
在之前的文章node入門場景之——爬蟲已經介紹過最簡單的node爬蟲實現,本文在原先的基礎上更進一步,探討一下如何繞過登錄,爬取登錄區內的數據
http作為一種無狀態的協議,客戶端和伺服器端之間不會保持長連線。你,很容易想到如下一種機制:
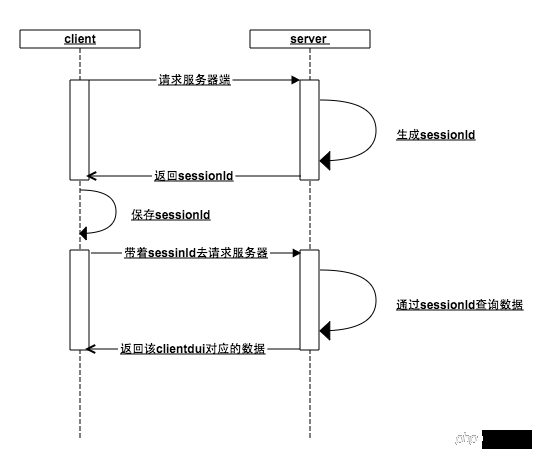
sessionId.png
這種機制的核心在於會話id(sessionId):
當客戶端請求伺服器端的時候,服務端判斷該客戶端沒有傳入sessionId,好的,這傢伙是新來的,給它生成一個sessionId,存入內存,並把這個sessionId返回客戶端
客戶端拿到伺服器端的sessionId保存在本地,下次請求的時候帶上這個seesionId,伺服器檢查內存是否存在這個sessionId(如果在之前的某個步驟,用戶訪問了登錄接口,那麼此刻內存中已經以seesionId為key,用戶數據為value保存在了內存中 ),伺服器就可以根據sessionId這個唯一標識,傳回該客戶端對應的資料
#無論是客戶端或伺服器端遺失了這個sessionId都會導致前面的步驟重新來過,誰也不認識誰了,重新開始
首先客戶端透過sessionId和伺服器端建立一種關聯,然後用戶再透過客戶端與伺服器端建立一種關聯(sessionId與使用者資料的鍵值對),從而維持了登入態
實際上,瀏覽器是不是依照上述的機制設計的呢?還真是!
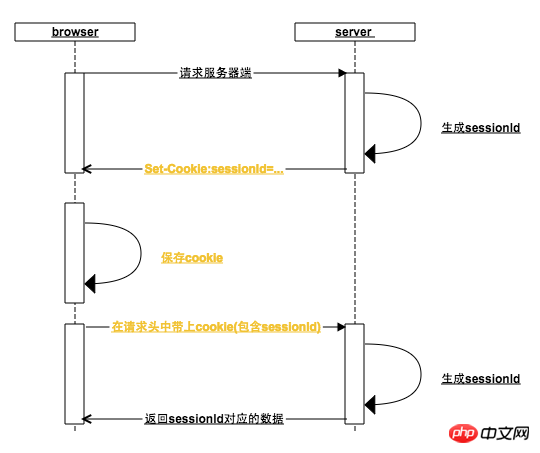
bs-sid.png
#這其中瀏覽器做了哪些事情:
一、瀏覽器在每一次http請求中,都會在http的請求頭中加上該請求地址域名對應的cookie(如果cookie沒有被用戶禁用的話),在上圖中,第一個次請求伺服器請求頭中同樣有cookie,只是Cookie中還沒有sessionId
二、瀏覽器根據伺服器回應頭中的Set-Cookie設定cookie,為此,伺服器會將產生的sessionId放入Set-cookie中
瀏覽器接收到Set-Cookie指令,就會以請求位址的網域為key設定本機cookie,一般情況下,伺服器在回傳Set-cookie的時候,對sessionId的過期時間預設為瀏覽器關閉時失效,這就是瀏覽器從打開到關閉就是一次會話的由來(有些網站還可以設定保持登錄,設定cookie長時間不失效爾爾)
三、 當瀏覽器再次向後台發起請求時,此時請求頭中的cookie已經包含了sessionId,如果在此之前用戶已經訪問過登錄接口,那麼就已經可以根據sessionId來查詢到用戶資料了
口說無憑,下面就以為例說明:
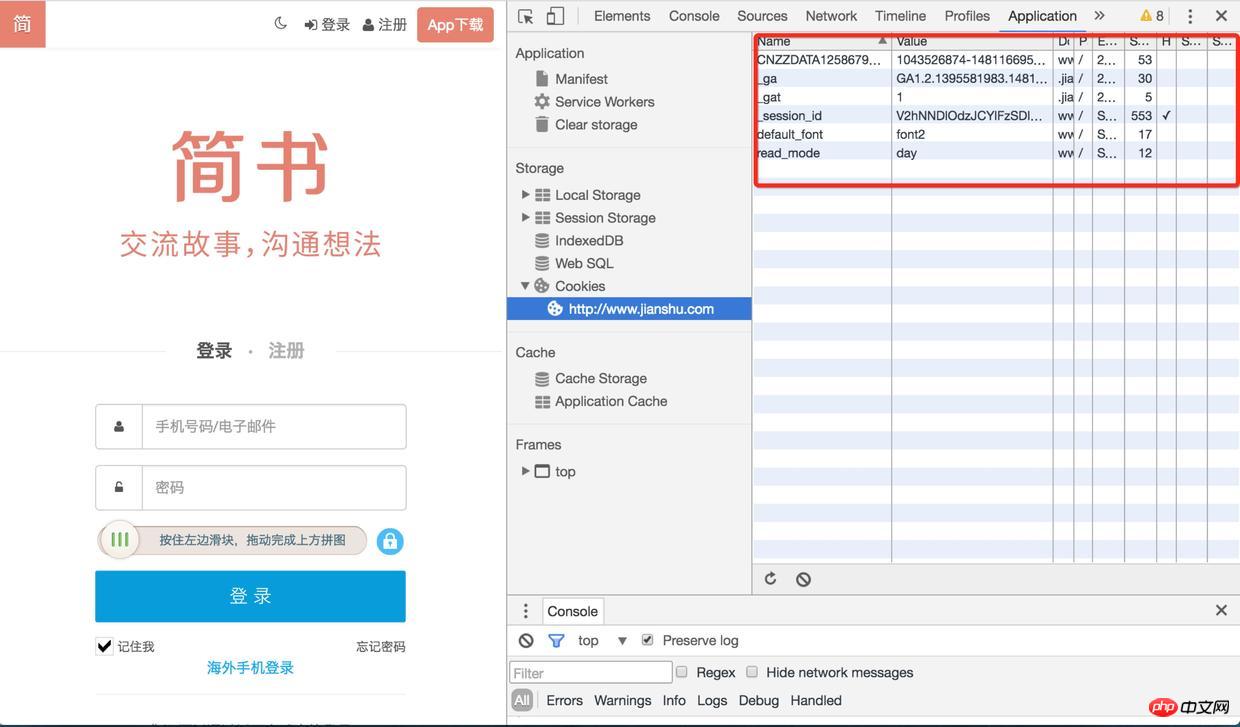
1). 首先用chrome打開的登入頁面,在application中找到http://www.jianshu.com下的所有cookie,進入Network項目中把preserve log勾選上(不然頁面發生了重定向之後將無法看到之前的log)
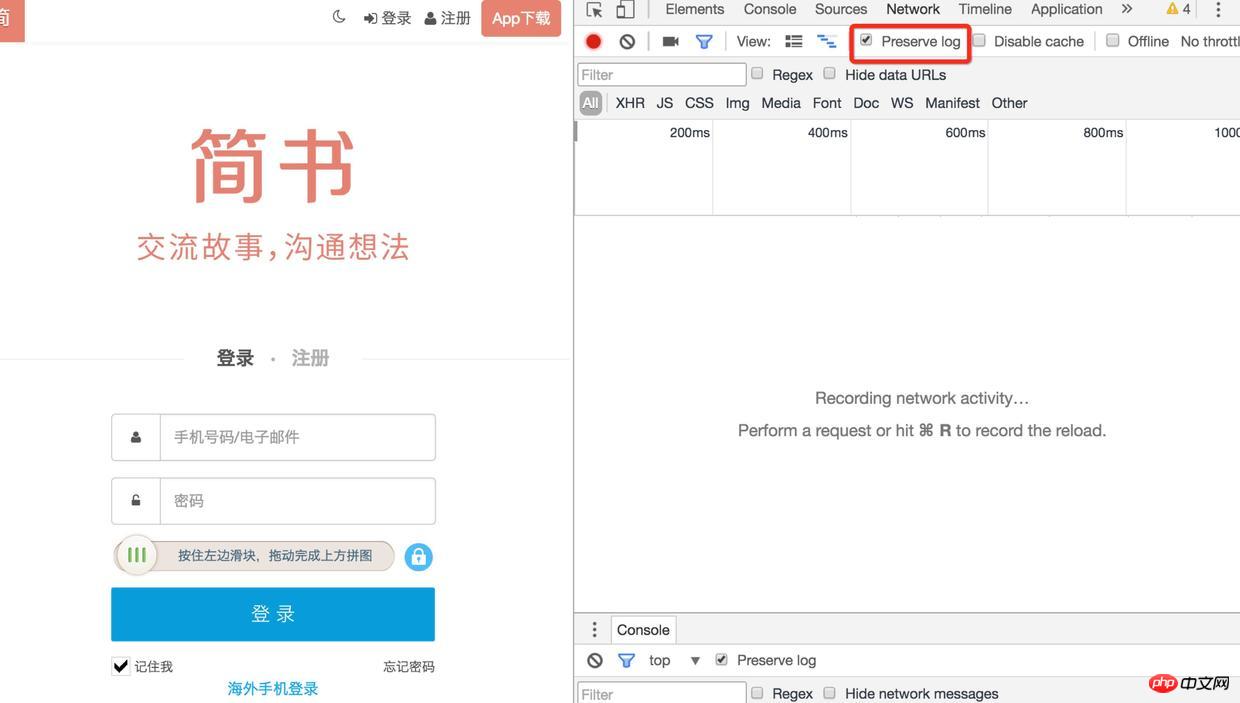
2). 然後刷新頁面,找到sign-in接口,它的響應頭中有很多Set-Cookie有木有
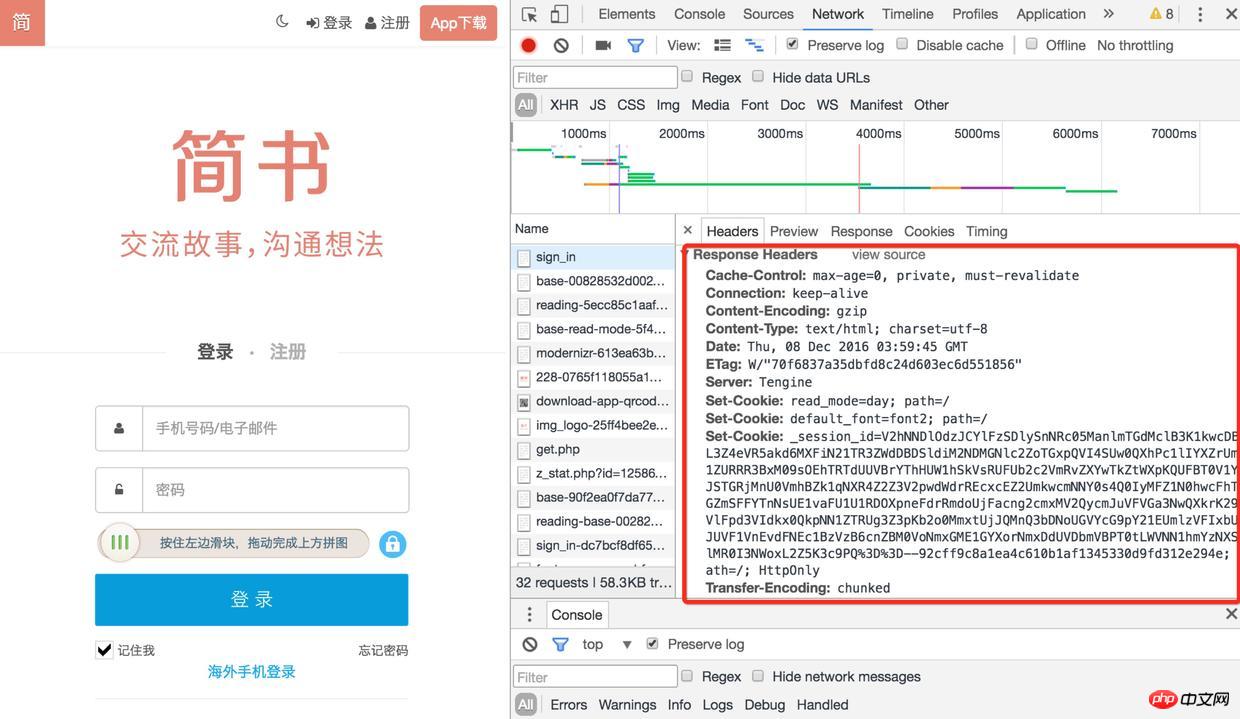
登入
3). 再去查看cookie的時候,session-id已經保存好了,下次再去請求的其它介面的時候(例如取得驗證碼、登入),都會帶著這個session-id,登入後使用者的資訊也會跟session-id關聯起來
登入
我們需要模擬瀏覽器的工作方式,去爬去網站登入區內的資料
找了一個沒有驗證碼的網站進行試驗,有驗證碼的又要涉及到驗證碼識別(的登入就不考慮了,驗證碼複雜程度感人),下節說明
// 浏览器请求报文头部部分信息
var browserMsg={
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36",
'Content-Type':'application/x-www-form-urlencoded'
};
//访问登录接口获取cookie
function getLoginCookie(userid, pwd) {
userid = userid.toUpperCase();
return new Promise(function(resolve, reject) {
superagent.post(url.login_url).set(browserMsg).send({
userid: userid,
pwd: pwd,
timezoneOffset: '0'
}).redirects(0).end(function (err, response) {
//获取cookie
var cookie = response.headers["set-cookie"];
resolve(cookie);
});
});
}需要現在chrome下捕獲一次請求,獲取一些請求頭的信息,因為伺服器可能會對這些請求頭資訊進行校驗。例如,在我實驗的網站上,起初我並沒有傳入User-Agent,伺服器發現並不是來自伺服器的請求,回傳了一串錯誤訊息,所以我之後設定User-Agent,把自己偽裝成chrome瀏覽器了~~
superagent是一個client-side HTTP request庫,使用它可以跟輕鬆的發送請求,處理cookie(自己調用http.request在操作header欄位資料上就沒有這麼方便,取得set-cookie之後,還要自己拼裝成合適的格式cookie)。 redirects(0)主要是設定不進行重定向
function getData(cookie) {
return new Promise(function(resolve, reject) {
//传入cookie
superagent.get(url.target_url).set("Cookie",cookie).set(browserMsg).end(function(err,res) {
var $ = cheerio.load(res.text);
resolve({
cookie: cookie,
doc: $
});
});
});
}在上一個步驟拿到set-cookie之後,傳入getData方法,在透過superagent設定到請求當中(set-cookie會格式化成cookie),就可以正常拿到登入去內的資料
在實際的場景中,未必會如此順利,因為不同的網站有不同的安全性措施,例如:有些網站可能需要先請求一個token,有些網站需要對參數進行加密處理,有些安全性較高的,還有防重播機制。在定向爬蟲中,這需要具體的去分析網站的處理機制,如果繞不過去,就適可而止吧~~
但是對付一般內容資訊類的網站還是夠用的
透過以上方式請求到的只是一段html字串,這裡還是老辦法,使用cheerio函式庫將字串載入,就可以拿到一個類似jquery dom的物件,就可以像jquery一樣去操作dom,這真的是神器,良心製作!
現在不需要輸驗證碼就可以登入的網站還有幾個?當然我們就不企圖去辨識12306的驗證碼了,這種良心之作驗證碼也不奢望了,像知乎這種too young too simple的驗證碼還是可以挑戰下的
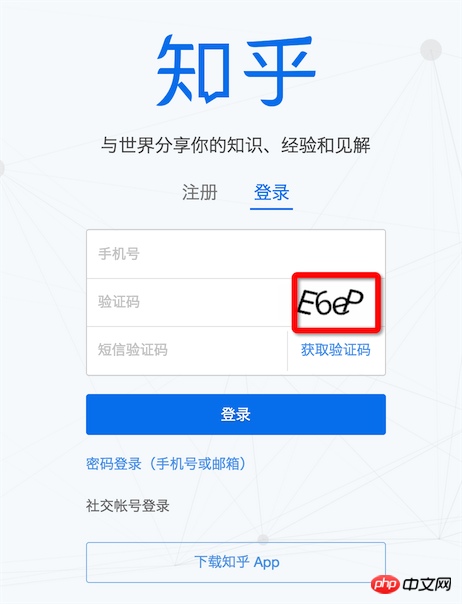
#知乎登入
Tesseract 是google開源的OCR辨識工具,雖然跟node沒有什麼關係,但是可以用node來調度使用,具體使用方式:用node.js實作驗證碼簡單辨識
然而即便是使用graphicsmagick來對圖片進行預處理,也不能保證有很高的辨識率,為此還可以對tesseract進行訓練,參考:利用jTessBoxEditor工具進行Tesseract3.02.02樣本訓練,提高驗證碼識別率
能不能做到高識別率,就看人品了~~~
還有一種更簡單的方式去繞過登入態,就是使用PhantomJS,phantomjs是一個基於webkit開源的伺服器js api,可以認為它就是一個瀏覽器,只是你可以透過js腳本來操控它。
由於其完全模擬瀏覽器的行為,所以你根本不需要關心set-cookie,cookie的事情,只需要模擬使用者的點擊操作就可以了(當然如果有驗證碼,還是得去識別的)
這種方式也並非毫無缺點,完全模擬瀏覽器的行為,意義者不放過任何一個請求,需要載入可能你並不需要的js、css、圖片的靜態#資源,需要點擊多個頁面才能到達目的頁面,在效率上要比直接訪問target url要低
#感興趣自行搜尋
phontomJS
雖然說的是node爬蟲的登錄,但是前面原理講了一大堆,目的是如果你想換一種語言實現,也可以游刃有餘,還是那句話:理解原理很重要
歡迎留言討論,如果對您有幫助,請留個讚~~
#以上是node爬蟲進階之-登入的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















