
本次分享大綱:
CBO優化器存在哪些坑
CBO優化器坑的解決之道
加強SQL審核,將效能問題扼殺於襁褓之中
分享現場FAQ
這次分享,主要以日常常見優化器問題作為引子,一起探討CBO的那些坑的解決之道。
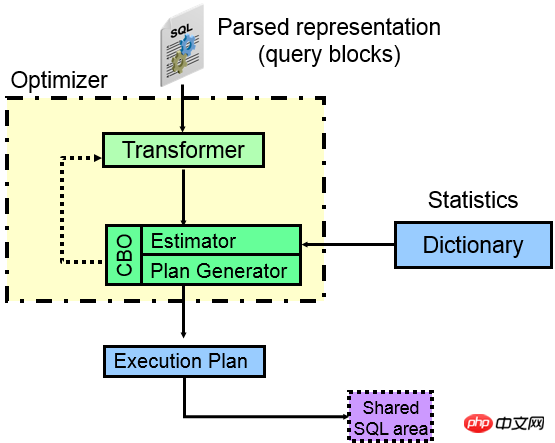
一、CBO優化器存在哪些坑先來看一下,CBO優化器的元件: ##從上圖可以看出,一條SQL進入ORACLE中,實際上經過解析會將各部分進行分離,每個分離的部分獨立成為一個查詢塊(query blocks),比如子查詢會成為一個查詢塊,外部查詢又是一個查詢區塊,那麼ORACLE優化器要做的工作就是各查詢區塊內部走什麼樣的存取路徑更好(走索引
、全表、分區?),其次就是各查詢區塊之間應該走什麼樣的JOIN方式以及JOIN順序,最後計算出那種執行計畫更好。 優化器的核心是查詢轉換器、成本估算器、執行計劃產生器
。 Transformer(查詢轉換器):從圖上可以看出,優化器的第一核心裝置就是查詢轉換器,查詢轉換器的主要功能就是研究各種查詢區塊之間的關係,並從語法上甚至語義上給予SQL等價重寫,重寫後的SQL更容易被核心裝置成本估算器和執行計劃產生器處理,從而利用統計資訊產生最優執行計劃。 查詢轉換器在最佳化器中有兩種方式:啟發式查詢轉換(基於規則)和基於COST的查詢轉換。 啟發式查詢轉換的一般是比較簡單的語句,基於成本的一般比較複雜,也就是說,符合基於規則的ORACLE不管什麼情況下都會進行查詢轉換,不符合的ORACLE可能考慮基於成本的查詢轉換。啟發式查詢轉換歷史悠久,問題較少,一般查詢轉換過的效率比不經過查詢轉換的要高,而基於成本的查詢轉換,因其與CBO優化器緊密關聯,在10G引入,內部非常複雜,所以BUG也比較多,在日常優化過程中,各種疑難SQL,往往就出現在查詢轉換失敗中,因為查詢轉換一旦失敗,Oracle就無法將原始SQL轉換成結構更好的SQL(更容易被最佳化器處理),顯然可選擇的執行路徑就要少很多,例如子查詢不能UNNEST,那麼,往往就是災難的開始。其實,查詢轉換中Oracle做的最多的就是將各種查詢轉換成JOIN方式,這樣就可以利用各種高效的JOIN方法了,例如HASH JOIN。 查詢轉換共有30種以上的方式,以下列出一些常見啟發式和基於COST的查詢轉換。 啟發式查詢轉換(一系列的RULE):很多啟發式查詢轉換在RBO情況下就已經存在。常見的有:######Simple View merge (簡單視圖合併)、SU (Subquery unnest 子查詢展開)、OJPPD (old style Join predicate push-down 舊的連接謂詞推入方式)、FPD (Filter push -down 過濾謂詞推入)、OR Expansion (OR擴展)、OBYE(Order by Elimination 排序消除)、JE (Join Elimination 連接消除或連接中的表消除)、Transitive Predicate (謂詞傳遞)等技術。 ######基於COST的查詢轉換(透過COST計算):######針對複雜的語句進行基於COST的查詢轉換,常見的有:######CVM (Complex view Merging 複雜視野合併)、JPPD (Join predicate push-down 關聯謂詞推入)、DP (Distinct placement)、GBP(Group by placement)等技巧。 ######透過一系列查詢轉換技術,將原始SQL轉換為最佳化器更容易理解和分析的SQL,以便能夠使用更多的謂詞、連接條件等,達到獲得最佳計畫的目的。查詢轉換的過程,可以透過10053取得詳細資訊。查詢轉換是否能夠成功和版本、最佳化器限制、隱含參數、補丁等有關。 ######隨便在MOS上搜尋查詢轉換,就會出現一堆BUG:###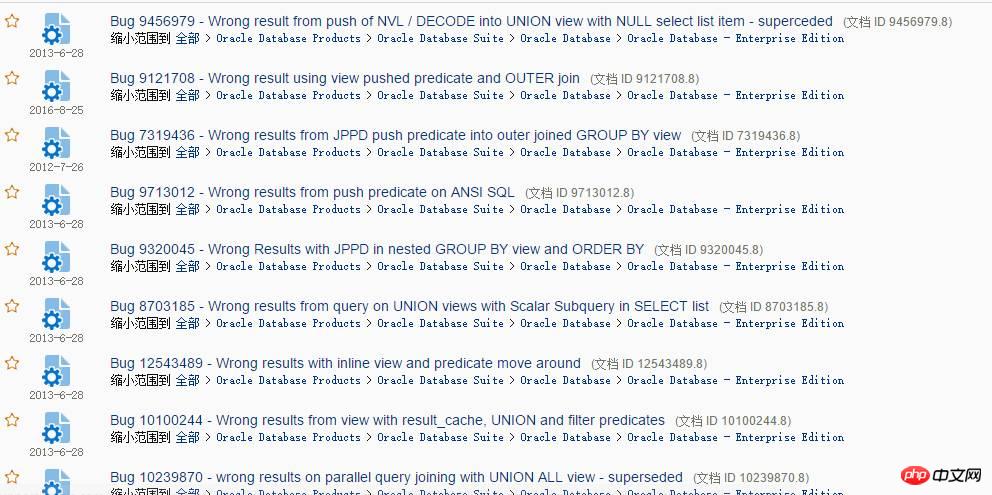
竟然還是Wrong result(錯誤的結果),遇到這種BUG不是效能問題了,而是嚴重的資料正確性問題,當然,在MOS裡隨便可以找到一堆這樣的BUG,但是,在實際應用中,我相信,你可能碰到的較少,如果有一天,你看到一條SQL查詢的結果可能不對,那你也得大膽質疑,對於Oracle這種龐然大物來說,遇到問題,質疑是非常正確的思考方式,這種Wrong result問題,在資料庫大版本升級過程中可能見到,主要有兩類問題:
原來結果正確,現在結果錯誤。 --遇到新版BUG
現在結果正確,原來結果錯誤。 --新版本修復了舊版BUG
第一種情況很正常,第二種情況也可能存在,我就看到一客戶質疑升級後的結果不正確,結果經過查證之後,竟然是舊版執行計畫就是錯的,新版執行計畫是正確的,也就是錯誤了很多年,都沒有發現,結果升級後是正確的,卻以為是錯了。
遇到錯誤結果,如果不是非核心功能,真的可能被深埋很多年。
Estimator( 估算器):
很顯然,估算器會利用統計資料(表格、索引、列、分割區等)來估算對應執行計畫作業中的選擇性,從而計算出對應操作的cardinality,產生對應操作的COST,並最終計算整個計劃的COST。對於估算器來說,很重要的就是其估算模型的準確性以及統計資訊儲存的準確性,估算的模型越科學,統計資訊能反應實際的資料分佈情況,能夠覆蓋更多的特殊數據,那麼產生的COST則更加準確。
然而,這是不可能的情況,估算器模型以及統計資訊中存在諸多問題,例如針對字串計算選擇性,ORACLE內部會將字串轉換為RAW類型,在將RAW類型轉換成數字,然後左起ROUND 15位,這樣會出現可能字串相差很大的,由於轉換成數字後超過15位,那麼內部轉換後可能結果相近,最終導致計算的選擇性不準確。
Plan Generator( 計畫產生器):
計畫產生器也就是分析各種存取路徑、JOIN方法、JOIN順序,從而生產不同執行計畫。那麼如果這個部分出現問題,也就是對應的部分可能演算法不夠完善或有限制。例如JOIN的表格很多,那麼各種存取順序的選擇成幾何級數增長,ORACLE內部有限制值,也就是事實不可能全部計算一遍。
例如HASH JOIN演算法是普遍做大數據處理的首選演算法,但由於HASH JOIN天生存在一種限制:HASH碰撞,一旦遇到HASH碰撞,必然導致效率大減。
CBO優化器有許多限制,詳細可以參考MOS:Limitations of the Oracle Cost Based Optimizer (文件 ID 212809.1)。
本部分主要分享下日常常見優化器問題案例,有的問題不僅限於CBO優化器,由於CBO是目前廣泛使用的優化器,因此,一律納入CBO問題。
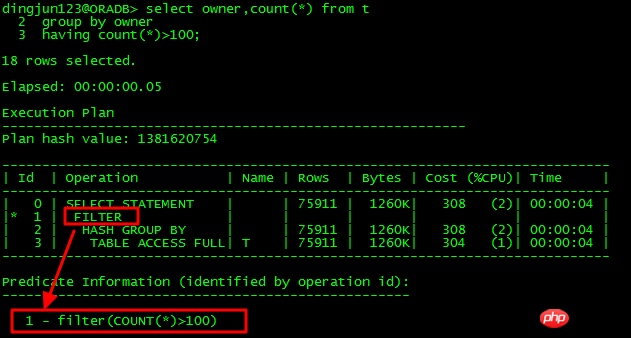
FILTER操作是執行計畫中常見的操作,這種操作有兩種情況:
只有一個子節點,那就是簡單過濾操作。
有多個子節點,那麼就是類似NESTED LOOPS操作,只不過與NESTED LOOPS差別在於,FILTER內部會建立HASH表,對於重複匹配的,不會再進行循環查找,而是利用已有結果,提高效率。但一旦重複匹配的較少,循環次數多,那麼,FILTER操作將是嚴重影響效能的操作,可能你的SQL幾天都執行不完了。
下面看看各種情況下的FILTER操作:
單子節點:
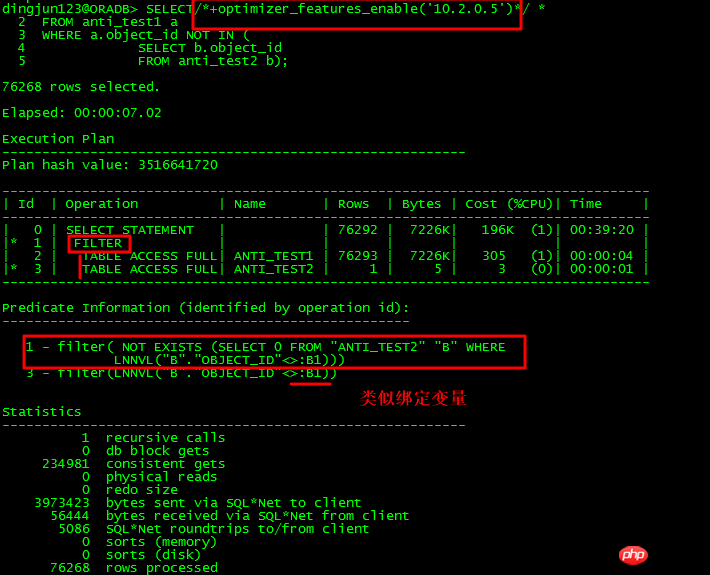
針對上面的NOT IN子查詢,如果子查詢object_id有NULL存在,則整個查詢都不會有結果,在11g之前,如果主表和子表的object_id未同時有NOT NULL約束,或都未加IS NOT NULL限制,則ORACLE會走FILTER。 11g有新的ANTI NA(NULL AWARE)優化,可以對子查詢進行UNNEST,從而提高效率。
對於未UNNEST的子查詢,走了FILTER,有至少2個子節點,執行計劃還有個特點就是Predicate謂詞部分有:B1這種類似綁定變數的東西,內部操作走類似NESTED LOOPS操作。
11g有NULL AWARE專門針對NOT IN問題進行最佳化,如下所示:
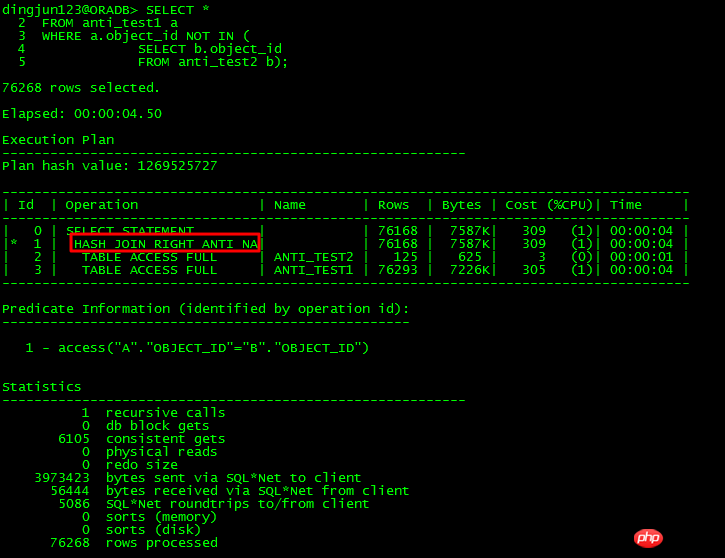
透過NULL AWARE操作,對無法UNNEST的NOT IN子查詢可以轉換成JOIN形式,這樣效率就大幅提升了。如果在11g之前,遇到NOT IN無法UNNEST,那該怎麼做呢?
將NOT IN部分的符合條件,針對本例就是ANTI_TEST1.object_id和ANTI_TEST2.object_id皆設為NOT NULL約束。
不改NOT NULL約束,則需要兩個object_id都增加IS NOT NULL條件。
改為NOT EXISTS。
改為ANTI JOIN形式。
以上四種方式,大部分情況下均能達到讓優化器走JOIN的目的。
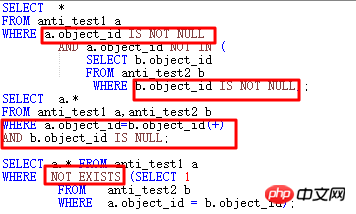
以上寫法執行計劃都是一樣的,如下所示:
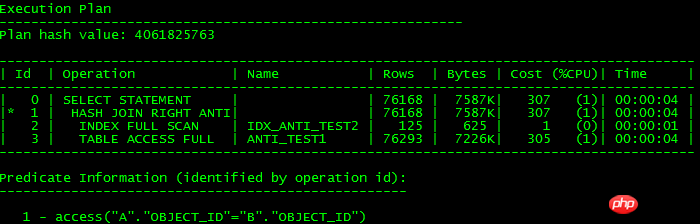
說白了,unnest subquery就是轉換成JOIN形式,如果能轉換成JOIN就可以利用高效JOIN特性來提高操作效率,不能轉換就走FILTER,可能影響效率,11g的NULL AWARE從執行計劃裡可以看出,還是有點區別,沒有走INDEX FULL SCAN掃描,因為沒有條件讓ORACLE知道object_id可能有NULL,所以也就走不了索引了。
OK,現在來說一個資料庫升級過程中碰到的案例,背景是11.2.0.2升級到11.2.0.4後下面SQL出現效能問題:
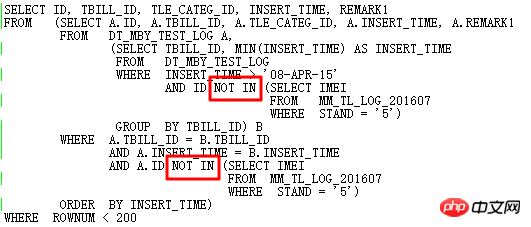
執行計畫如下:
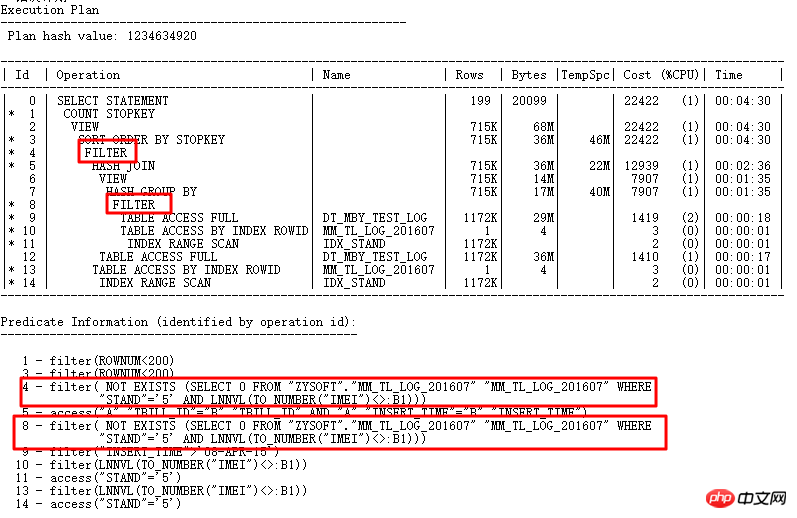
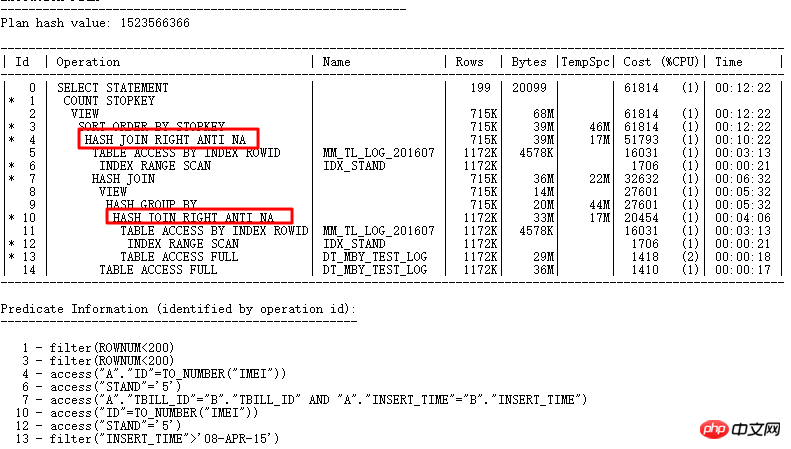
這裡的ID=4和ID=8兩個FILTER都有2個子節點,很明顯是NOT IN子查詢無法UNNEST導致的。上面說了在11g ORACLE CBO可以將NOT IN轉換成NULL AWARE ANTI JOIN,並且在11.2.0.2上是可以轉換的,到11.2.0.4上就不行了。兩個FILTER操作的危害到底有多大呢,可以透過查詢實際執行計劃來看:
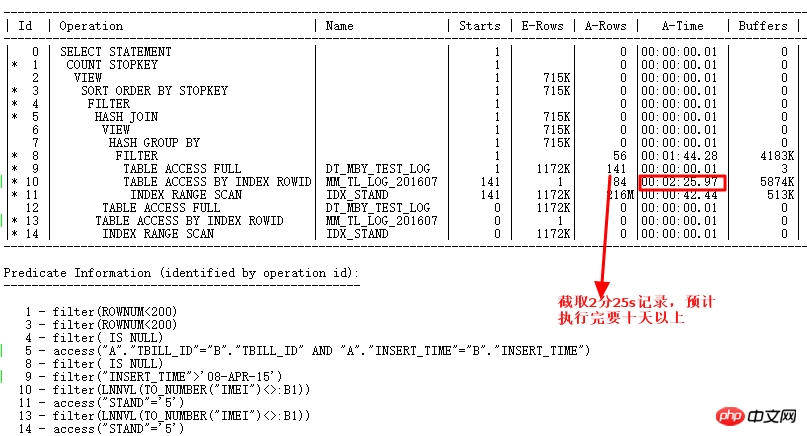
使用ALTER SESSION SET STATISTICS_LEVEL=ALL;截取2分25s的記錄查看實際情況,ID=9步驟的CARD=141行就需要2分25s,實際此步驟有:27w行
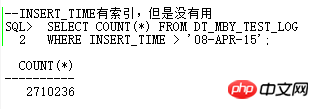
也就是這條SQL要執行10天以上了,簡直太恐怖了。
針對此問題的分析如下:
查詢和NULL AWARE ANTI JOIN相關的隱含參數是否有效
收集統計資料是否有效
是否是新版本BUG或是升級中修改了參數導致的
針對第一種情況:

參數是TRUE,顯然沒有問題。
針對第二種情況:
收集統計資料發現無效。
那麼此時,只能寄望於第三種情況:可能是BUG或升級過程中修改了其它參數影響了無法走NULL AWARE ANTI JOIN。 ORACLE BUG和參數那麼多,那我們要怎麼快速找到問題根源導致是哪個BUG或參數所造成的呢?這裡要跟大家分享一個神器SQLT,全名為(SQLTXPLAIN),這是ORACLE內部效能部門開發的工具,可以在MOS上下載,功能非常強勁。
回歸正題,現在要找出是不是新版本BUG或是修改了某個參數導致問題產生, 那麼就要用到SQLT的高階方法:XPLORE。 XPLORE會針對ORACLE中的各種參數不停打開、關閉,來輸出執行計劃,最終我們可以透過產生的報告,找到匹配的執行計劃來判斷是BUG問題還是參數設定問題。

使用很簡單,參考readme.txt將需要測試的SQL單獨編輯一個文件,一般,我們測試都使用XPLAIN方法,調用EXPLAIN PLAN FOR進行測試,這樣保證測試效率。
SQLT 找出問題根源:

#最終透過SQLT XPLORE找出問題根源在於新版本關閉了_optimier_squ_bottomup參數(和子查詢相關)。從這點上也可以看出來,很多查詢轉換能夠成功,不光是一個參數起作用,可能多個參數共同作用。因此,關閉預設參數,除非有強大的理由,否則,不可輕易修改其預設值。至此,此問題在SQLT的幫助下,快速得以解決,如果不使用SQLT,那麼解決問題的過程顯然更為曲折,一般情況下,估計是讓開發先修改SQL了。
思考一下,原來的SQL是不是還可以更優化呢?
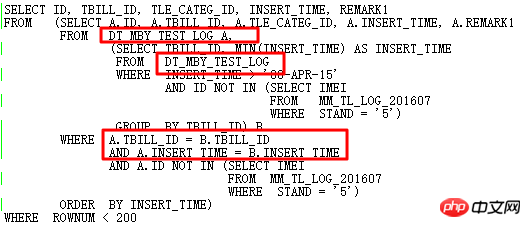
很顯然,如果要進一步優化,要徹底對SQL進行重寫,透過觀察,2個子查詢部分有相同點,經過分析語義:查找表DT_MBY_TEST_LOG在指定INSERT_TIME範圍內的,依照每個TBILL_ID取最小的INSERT_TIME,且ID不在子查詢中,然後結果依照INSERT_TIME排序,最後取TOP 199。
原SQL使用自連接、兩個子查詢,冗餘繁雜。自然想到用分析函數改寫,避免自連接,進而提高效率。改寫後的SQL如下:
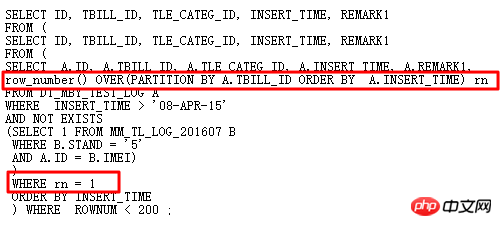
執行計畫:
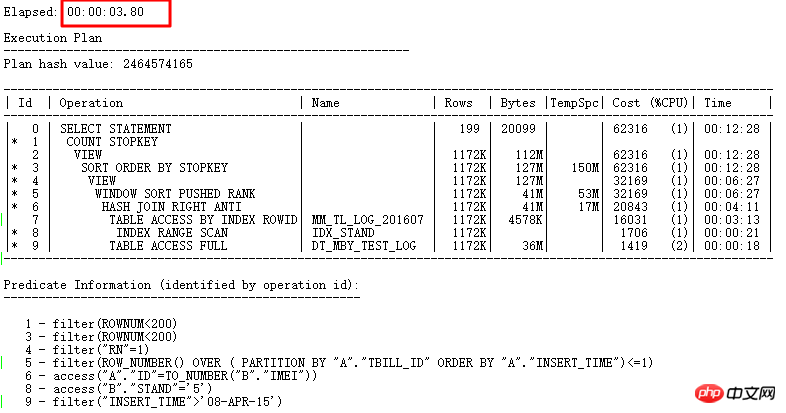
至此,這條SQL從原來的走FILTER需要耗時10天,到找出問題根源可以走NULL AWARE ANTI JOIN需要耗時7秒多,最後透過徹底改寫耗時3.8s。
(2) OR子查詢中的FILTER
再來看下常見的OR與子查詢連用情況,在實際優化過程中,遇到OR與子查詢連用,一般都不能unnest subquery了,可能會導致嚴重效能問題,OR與子查詢連用有兩種可能:
condition or subquery
subquery內部包含or,如in (select … from tab where condition1 or condition 2)
還是透過一個具體案例,分享下對於OR子查詢優化的處理方式,在某庫11g R2中碰到如下SQL,幾個小時都沒有執行完:

先來看下執行計畫:
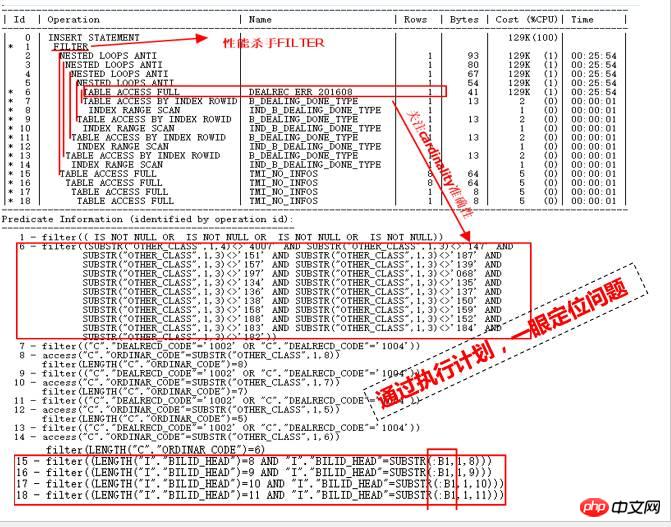
怎麼透過看到這個執行計劃,一眼定位效能慢的原因呢?主要透過下列幾點來分析定位:
執行計畫中的Rows,也就是每個步驟回傳的cardinality很少,都是幾行,在分析表也不是太大,那麼怎麼可能導致運行幾個小時都執行不完呢?很大原因可能就在於統計資訊不準,導致CBO優化器估算錯誤,錯誤的統計資訊導致錯誤的執行計劃,這是第一點。
看ID=15到18部分,它們是ID=1 FILTER操作的第二個子節點,第一個子節點是ID=2部分,很顯然,如果ID=2部分估算的cardinality錯誤,實際情況很大的話,那麼對ID=15到18部分四個表全掃描次數將會巨大,那麼也就導致災難產生。
很顯然,ID=2部分的一堆NESTED LOOPS也是很可疑的,找到ID=2操作的入口在ID=6部分,全表掃描DEALREC_ERR_201608,估算返回1行,很顯然,這是導致NESTED LOOPS操作的根源,因此,需要檢驗其準確性。
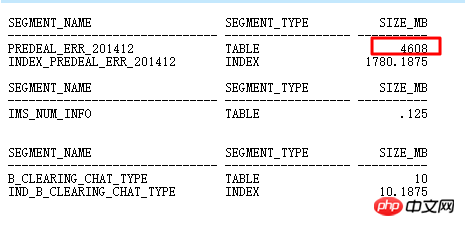
主表DEALREC_ERR_201608在ID=6查詢條件中經查要返回2000w行,計劃中估算只有1行,因此,會導致NESTED LOOPS次數實際執行千萬次,導致效率低下,應該走HASH JOIN,需要更新統計資訊。
另外ID=1是FILTER,它的子節點是ID=2和ID=15、16、17、18,同樣的ID 15-18也被驅動千萬次。
找出問題根源後,逐步解決。首先要解ID=6部分針對DEALREC_ERR_201608表格依照查詢條件substr(other_class, 1, 3) NOT IN (‘147’,‘151’, …)所得的cardinality的準確性,也就是要收集統計資料。
然而發現使用size auto,size repeat,對other_class收集直方圖均無效果,執行計劃中對other_class的查詢條件回傳行估算還是1(實際2000w行)。

再次執行後的執行計劃如下:
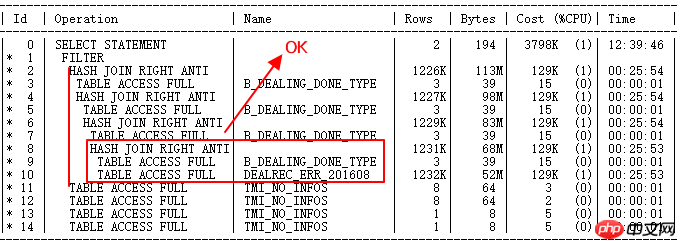
DEALREC_ERR_201608與B_DEALING_DONE_TYPE原來走NL的現在正確走HASH JOIN。 Build table是小結果集,probe table是ERR表大結果集,正確。
但是ID=2與ID=11到14,也就是與TMI_NO_INFOS的OR子查詢,還是FILTER,驅動數千萬次子節點查詢,下一步優化要解決的問題。
性能從12小時到2小時。
現在要解決的就是FILTER問題,對子查詢有OR條件的,簡單條件如果能夠查詢轉換,一般會轉為一個union all view後再進行semi join、anti join(轉換成union all view,如果謂詞類型不同,則SQL可能會報錯)。對於這種複雜的,優化器就無法查詢轉換了,因此,改寫是唯一可行的方法。分析SQL,原來查詢的是同一張表,而且條件類似,只是取的長度不同,那就好了!

如何讓帶有OR的子查詢執行計劃從FILTER變成JOIN。兩種方法:
1)改為UNION ALL/UNION
2)語意改寫.前面已經使用語意改寫,內部轉為了類似UNION的操作,如果要繼續減少表格的訪問,則只能徹底改寫OR條件,避免轉換為UNION操作。
再來分析下原始OR條件:
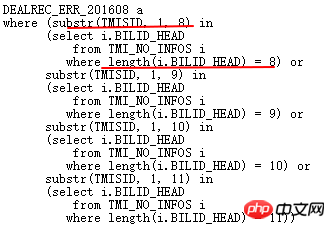
上面意義是ERR表的TMISID截取前8,9,10,11位元與TMI_NO_INFOS.BILLID_HEAD匹配,對應匹配BILLID_HEAD長度剛好為8,9,10,11。顯然,語意上可以這樣改寫:
ERR表與TMI_NO_INFOS表關聯,ERR.TMISID前8位與ITMI_NO_INFOS.BILLID_HEAD長度在8-11之間的前8位完全匹配,在此前提下,TMISID like 'BILLID_HEAD %'。
現在就動手徹底改變多個OR子查詢,讓SQL更加精簡,效率更高。改寫如下:
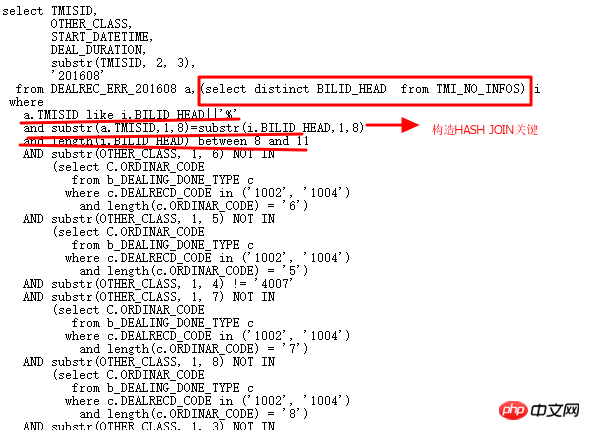
執行計畫如下:
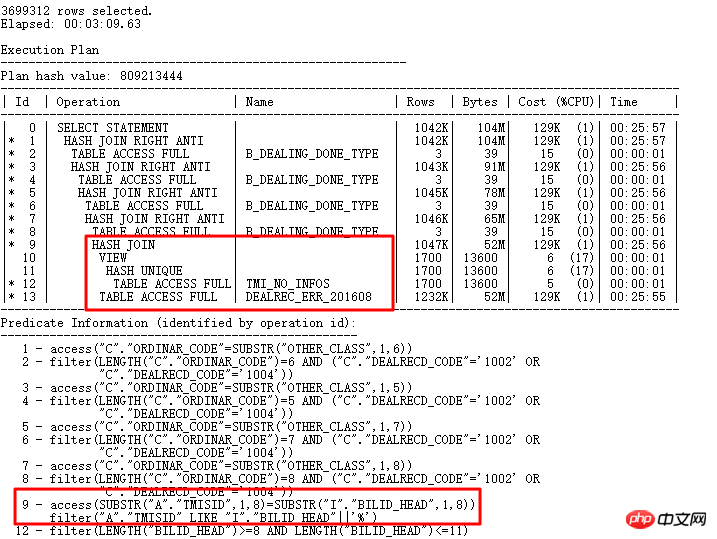
1)現在的執行計畫終於變的更短,更容易讀,透過邏輯改寫走了HASH JOIN, 最後一條回傳300多萬行資料的SQL原先需要12小時運行的SQL,現在3分鐘就執行了。
2) 思考:結構良好,語意清晰的SQL編寫,有助於優化器選擇更合理的執行計劃,所以說,寫好SQL也是門技術活。
透過這個案例,希望能給大家一些啟發,寫SQL如何能夠自己充當查詢轉換器,編寫的SQL能夠減少表、索引、分區等的訪問,能夠讓ORACLE更易使用一些高效算法進行運算,進而提高SQL執行效率。
其實,OR子查詢也不一定就完全不能unnest,只是絕大多數情況下無法unnest而已,請看下例:
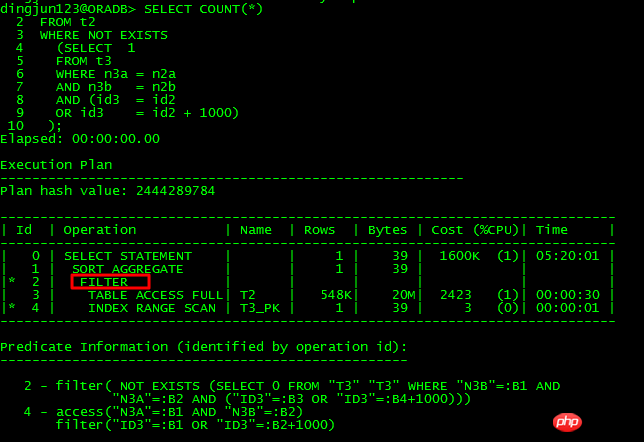
不可unnest的查詢:
可以unnest的查詢:
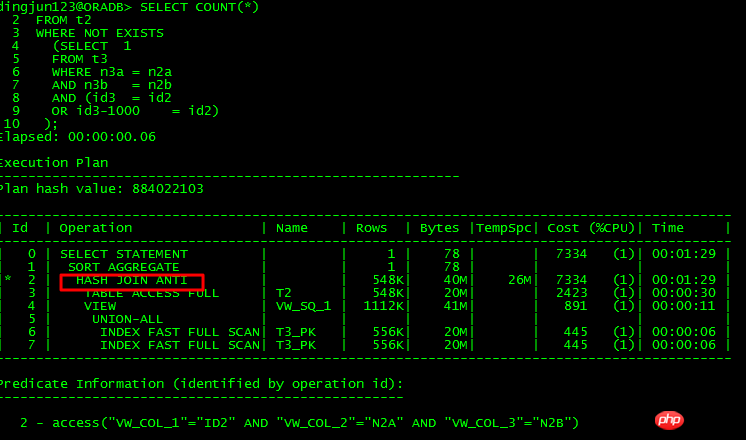
這2個SQL的差異也就是將條件or id3 = id2-1000轉換成or id3 -1000 = id2,前者不可以unnest,後者可以unnest,透過分析10053可以得知:
不可unnest的出現:
SU: Unnesting query blocks in query block SEL$1 ( #1) that are valid to unnest.
Subquery Unnesting on query block SEL$1 (#1)SU: Performing unnesting that does not require costing.
##SU: Considering subquery unnest on query block SEL$1 (#1).SU: Checking validity of unnesting subquery SEL$2 (#2)SU: SU bypassed: Invalid correlated predicates.
SU: Validity checks failed.
#可以unnest的出現:



 1並將SQL改寫為:
1並將SQL改寫為:
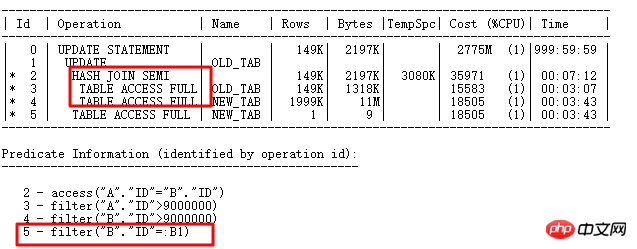
這裡要更新14999行,執行計畫如下:
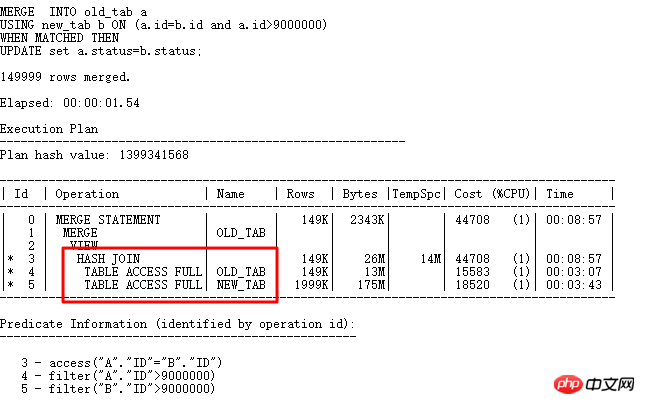
ID=2部分是where exists選擇部分,先把需要更新的條件查詢出來,之後執行UPDATE關聯子查詢更新,可以看到ID=5部分出現綁定變數:B1,顯然UPDATE運算就類似於原來的FILTER,對於選出的每行與子查詢表NEW_TAB關聯查詢,如果ID列重複值較少,那麼子查詢執行的次數就會很多,從而影響效率,也就是ID=5的操作要執行很多次。 當然,這裡欄位ID唯一性很強,可以建立UNIQUE INDEX,普通INDEX燈,這樣第5步就可以走索引了。這裡為了舉例這種UPDATE的優化方式,不建索引,也可以搞定這樣的UPDATE:MERGR和UPDATE INLINE VIEW方式。
 b.status bstatus
b.status bstatus
FROM old_tab a,
new_tab b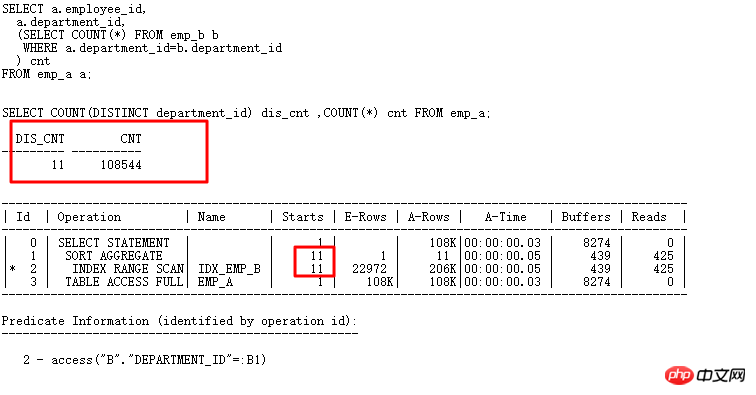
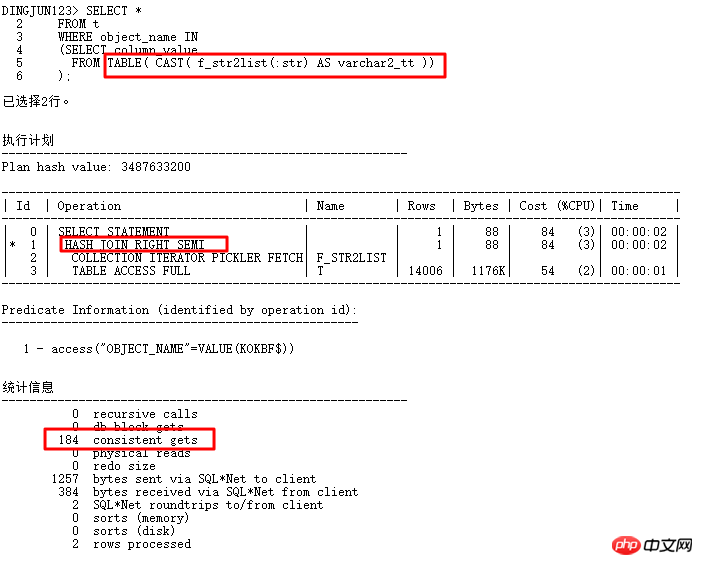 要求b.id是preserved key (唯一索引、唯一約束、主鍵),11g bypass_ujvc會報錯,類似MERGE操作。
要求b.id是preserved key (唯一索引、唯一約束、主鍵),11g bypass_ujvc會報錯,類似MERGE操作。
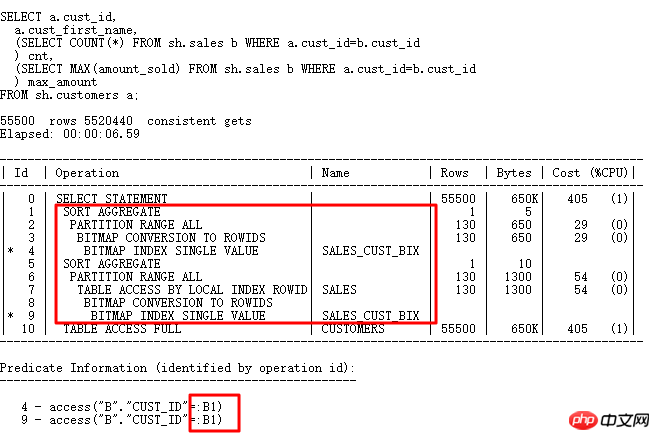
再來看看標量子查詢,標量子查詢往往也是引發嚴重效能問題的殺手:
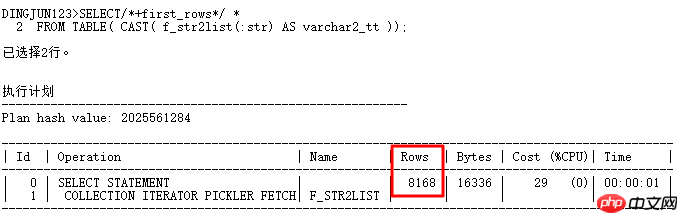 標量子查詢的計畫和一般計畫的執行順序不同,標量子查詢雖然在上面,但是它由下面的CUSTOMERS表結果驅動,每行驅動查詢一次標量子查詢(有CACHE例外),同樣類似FILTER操作。
標量子查詢的計畫和一般計畫的執行順序不同,標量子查詢雖然在上面,但是它由下面的CUSTOMERS表結果驅動,每行驅動查詢一次標量子查詢(有CACHE例外),同樣類似FILTER操作。
從上面結果看出,TABLE函數的預設行數是8168行(TABLE函數所建立的偽表是沒有統計資料的),這個值不小了,一般比實際應用中的行數要多的多,經常導致執行計劃走hash join,而不是nested loop。怎麼改變這種情況呢?當然可以透過hint提示來改變執行計劃了,對where in list,常常使用的hint有:
first_rows,index,cardinality,use_nl等。
這裡特別介紹下cardinality(table|alias,n) ,這個hint很有用, 它可以讓CBO優化器認為表的行數是n,這樣就可以改變執行計劃了。現在改寫上面的查詢:
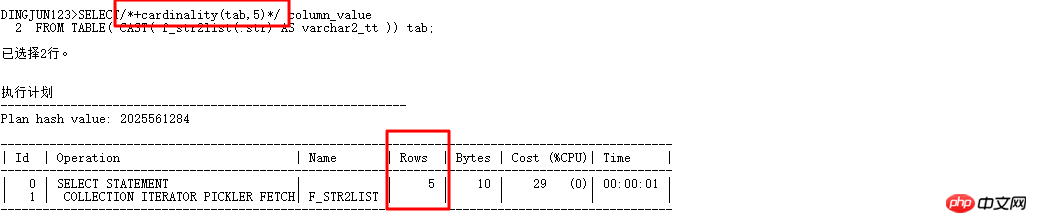
加了cardinality(tab,5)自動走CBO優化器了,優化器把表的基數看成5,前面的where in list查詢基數預設為8168的時候走的是hash join,現在有了cardinality,趕快試試:
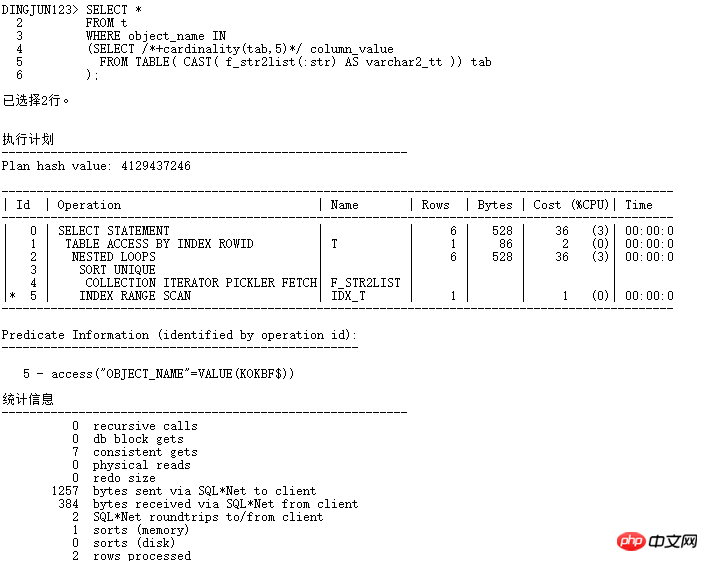
現在走NESTED LOOPS操作,子節點可以走INDEX RANGE SCAN,邏輯讀從184變成7,效率提升數十倍。當然,在實際應用中,最好不要加hints,可以使用SQL PROFILER綁定。
Oracle內部計算選擇性都是以數字格式計算,因此,遇到字串類型,會將字串轉換成RAW類型,再將RAW類型轉換成數字,且ROUND到左起15位,這樣對於轉換後的數字很大,可能原來字串相差比較大的,內部轉換後的數字比較接近,這樣就會引起選擇性計算不準確問題。如下例:

執行計劃如下:
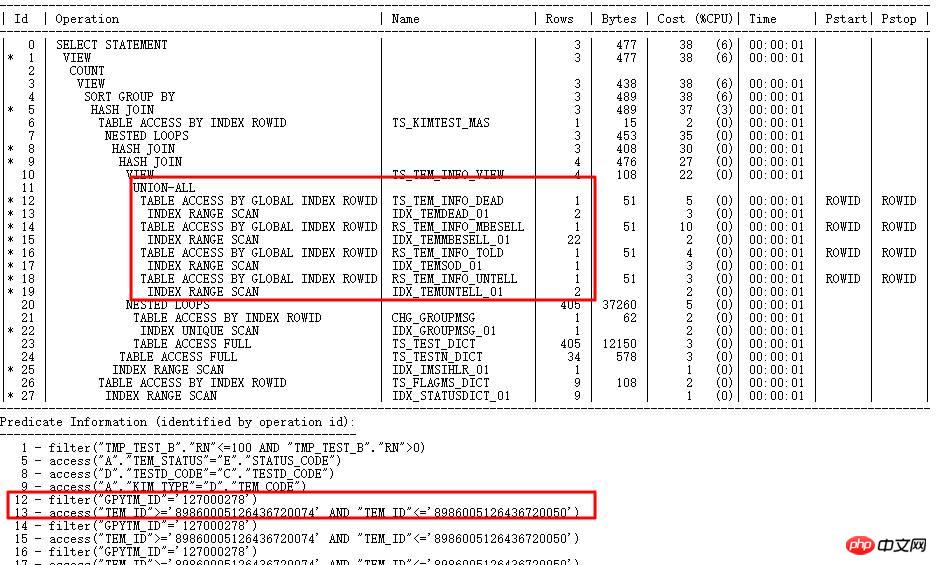
#SQL執行計劃走TEM_ID索引,需要執行1小時以上,計劃中對應步驟cardinality很少(幾十級),實際上很大(百萬級別),判斷統計資料出錯。
為什麼走錯索引?
由於TEM_ID是CHAR字串型,長度20,CBO內部運算選擇性會先將字串轉為RAW,然後RAW轉為數字,左起ROUND 15位元。因此,可能字串值差異大的,轉換成數字後值接近(因為超出15位元補0),導致選擇性計算錯誤。以TS_TEM_INFO_DEAD中的TEM_ID列為範例:

而實際依照條件查詢出的行數 29737305。因此,索引走錯了。
解決方法:
收集TEM_ID列直方圖,由於內部演算法有一定限制,導致值不同的字串,內部計算值可能一致,所以收集直方圖後,針對字串值不同,但是轉換成數字後相同的,ORACLE會將實際值儲存到ENDPOINT_ACTUAL_VALUE中,用於校驗,提高執行計畫的準確性。走正確索引GPYTM_ID後,運行時間從1小時以上到5s內。
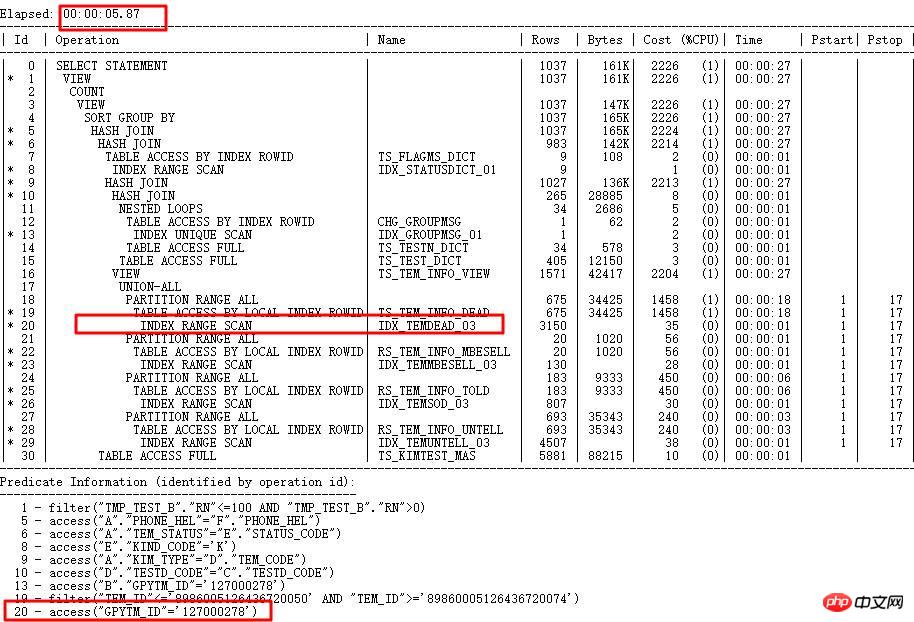
每個版本都會引入許多新特性,對於新特性,使用不當可能會引發一些嚴重問題,常見的例如ACS、cardinality feedback導致執行計劃變動頻繁,影響效率,子遊標過多等,所以,針對新特性需要謹慎使用,包括前面說的11g null aware anti join也存在很多BUG。
今天要分析的案例是10g到11g大版本升級過程中遇到的SQL,在10g中正常運行,但是到11g中卻執行出錯。 SQL如下:
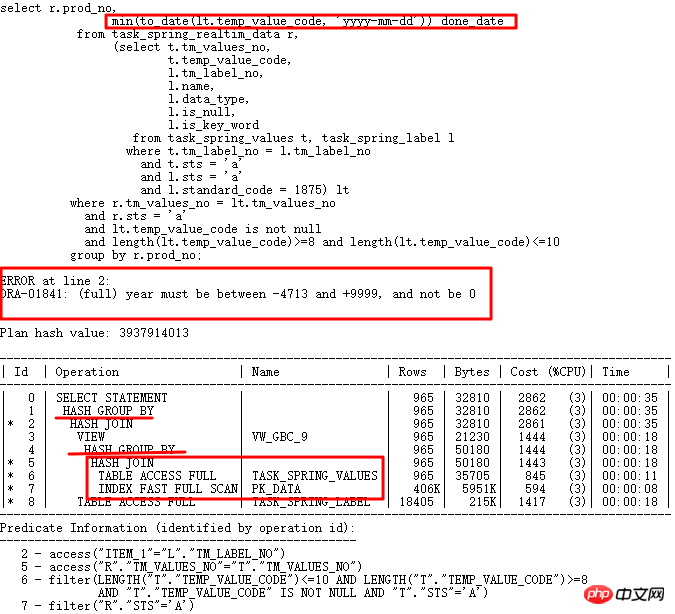
10g正常,升級11g r2後日期轉換出錯,temp_value_code存多種格式字串。正確執行計劃LT關聯查詢先執行,之後與外表關聯。錯誤執行計劃是TASK_SPRING_VALUES先與外表關聯然後分組,作為VIEW再與TASK_SPRING_LABEL關聯,再次分組,這裡有2個GROUP BY操作,與10g執行計劃中只有1個GROUP BY操作不同,最終導致報錯。
很顯然,對於為什麼出現兩個GROUP BY操作,需要進行研究,首選10053:
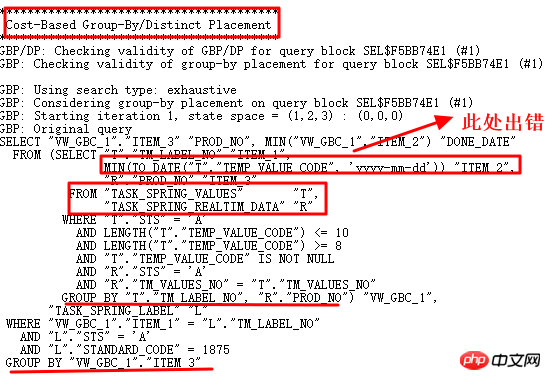
分析按照10053操作,是否找到非日期格式值:
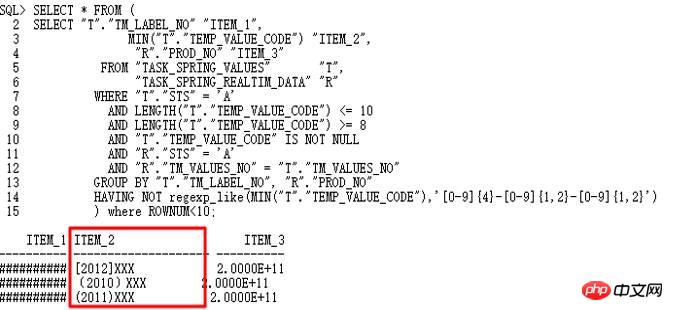
的確找到非yyyy-mm-dd格式字串,因此,to_date操作失敗。透過10053可以看出,這裡使用了Group by/Distinct Placement操作,因此,需要找到對應的控制參數,關閉此查詢轉換。
關閉GBP隱含參數後正確:_optimizer_group_by_placement。正確執行計劃如下:
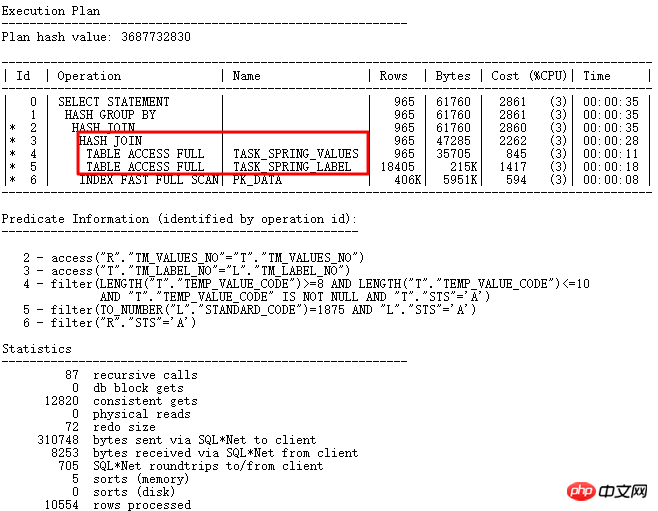
思考: 這個問題的本質在於字段用途設計不合理,其中temp_value_code作為varchar2儲存普通字元、數字型字元、日期格式yyyy-mm -dd,程式中有to_number,to_date等轉換,非常依賴執行計劃中表連接和條件的先後順序。所以,良好的設計很重要,特別要確保各關聯字段類型的一致性以及字段作用的單一性,符合範式要求。
結構優良的SQL能夠更易被CBO理解,從而更好地進行查詢轉換操作,從而為後續生成最佳執行計劃打下基礎,然後實際應用過程中,因為不注重SQL寫法,導致CBO也無能為力。以下以分頁寫法案例作為探討。
低效分頁寫法:

原寫法最內層依use_date等條件查詢,然後排序,取得rownum並取別名,最外層使用rn規律。問題在哪?
分頁寫法如果直接<,<=可在排序後直接rownum取得(兩層嵌套),如果需要取得區間值,在最外層取得>,>=(三層嵌套)。
此語句取得<=,而使用三層巢狀,導致無法使用分頁查詢STOPKEY演算法,因為rownum會阻止謂詞推入,導致執行計畫中沒有STOPKEY操作。
<=分頁只需要2層嵌套,done_date列有索引,根據條件done_date>to_date('20150916','YYYYMMDD')和只取得前20行,可有效利用索引和STOPKEY演算法,改寫完成後使用索引降序掃描,執行時間從1.72s到0.01s,邏輯IO 從42648到59,具體如下:

高效分頁寫法應該符合規範,並且能夠充分利用索引消除排序。
CBO BUG出現比較多的就是在查詢轉換中,一旦出現BUG,可能查找就比較困難,這時候應該透過分析10053或透過使用SQLT XPLORE快速找到問題根源。如下例:
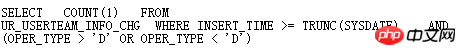
這個表的oper_type有索引,並且條件oper_type>'D' or oper_type<'D'走索引較好,但是實際上Oracle卻走了全表掃描,透過SQLT XPLORE快速分析:
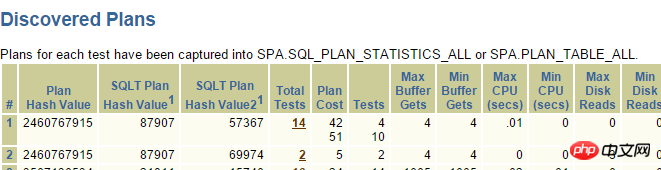
其中上面2個是走索引的執行計劃,點進去:
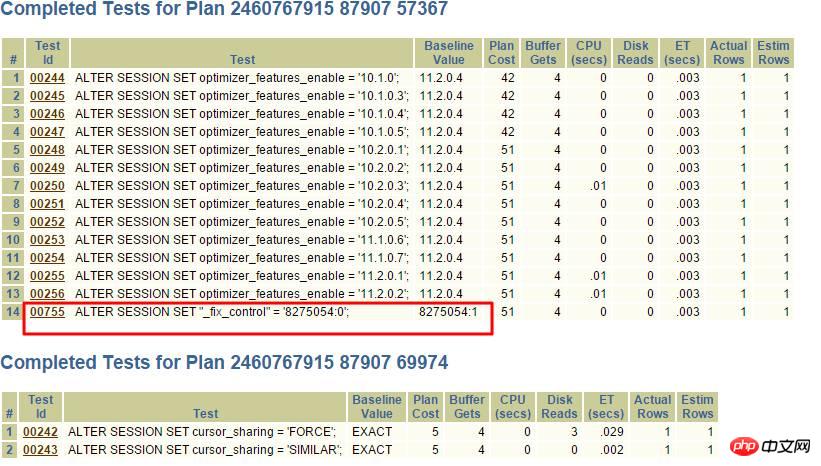
很顯然,_fix_control=8275054很可疑,透過查詢MOS:

轉換成a<>b,很顯然使用不了索引了,可以透過關閉此8275054解決。
HASHJOIN是專門用來做大數據處理的高效演算法,並且只能用於等值連接條件,針對表build table(hash table)和probe table建構HASH運算,找出滿足條件的結果集。
一般格式如下:
HASH JOIN
build table
probe table
這裡的build table應該選擇透過篩選條件過濾後,結果集尺寸較小的表(size不是rows),然後按照連接條件進行HASH函數運算,把需要的列和HASH函數運算結果儲存到hash bucket中,hash bucket本身就是鍊錶結構。同樣,對於probe table也需要進行hash函數運算,並根據運算結果到build table的hash bucket中去查詢,查到滿足,查不到丟棄。當然,ORACLE HASH JOIN內部構造還是很複雜的,具體可以參考Jonathan Lewis的CBO原理書。
HASH查找天生存在的問題:
一旦build table的連接條件列選擇性不好(也就是重複值特別多),那麼某些hash bucket上可能儲存大量數據,由於hash bucket本身是鍊錶結構,那麼當查詢這些hash bucket時,效率會急劇下降,此問題就是HASH運算的經典問題Hash Collision(HASH碰撞)。
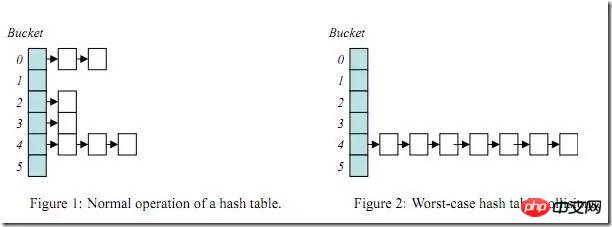
下面用一個小範例來分析下hash碰撞:
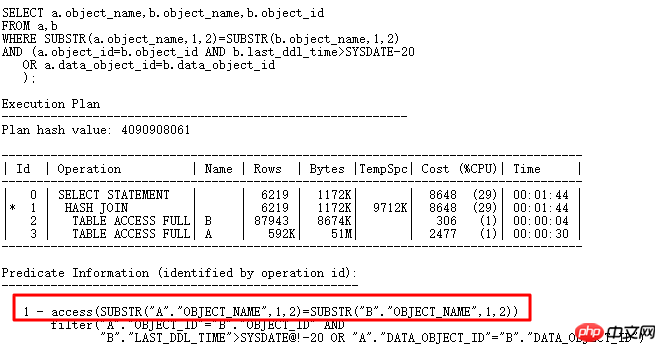
其中a 表61w 多筆記錄, b 表7w 多筆記錄,此SQL 結果傳回8w 多筆記錄,從執行計畫來看,做HASH JOIN 運算沒有什麼問題,但實際此SQL 執行10 分鐘以上都沒有執行完,效率非常低下, CPU 使用率突增,遠大於存取兩個表的時間。
如果你了解HASHJOIN,這時候,你應該考慮是不是遇到hash collision了,如果很多bucket上存儲大量數據,那麼對於這樣的hash bucket裡的數據查找那就類似於nested loops了,必然效率大減。如下進一步分析:

找出大於重複資料大於3000條的值,果然有很多,當然剩下資料也有很多比較大,探測HASH JOIN,可以使用EVENT 10104:
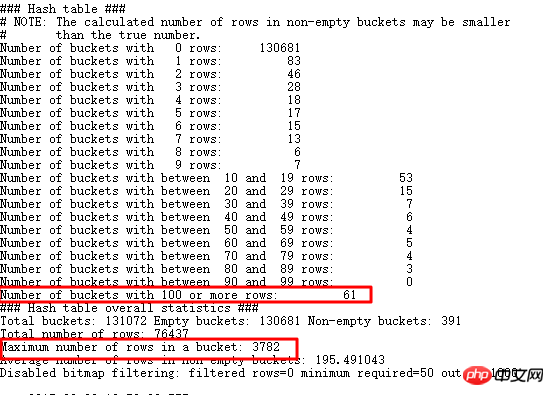
#可以看到儲存100行+的bucket有61個,而且最多的一個bucket中儲存了3782條,也就是和我們查詢出來的一致。還是回到原始SQL:
Oralce為什麼選擇substr(b.object_name,1,2)來建構HASH表呢,如果能將OR展開,原始SQL改為一個UNION ALL形式的,那麼HASH表可以採用substr(b.object_name,1,2)和b.object_id以及data_object_id來構建,那麼必然唯一性很好,那應該可以解決hash collision問題,改寫如下:

現在的SQL執行時間從原來的10幾分鐘都沒有結果,到4s執行完畢,再來看內部構建的HASHTABLE資訊:
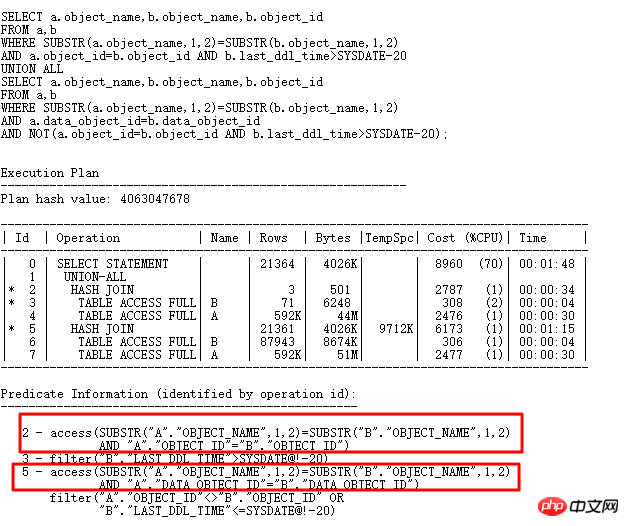
最多的一個bucket中只儲存6條數據,那肯定效能比前面好很多了。 Hash碰撞的危害很大,實際應用中,可能比較複雜,如果遇到hash碰撞問題,最好的方式就是進行SQL重寫,盡量從業務上分析,能不能增加其它選擇性比較好的列進行JOIN 。
回頭來看看,既然我都知道改寫成UNION ALL後,就採用2個組合列來建構比較好的HASH表,那麼 Oracle 為什麼不這麼做呢?很簡單,我這裡只是舉例刻意這麼做的而已,用以說明HASH碰撞的問題,對於這種簡單SQL,有選擇性更好的列,收集下統計信息,Oracle就可以將的SQL進行OR展開了。
應用系統SQL眾多,如果總是作為救火隊員角色解決線上問題,顯然不能滿足當今IT系統高速發展的需求,基於資料庫的系統,主要效能問題在於SQL語句,如果能在開發測試階段就對SQL語句進行審核,找出待優化SQL,並給予智能化提示,快速輔助優化,則可以避免眾多線上問題。另外,還可以對線上SQL語句進行持續監控,及時發現效能有問題的語句,從而達到SQL的全生命週期管理目的。
為此,公司結合多年運作維護與最佳化經驗,自主研發了SQL審核工具,大幅提升SQL審核最佳化與效能監控處理效率。
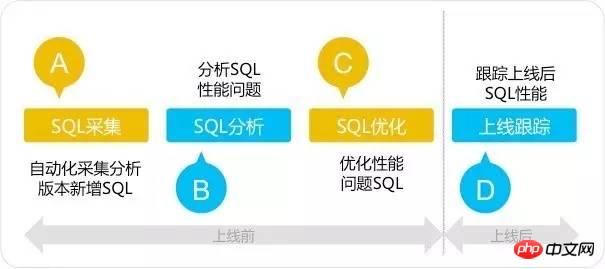
SQL審核工具採用四步驟法則:SQL採集—SQL分析—SQL最佳化—上線跟踪,SQL審核四步法區別傳統的SQL最佳化方法,它著眼於系統上線前的SQL分析與最佳化,重點解決SQL問題於系統上線前,扼殺效能問題於襁褓之中。如下圖所示:
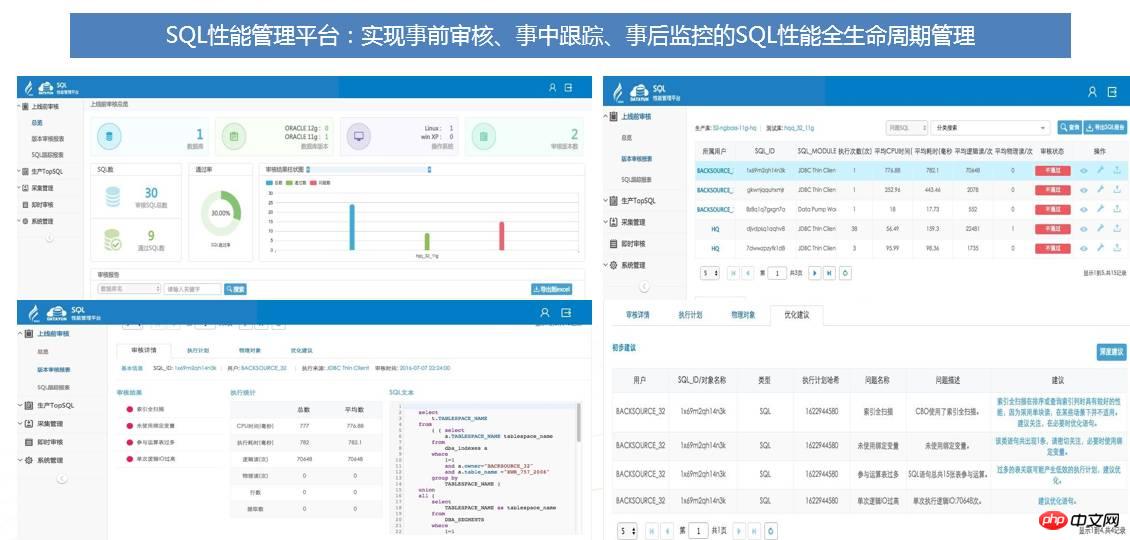
透過SQL效能管理平台可解決下列問題:
事前: 上線前SQL 效能審核,扼殺效能問題於襁褓之中;
事中:SQL效能監控處理,及時發現上線後SQL效能發生的變化,在SQL效能變化且未造成嚴重問題時,及時解決;
事後:TOPSQL監控,及時警告處理。
SQL效能管理平台實現了SQL效能的360度全生命週期管控,並且透過各種智慧化提示和處理,將絕大多數本來因SQL引發的效能問題,解決在問題發生前,先提高系統穩定性。
下面是SQL審核的典型案例:
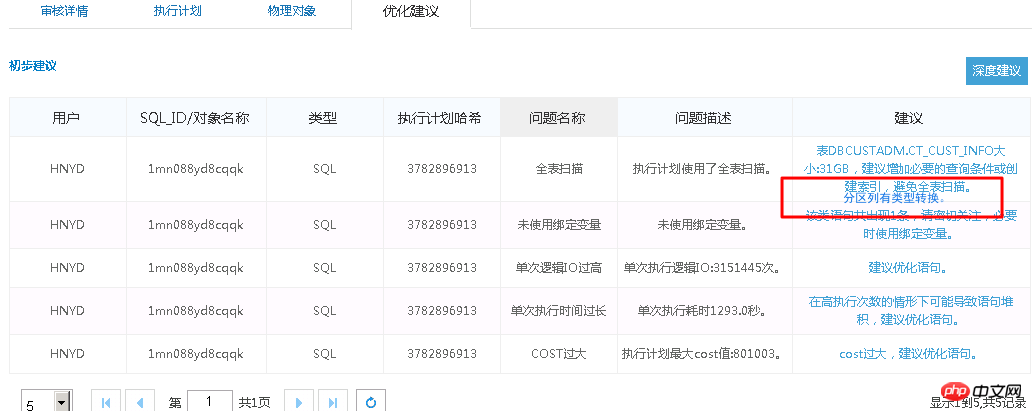
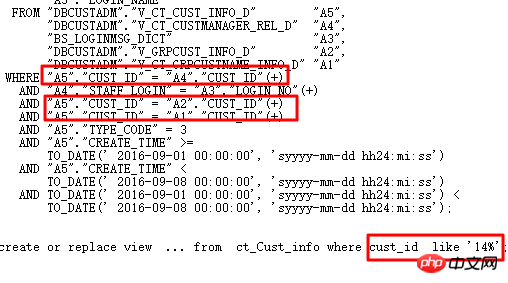
執行計畫如下:
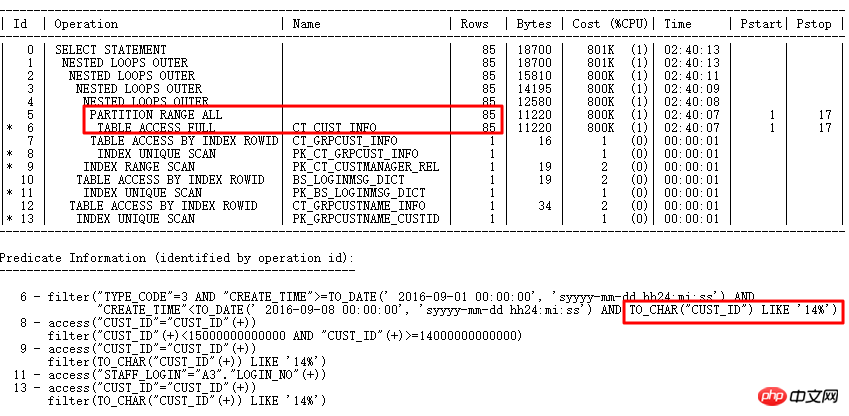
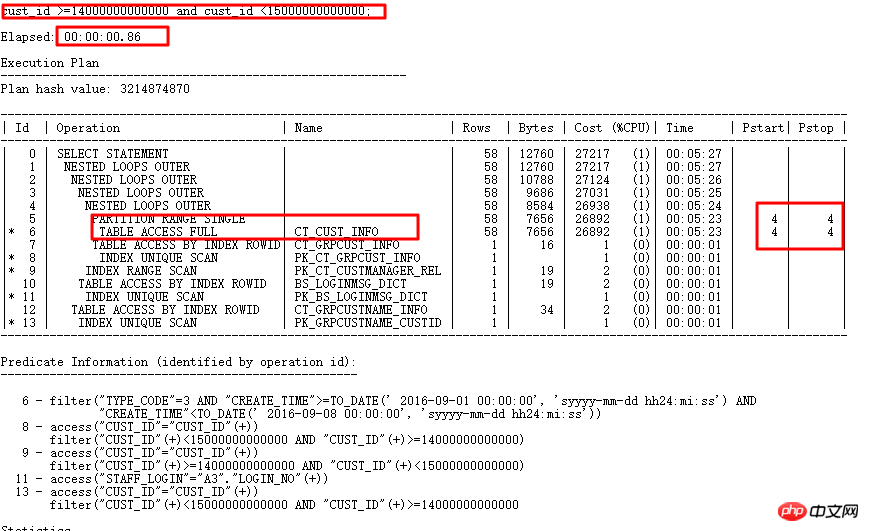
原始SQL執行1688s。透過SQL審核智慧優化準確找到最佳化點—分區列有類型轉換。 優化後0.86s。
SQL審核是新炬資料庫效能管理平台DPM的一個模組,想了解更多關於DPM的信息,可加鄒德裕大師(微信:carydy)交流探討。
今天主要和大家分享了一些Oracle優化器中存在的問題以及常見問題解決方法,當然,優化器問題不僅限於今天分享的,雖然CBO非常強大,並且在12c中有巨大改進,但是,存在的問題也很多,只有平時多累積和觀察,掌握一定的方法,在能在遇到問題事後運籌帷幄,決勝千里。
Q&A
Q1: hash join是不是有排序,可以簡單說hash join的原理嗎?
A1: ORACLE HASH JOIN本身不需要排序,這是差異SORTMERGE JOIN特徵之一。 ORACLE HASH JOIN原理比較複雜,可以參考Jonathan Lewis的Cost-Based Oracle Fundamentals的HASH JOIN部分,針對HASHJOIN最重要的是在原理基礎上搞清楚什麼時候會慢,比如HASH_AREA_SIZE過小,HASH TABLE不能完全放到記憶體中,那麼會發生磁碟HASH運算,再例如上面講的HASH碰撞發生。
Q2: 什麼時候不走索引?
A2: 不走索引情況比較多,首要的原因是統計資料不准導致的,第二原因就是選擇性太低,走索引比走全掃效率更差,還有一個比較常見的就是對索引列進行了運算,導致無法走索引。其它還有很多原因會導致不能走索引,詳細參考MOS文檔:Diagnosing Why a Query is Not Using an Index (文檔 ID 67522.1)。
以上是解決CBO的SQL最佳化問題(圖文詳解)的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















