

常用 SQL Server 規範集錦
常見的欄位類型選擇
#
1.字元類型建議採用varchar/nvarchar資料型別
2.金額貨幣建議採用money資料類型
3.科學計數建議採用numeric資料型別
4.自增長標誌建議採用bigint資料型態 (資料量一大,用int型別就裝不下,那以後改造就麻煩了)
5.時間型別建議採用為datetime資料型別
6.禁止使用text、ntext、image老的資料類型
7.禁止使用xml資料型別、varchar(max)、nvarchar(max)
# 約束與索引
每張表必須有主鍵
每張表必須有主鍵,用於強制實體完整性
單表只能有一個主鍵(不允許為空白及重複資料)
盡量使用單一欄位主鍵
不允許使用外鍵
# 外鍵增加了表結構變更及資料遷移的複雜性
# 外鍵對插入,更新的效能有影響,需要檢查主外鍵約束
資料完整性由程式控制
NULL屬性
# 新加的表,所有欄位禁止NULL
#
(新表為什麼不允許NULL?
#
允許NULL值,會增加應用程式的複雜性。你必須得增加特定的邏輯程式碼,以防止各種意外的bug
三值邏輯,所有等號(“=”)的查詢都必須增加isnull的判斷。
Null=Null、Null!=Null、not(Null=Null)、not(Null!=Null)都為unknown,不為true)
舉例來說明一下:
如果表格裡面的資料如圖所示:

# 你想來找查找除了name等於aa的所有數據,然後你就不經意間用了SELECT * FROM NULLTEST WHERE NAME<>’aa’
# 結果發現與預期不一樣,事實上它只查出了name=bb而沒有找出name=NULL的資料記錄
那我們如何找出除了name等於aa的所有數據,只能用ISNULL函數了
# SELECT * FROM NULLTEST WHERE ISNULL(NAME,1)<>’aa’
但是大家可能不知道ISNULL會造成很嚴重的效能瓶頸 ,所以很多時候最好是在應用層面限制使用者的輸入,確保使用者輸入有效的資料再進行查詢。
舊表新加字段,需要允許為NULL(避免全表數據更新 ,長期持鎖導致阻塞)(這個主要是考慮之前表的改造問題)
# 索引設計準則
應該對 WHERE 子句中經常使用的欄位建立索引
# 應該對經常用於連接表的列建立索引
# 應該對 ORDER BY 子句中經常使用的列建立索引
不應該對小型的表(僅使用幾個頁的表)建立索引,這是因為完全表掃描操作可能比使用索引執行的查詢快
單表索引數不超過6個
# 不要給選擇性低的欄位建立單列索引
# 充分利用唯一約束
# 索引包含的欄位不超過5個(包括include列)
不要給選擇性低的欄位建立單列索引
SQL SERVER對索引欄位的選擇性有要求,如果選擇性太低SQL SERVER會放棄使用
不適合建立索引的欄位:性別、0/1、TRUE/FALSE
適合建立索引的欄位:ORDERID、UID等
充分利用唯一索引
唯一索引給SQL Server提供了確保某一列絕對沒有重複值的信息,當查詢分析器透過唯一索引查找到一條記錄則會立刻退出,不會繼續查找索引
表索引數不超過6個
表索引數不超過6個(這個規則只是攜程DBA經過試驗之後製定的。。)
- # 索引過多不僅會增加編譯時間,也會影響資料庫選擇最佳執行計劃###### SQL查詢############ 禁止在資料庫做複雜運算###
# 禁止使用SELECT *
# 禁止在索引列上使用函數或計算
禁止使用遊標
# 禁止使用觸發器
# 禁止在查詢中指定索引
# 變數/參數/關聯欄位類型必須與欄位類型一致
# 參數化查詢
# 限制JOIN個數字
# 限制SQL語句長度及IN子句個數
# 盡量避免大事務操作
關閉影響的行計數資訊返回
# 除非必要SELECT語句都必須加上NOLOCK
# 使用UNION ALL取代UNION
# 查詢大量資料使用分頁或TOP
# 遞歸查詢層級限制
# NOT EXISTS替代NOT IN
# 臨時表與表格變數
# 使用本地變數選擇中庸執行計劃
# 盡量避免使用OR運算子
# 增加交易異常處理機制
# 輸出列使用二段式命名格式
禁止在資料庫做複雜運算
# XML解析
字串相似性比較
# 字串搜尋(Charindex)
# 複雜運算在程式端完成
禁止使用SELECT *
減少記憶體消耗和網路頻寬
# 給查詢最佳化器有機會從索引讀取所需的欄位
# 表結構變化時容易引起查詢出錯
禁止在索引列上使用函數或計算
# 禁止在索引列上使用函數或計算
在where子句中,如果索引是函數的一部分,優化器將不再使用索引而使用全表掃描
假設在欄位Col1上建有一個索引,則下列場景將無法使用到索引:
# ABS[Col1]=1
[Col1]+1>9
# 再舉例說明一下

# 像上面這樣的查詢,將無法用到O_OrderProcess表上的PrintTime索引,所以我們應用使用如下所示的查詢SQL
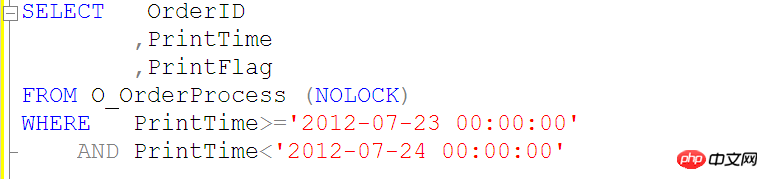
# 禁止在索引列上使用函數或計算
假設在字段Col1上建有一個索引,則下列場景將可使用到索引:
# [Col1]=3.14
# [Col1]>100
# [Col1] BETWEEN 0 AND 99
[Col1] LIKE ‘abc%’
# [Col1] IN(2,3,5,7)
LIKE查詢的索引問題
#
1.[Col1] like “abc%” –index seek 這個就用到了索引查詢
2.[Col1] like “%abc%” –index scan 而這個就並未用到索引查詢
3.[Col1] like “%abc” –index scan 這個也並未用到索引查詢
我想從上而三個例子中,大家應該明白,最好不要在LIKE條件前面用模糊匹配,否則就用不到索引查詢。
禁止使用遊標
關聯式資料庫適合集合操作,也就是對由WHERE子句和選擇列所確定的結果集作集合操作,遊標是提供的一個非集合操作的途徑。一般情況下,遊標實現的功能往往相當於客戶端的一個循環實現的功能。
遊標是把結果集放在伺服器內存,並透過循環一條一條處理記錄,對資料庫資源(特別是內存和鎖定資源)的消耗是非常大的。
(再加上游標真心比較複雜,挺不好用的,盡量少用吧)
禁止使用觸發器
觸發器對應用不透明(應用層面都不知道會何時觸發觸發器,發生也也不知道,感覺莫名…)
# 禁止在查詢裡指定索引
# With(index=XXX)( 在查詢裡我們指定索引一般都用With(index=XXX) )
隨著資料的變化查詢語句指定的索引效能可能並不最佳
# 索引對應用程式應是透明的,如指定的索引被刪除將會導致查詢報錯,不利於排障
# 新建的索引無法被應用程式立即使用,必須透過發布程式碼才能生效
變數/參數/關聯欄位類型必須與欄位類型一致(這是我之前不太關注的)
# 避免型別轉換額外消耗的CPU,造成的大表scan尤為嚴重
#
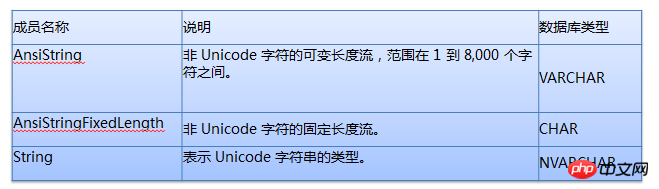
#
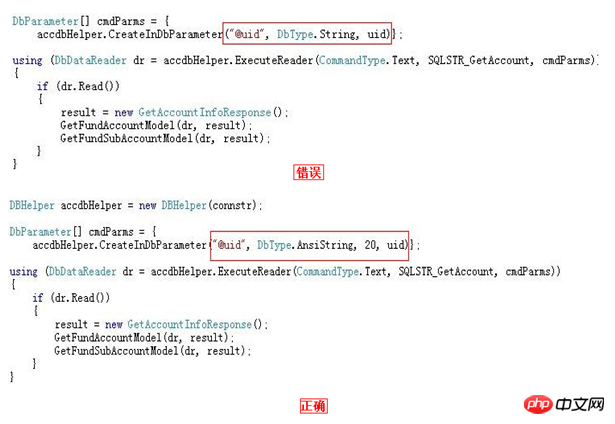
# 看了上面這兩張圖,我想我不用解釋說明,大家都應該已經清楚了吧。
如果資料庫欄位類型為VARCHAR,在應用裡面最好類型指定為AnsiString並明確指定其長度
如果資料庫欄位類型為CHAR,在應用程式裡面最好型別指定為AnsiStringFixedLength並明確指定其長度
# 如果資料庫欄位類型為NVARCHAR,在應用裡面最好型別指定為String並明確指定其長度
參數化查詢
以下方式可以對查詢SQL進行參數化:
sp_executesql
## Prepared Queries
Stored procedures 用圖來說明一下,哈哈。
用圖來說明一下,哈哈。

#
- # 限制JOIN個數
-
單一SQL語句的表JOIN個數字不能超過5個
- #
過多的JOIN個數會導致查詢分析器走錯執行計劃
- 盡量避免大事務操作
-
只在資料需要更新時開始事務,減少資源鎖定持有時間
- #
增加交易異常擷取預處理機制
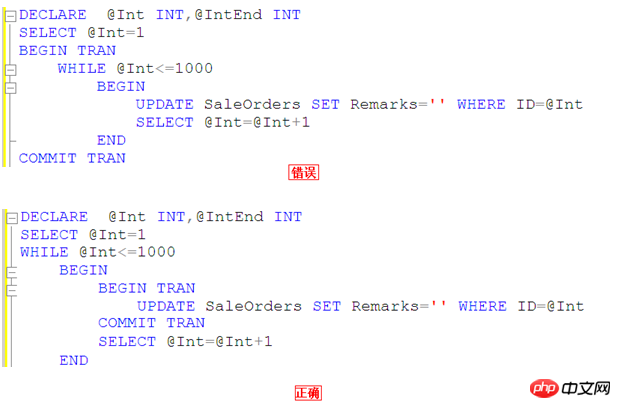 用圖來說明一下
用圖來說明一下
# 也就是說我們不應該在1000行資料都更新完成之後再commit tran,你想想你在更新這一千行資料的時候是不是獨佔資源導致其它事務無法處理。 關閉影響的行計數資訊返回# 在SQL語句中顯示設定Set Nocount On,取消影響的行計數資訊返回,減少網路流量 除非必要SELECT語句都必須加上NOLOCK 除非必要,盡量讓所有的select語句都必須加上NOLOCK 指定允許髒讀。不發布共享鎖來阻止其他事務修改目前事務讀取的數據,其他事務設 置的排他鎖不會阻礙當前事務讀取鎖定數據。允許髒讀可能產生較多的並發操作,但其代價是讀取以後會被其他交易回滾的資料修改。這可能會使您的交易出錯,向使用者顯示從未提交過的數據,或導致使用者兩次看到記錄(或根本看不到記錄) 使用UNION ALL替換UNION 使用UNION ALL取代UNION UNION會對SQL結果集去重排序,增加CPU、記憶體等消耗# 查詢大量資料使用分頁或TOP 合理限制記錄回傳數,避免IO、網路頻寬出現瓶頸 遞歸查詢層次限制# 使用 MAXRECURSION 來防止不合理的遞歸 CTE 進入無限循環
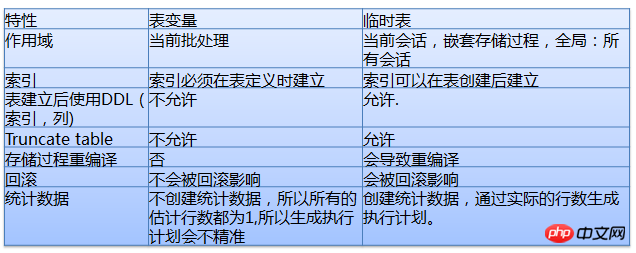 #
臨時表與表格變數
#
臨時表與表格變數
#
# 使用本地變數選擇中庸執行計劃 在預存程序或查詢中,存取了一張資料分佈很不平均的表格,這往往會讓預存程序或查詢使用了次優甚至於較差的執行計劃上,造成High CPU及大量IO Read等問題,使用本地變數防止走錯執行計劃。 ###### 採用本地變數的方式,SQL在編譯的時候是不知道這個本地變數的值,這時候SQL會根據表格裡資料的一般分佈,「猜測」一個回傳值。不管使用者在呼叫預存程序或語句的時候代入的變數值是多少,產生的計畫都是一樣的。這樣的計劃一般會比較中庸一些,不一定是最優的計劃,但一般也不會是最差的計劃###
如果查詢中本地變數使用了不等式運算符,查詢分析器使用了一個簡單的 30% 的運算式來預估
Estimated Rows =(Total Rows * 30)/100
如果查詢中本地變數使用了等式運算符,則查詢分析器使用:精確度 * 表記錄總數來預估
Estimated Rows = Density * Total Rows
盡量避免使用OR運算子
對於OR運算符,通常會使用全表掃描,考慮分解成多個查詢用UNION/UNION ALL來實現,這裡要確認查詢能走到索引並返回較少的結果集
增加事務異常處理機制
#
應用程式做好意外處理,及時做Rollback。
設定連線屬性 “set xact_abort on”
輸出列使用二段式命名格式
二段式命名格式:表名.欄位名稱
# 有JOIN關係的TSQL,字段必須指明字段是屬於哪個表的,否則未來表結構變更後,有可能發生Ambiguous column name的程式相容錯誤
# 架構設計
讀寫分離
# schema解耦
# 資料生命週期
# 讀寫分離
設計之初就考慮讀寫分離,即使讀寫同一個函式庫,有利於快速擴容
以上是常用 SQL Server 規範集錦的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 microsoft sql server是什麼軟體
Feb 28, 2023 pm 03:00 PM
microsoft sql server是什麼軟體
Feb 28, 2023 pm 03:00 PM
microsoft sql server是Microsoft公司推出的關係型資料庫管理系統,是一個全面的資料庫平台,使用整合的商業智慧(BI)工具提供了企業級的資料管理,具有使用方便可伸縮性好與相關軟體整合程度高等優點。 SQL Server資料庫引擎為關聯式資料和結構化資料提供了更安全可靠的儲存功能,使用戶可以建置和管理用於業務的高可用和高效能的資料應用程式。
 如何使用PDO連線到Microsoft SQL Server資料庫
Jul 29, 2023 pm 01:49 PM
如何使用PDO連線到Microsoft SQL Server資料庫
Jul 29, 2023 pm 01:49 PM
如何使用PDO連接到MicrosoftSQLServer資料庫介紹:PDO(PHPDataObjects)是PHP提供的一個存取資料庫的統一介面。它提供了許多優點,例如實作了資料庫的抽象層,可以方便地切換不同的資料庫類型,而不需要修改大量的程式碼。本文將介紹如何使用PDO連接到MicrosoftSQLServer資料庫,並提供一些相關程式碼範例。步驟
 PHP和SQL Server資料庫開發
Jun 20, 2023 pm 10:38 PM
PHP和SQL Server資料庫開發
Jun 20, 2023 pm 10:38 PM
隨著互聯網的普及,網站和應用程式的開發成為了許多企業和個人的主要業務。而PHP和SQLServer資料庫則是其中非常重要的兩個工具。 PHP是一種伺服器端腳本語言,可用於開發動態網站;SQLServer是微軟公司開發的關聯式資料庫管理系統,具有廣泛的應用場景。在本文中,我們將討論PHP和SQLServer的開發,以及它們的優缺點和應用方法。首先,讓我們
 淺析PHP連接SQL Server的五種方法
Mar 21, 2023 pm 04:32 PM
淺析PHP連接SQL Server的五種方法
Mar 21, 2023 pm 04:32 PM
在Web開發中,PHP與MySQL的結合是非常常見的。但是,在某些情況下,我們需要連接其他類型的資料庫,例如SQL Server。在本文中,我們將介紹使用PHP連接SQL Server的五種不同方法。
 SQL Server還是MySQL?最新研究揭秘最佳資料庫選擇。
Sep 08, 2023 pm 04:34 PM
SQL Server還是MySQL?最新研究揭秘最佳資料庫選擇。
Sep 08, 2023 pm 04:34 PM
SQLServer還是MySQL?最新研究揭秘最佳資料庫選擇近年來,隨著網路和大數據的快速發展,資料庫的選擇成為了企業和開發者面臨的重要議題。在眾多資料庫中,SQLServer和MySQL作為兩個最常見且廣泛使用的關聯式資料庫,備受爭議。那麼,在SQLServer和MySQL之間,到底該選擇哪一個呢?最新的研究為我們揭示了這個問題。首先,讓
 SQL Server與MySQL比較:哪個資料庫更適合高可用性架構?
Sep 10, 2023 pm 01:39 PM
SQL Server與MySQL比較:哪個資料庫更適合高可用性架構?
Sep 10, 2023 pm 01:39 PM
SQLServer與MySQL比較:哪個資料庫更適合高可用性架構?在當今的數據驅動世界中,高可用性是建立可靠和穩定係統的必要條件之一。資料庫作為資料儲存和管理的核心元件,其高可用性對於企業的業務運作至關重要。在眾多的資料庫中,SQLServer和MySQL是常見的選擇。那麼在高可用性架構方面,究竟哪個資料庫比較適合呢?本文將對二者進行對比,並給予一些建議。
 SQL Server和MySQL比較:哪個比較適合大規模資料處理?
Sep 09, 2023 am 09:36 AM
SQL Server和MySQL比較:哪個比較適合大規模資料處理?
Sep 09, 2023 am 09:36 AM
SQLServer和MySQL是目前兩個非常流行的關係型資料庫管理系統(RDBMS)。它們都是用於儲存和管理大規模資料的強大工具。然而,它們在處理大規模數據時有一些不同之處。本文將對SQLServer和MySQL進行比較,重點在於它們在大規模資料處理方面的適用性。首先,讓我們來了解一下SQLServer和MySQL的基本特性。 SQLServer是由微軟
 SQL Server與MySQL較量,如何選擇最佳資料庫方案?
Sep 10, 2023 am 08:07 AM
SQL Server與MySQL較量,如何選擇最佳資料庫方案?
Sep 10, 2023 am 08:07 AM
隨著網路的不斷發展,資料庫的選擇愈發重要。在眾多的資料庫中,SQLServer和MySQL是兩個備受矚目的選項。 SQLServer是微軟公司開發的關聯式資料庫管理系統,而MySQL則是一種開源的關係型資料庫管理系統。那麼在SQLServer和MySQL之間如何選擇最佳的資料庫方案呢?首先,我們可以從效能方面比較這兩個資料庫。 SQLServer正在處理
