
一、緒論
上週工作需要了解專案的一些大體內容,結果在xml解析這一塊看的迷迷糊糊的,所以在這裡把學習到xml解析的一些知識記錄一下。
二、解析
android 中的xml解析器主要有三種,DOM解析器、SAX解析器和pull解析器。 ##Document
Object Model
) 是 XML文檔的物件模型,可用來直接存取XML文檔的各個部分。解析大文檔時不建議使用DOM解析。 。對XML文件進行操作時,首先要解析文件,將文件分為獨立的元素、屬性和註釋等,然後以節點樹的形式在記憶體中對XML文件進行表示,就可以透過節點樹存取文件的內容,並根據需要修改文件。介面定義分析並建立DOM文件的一系列方法,它是文件樹的根,是操作DOM的基礎。方法。 ##:提供獲得節點個數和目前節點的方法。
forXML)使用串流處理的方式,它不會記錄所讀內容的相關資訊。使用回呼函數來實現。 缺點是因為以事件為驅動的它不能回退。
它的核心是SAX的工作原理:SAX會順序掃描文檔,在掃描到文檔(document)開始與結束、元素(element)開始與結束、元素內容(characters)等時通知事件處理方法,事件處理方法進行相應處理,然後繼續掃描,指導文件掃描結束。 常用的SAX介面與類別:
#Attrbutes:用來取得屬性的數量、名字、值。
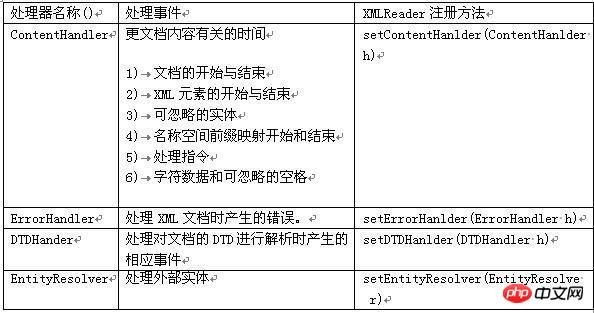
ContentHandler:定義與文件本身關聯的事件(例如,開始和結束標記)。大多數應用程式都註冊這些事件。
DTDHandler:定義與DTD關聯的事件。它沒有定義足夠的事件來完整地報告DTD。如果需要對DTD進行語法分析,請使用可選的DeclHandler。
DeclHandler是SAX的擴充。不是所有的語法分析器都支援它。
EntityResolver:定義與裝入實體關聯的事件。只有少數幾個應用程式註冊這些事件。
ErrorHandler:定義錯誤事件。許多應用程式註冊這些事件以便用它們自己的方式報錯。
DefaultHandler:它提供了這些接LI的預設實作。在大多數情況下,為應用程式擴展DefaultHandler並覆蓋相關的方法要比直接實作一個介面更容易。
以下是部分說明:
SAX處理器說明
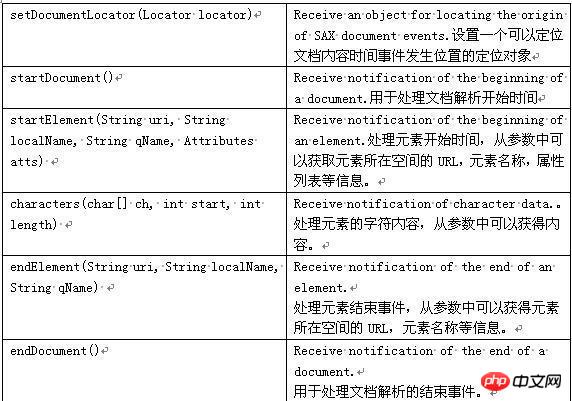
Pull內建於Android系統。也是官方解析佈局文件所使用的方式。 Pull與SAX有點類似,都提供了類似的事件,例如起始元素和結束元素。不同的是,SAX的事件驅動是回呼對應方法,需要提供回呼的方法,而後來在SAX內部自動呼叫對應的方法。而Pull解析器並沒有強制要求提供觸發的方法。因為他觸發的事件不是一個方法,而是一個數字。它使用方便,效率高。 Android官方推薦開發者使用Pull解析技術。 Pull解析技術是第三方開發的開源技術,它同樣可以應用於JavaSE開發。
pull回傳的
常數 #讀取到xml的結束回傳END_DOCUMENT ; 讀取到xml的開始標籤回傳START_TAG;
讀取到xml的結束標籤回傳END_TAG;
讀取到xml的文字回傳TEXT; pull的工作原理:pull提供了開始元素和結束元素。當某個元素開始時,我們可以呼叫parser.
nextText從XML文件中擷取所有字元資料。當解釋到一個文件結束時,自動產生EndDocument事件。
常用的XML pull的介面和類別:XmlPullParser:XML pull解析器是一個在XMLPULL VlAP1中提供了定義解析功能的介面。
XmlSerializer:它是一個接口,定義了XML資訊集的序列。
XmlPullParserException
:拋出單一的XML pull解析器相關的錯誤。 start_document --> end_document --> start_tag -->end_tag########################################################################################################################################################################################################### #在Android中還有第四種方式:android.util.Xml類 ###(本人未使用過)###### 在Android API中,另外提供了Android. util. Xml類,同樣可以解析XML文件,使用方法類似SAX,也都需編寫Handler來處理XML的解析,但是在使用上卻比SAX來得簡單 ,如下所示:###### 以android. util. XML實作XML解析 :######MyHandler myHandler=new MyHandler0;######android. util. Xm1. parse(url.openC0nnection().getlnputStream(),Xml.Encoding.UTF-8,myHandler);#################三、實作####### ### 1、先建立一個參考xml文檔 (放在了as###set###s目錄中)############################## #### ## ### 靈渠在廣西壯族自治區興安縣境內,是世界上最古老的運河之一,並擁有「世界古代水利建築明珠」的美譽。靈渠古稱秦鑿渠、零渠、陡河、興安運河,於西元前214年鑿成通航,距今已2217年,仍發揮功用。
lt;imageurl>
9aa8fdb7b8322e08244d3c.jpg
200公里,流域面積達5400平方公里,南北貫穿山東半島,溝通黃渤兩海。膠萊運河自平度姚家村東的分水嶺南北分流。南流由麻灣口入膠州灣,為南膠萊河,長30公里。北流由海倉口入萊州灣,為北膠萊河,長100餘公里。 # com/baike/pic/item/389aa8fdb7b8322e08244d3c.jpg
#
#String name;// 名稱 Integer length;// 長度
String introduction;// 介紹urlpublic String getName() { name;}public void setName(String name) {
this.name = name;}public Integer getLength() {#return length;}public void setLength(Integer length) {this.length = length;}#public String getIntroduction() {return introduction;}public void setIntroduction(String introduction) {this.introduction = introduction;} public String getImageurl() {return Imageurl;}public void setImageurl(String imageurl) {#Imageurl = imageurl;}@Overridepublic String toString() {return "River [name=" + name + ", length=" + length + ", introduction="+ introduction + ", Imageurl=" + Imageurl + "]";}##}
採用DOM解析時具體處理步驟為:
2然後利用DocumentBuilderFactory創建DocumentBuilder
3 然後載入XML文件(Document),
4 然後取得文件的根結點(Element),
5 然後取得根結點中所有子節點的清單(NodeList),
6 然後使用再取得子節點清單中的需要讀取的結點。
下面我們就開始讀取xml文檔對象,並且加入List:
程式碼如下: 我們這裡是使用assets中的river.xml文件,那就需要讀取這個xml文件,回傳輸入流。 讀取方法為:inputStream=this.context.getResources().getAssets().open(fileName); 參數是xml檔案路徑,當然預設的是assets目錄為根目錄。
接著可以用DocumentBuilder物件的parse方法解析輸入流,並傳回document對象,然後再遍歷doument物件的節點屬性。
e.printStackTrace();/** * DOM解析xml方法
* @param filePath
* @return
#
## * @return # private ListDOMfromXML(String filePath) { #4 ##Listlist = new ArrayList();DocumentBuilderFactory factory =
null;
DocumentBuilder builder = null;
Document document = null ;
InputStream inputStream = null;//建構解析器
factory = DocumentBuilderFactory.newInstance();
#try {
builder = factory.newDocumentBuilder();
//找到xml檔案並且載入
inputStream = this.getResources().getAssets().open(filePath);//getAssets後預設根目錄為assets
document = builder.parse(inputStream);
//找到根Element
Element root=document.getDocumentElement();
#NodeList nodes=root.
getElementsByTagName(RIVER);
//遍歷根節點所有子節點,rivers 下所有river
River river = null;
for (int i = 0; i < nodes.getLength(); i++) {
river = new River();
//取得river元素節點
Element riverElement = (Element) nodes.item(i);
//設定river中name和length屬性值
river.setName(riverElement.getAttribute("name") );
river.setLength(Integer.parseInt(riverElement.getAttribute("length")));
//取得子標籤Element introduction = (Element) riverElement.getElementsByTagName(INTRODUCTION).item(0);
#Element imageurl = (Element) riverElement.getElementsByTagName(IMAGEURL).item(0);
//設定introduction和imageurl屬性
river.setIntroduction(introduction.getFirstChild().getNodeValue());
river.setImageurl(imageurl.getFirstChild().getNodeValue());
#list.add (river);
}
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.
printStackTrace();
} catch (IOException e) {
#// TODO Auto-generated catch block
} catch (SAXException e) {
// TODO Auto-generated catch block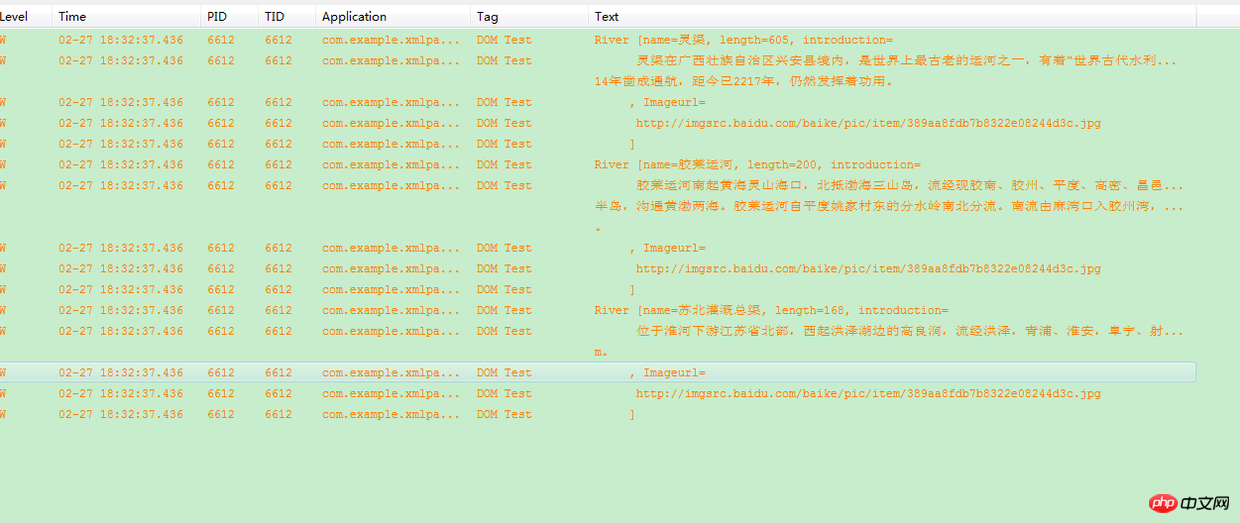
e.printStackTrace();
Log.w("DOM Test", river.toString());
}return list;
在這裡加入到List中, 然後我們使用log將他們列印出來。如圖所示:
XML解析結果1 建立SAXParserFactory物件
資料集
合。
程式碼如下:
##/**&*/
private ListSAXfromXML(String filePath) {
ArrayListlist = new ArrayList();
//建構解析器SAXParserFactory factory = SAXParserFactory.newInstance();SAXParser parser = null;XMLReader xReader = null;try {######parser = factory.newSAXParser();######//取得資料來源######xReader = parser.getXMLReader();######//設定處理器######RiverHandler handler = new RiverHandler();######xReader.setContentHandler(handler);###### //解析xml檔######xReader.parse(new InputSource(this.getAssets().open(filePath)));######list = handler.getList();##### #} catch (ParserConfigurationException e) {###e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
for (River River : list) {
Log.w("DOM Test", River.toString() );
}
返回清單;
}
以上是Android中的xml解析的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















