
如下使用xml.etree.ElementTree模組來解析XML檔。 ElementTree模組中提供了兩個類別用來完成這個目的:
#ElementTree 表示整個XML檔案(一個樹形結構)
Element 表示樹中的一個元素(結點)
我們操作如下XML檔: migapp.xml
#我們操作如下XML檔: migapp.xml
migapp.xml
我們可以透過以下方式導入ElementTree模組: import xml.etree.ElementTree as ET
或也可以只導入parse解析器: from xml.etree.ElementTree import parse
首先需要打開一個xml文件,本地文件使用open函數,如果是互聯網文件,則使用urlopen:
然後對XML進行解析。 1 解析XML檔
1.1  解析根元素
解析根元素
tree = ET.parse(f) root = tree.getroot() print('root.tag =', root.tag) print('root.attrib =', root.attrib)
1.2  解析根的兒子
解析根的兒子
for child in root: # 仅可以解析出root的儿子,不能解析出root的子孙
print(child.tag)
print(child.attrib) # attrib is a dict1.3  透過索引解析根的子孫
透過索引解析根的子孫
print(root[1][1].tag) print(root[1][1].text)
1.4  迭代解析出所有的指定element
迭代解析出所有的指定element
for element in root.iter('environment'):
print(element.attrib)#1.5  幾個有用的方法
幾個有用的方法
# element.findall()解析出指定element的所有儿子
# element.find()解析出指定element的第一个儿子
# element.get()解析出指定element的属性attrib
for environment in root.findall('environment'):
first_variable = environment.find('variable')
print(first_variable.get('name'))#2 修改XML檔假設我們需要為每個text元素新增一個屬性size="50",修改其text為"Benxin Tuzi",新增一個子元素date="2016 /01/16"
for text in root.iter('text'):
text.set('size', '50')
text.text = 'Benxin Tuzi'
text.append(ET.Element('date', attrib={}, text='2016/01/16'))
tree.write('output.xml')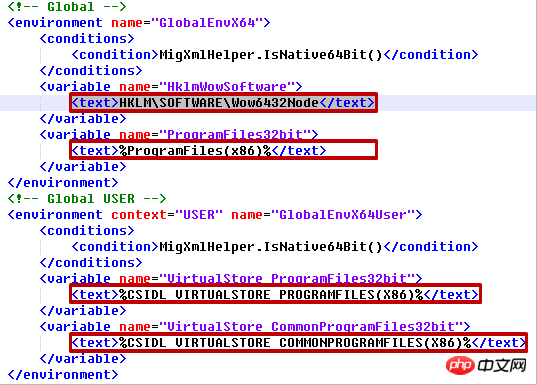 migapp.xml
migapp.xml
##output.xml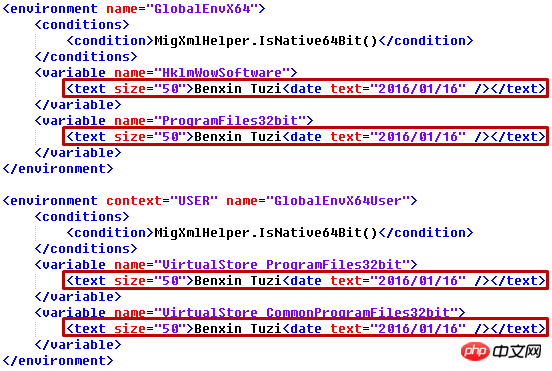 中對應的部分:
中對應的部分:
以上是python解析XML檔實例(圖)的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















