppDomain下的預設上下文中,而使用了SynchronizationAttribute特性的類別它的實例是屬於另外的一個上下文中,繼承了ContextBoundObject基底類別的類別進行跨上下文存取物件時也是透過以引用封送的方式以代理程式存取對象,並非存取到對象本身。至於是否跨上下文存取物件可以透過的RemotingServices.IsObjectOutOfContext(obj)方法進行判斷。 SynchronizedServerContextSink是mscorlib的內部類別。當執行緒呼叫跨上下文的物件時,這個呼叫會被SynchronizedServerContextSink封裝成WorkItem的物件,該物件也mscorlib的中的一個內部類,SynchronizedServerContextSink就請求SynchronizationAttribute,Attribute根據現在是否有多個WorkItem的執行請求來決定當前處理的這個WorkItem會馬上執行還是放到一個先進先出的WorkItem隊列中按順序執行,這個隊列是SynchronizationAttribute的一個成員,隊列成員入隊出隊時或者Attribute判斷是否馬上執行WorkItem時都需要獲取一個lock的鎖,被鎖的物件也正是這個WorkItem的隊列。這裡面涉及幾個類的交互,鄙現在還沒完全看清,以上這個處理過程可能有錯,待分析清楚再進行補充。不過透過這個Attribute實現的線程同步按逼人的直覺也是不建議使用的,主要是性能方面的損耗,鎖的範圍也比較大。
以上是詳解C#多執行緒之執行緒同步(圖文)的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















