

python爬蟲入門(1)--快速理解HTTP協定

http協定是網際網路裡面最重要,最基礎的協定之一,我們的爬蟲需要經常和http協定打交道。以下這篇文章主要給大家介紹了關於python爬蟲入門之快速理解HTTP協議的相關資料,文中介紹的非常詳細,需要的朋友可以參考借鑒,下面來一起看看吧。
前言
爬蟲的基本原理是模擬瀏覽器進行HTTP 請求,並理解HTTP 協定是寫爬蟲的必備基礎,招募網站的爬蟲崗位也赫然寫著熟練HTTP協議規範,寫爬蟲還不得不先從HTTP協議開始講起
HTTP協議是什麼?
你瀏覽的每一個網頁都是基於HTTP 協定呈現的,HTTP 協定是網路應用中,客戶端(瀏覽器)與伺服器之間進行資料通訊的一種協定。協定中規定了客戶端應該按照什麼格式給伺服器發送請求,同時也約定了服務端回傳的回應結果應該是什麼格式。
只要大家都按照協定規定方式發起請求和回傳回應結果,任何人都可以基於HTTP協定實作自己的Web客戶端(瀏覽器、爬蟲)和Web伺服器(Nginx、Apache等)。
HTTP 協定本身是非常簡單的。它規定,只能由客戶端主動發起請求,伺服器接收請求處理後回傳回應結果,同時 HTTP 是無狀態的協議,協定本身不記錄客戶端的歷史請求記錄。

HTTP 協定是如何規定請求格式和回應格式的呢?換言之,客戶端按照什麼格式才能正確發起 HTTP 請求呢?服務端按照什麼格式回傳回應結果客戶端才能正確解析?
HTTP 請求
HTTP 請求由3部分組成,分別是請求行、請求首部、請求體,首部和請求體是可選的,並不是每個請求都需要的。

請求行
#請求行是每個請求必不可少的部分,它由3部分組成,分別是請求方法(method)、請求URL(URI)、HTTP協定版本,以空格隔開。
HTTP協定中最常使用的請求方法有:GET、POST、PUT、DELETE。 GET 方法用於從伺服器取得資源,90%的爬蟲都是基於GET請求抓取資料。
請求 URL 是指資源所在伺服器的路徑位址,例如上圖的範例表示客戶端想要取得 index.html 這個資源,它的路徑在伺服器 foofish.net 的根目錄(/)下面。
請求首部
因為請求行所攜帶的資訊量非常有限,以至於客戶端還有很多想向伺服器要說的事情不得不放在請求首部(Header),請求首部用於給伺服器提供一些額外的信息,例如User-Agent 用來表明客戶端的身份,讓伺服器知道你是來自瀏覽器的請求還是爬蟲,是來自Chrome瀏覽器還是FireFox。 HTTP/1.1 規定了47種首部欄位類型。 HTTP首部欄位的格式很像 Python 中的字典類型,由鍵值對組成,中間用冒號隔開。例如:
User-Agent: Mozilla/5.0
因為客戶端發送請求時,發送的資料(封包)是由字串構成的,為了區分請求首部的結尾和請求體的開始,用一個空行來表示,遇到空行時,就表示這是首部的結尾,請求體的開始。
請求體
請求體是用戶端提交給伺服器的真正內容,例如使用者登入時的需要用的使用者名稱和密碼,例如文件上傳的數據,例如註冊用戶資訊時提交的表單資訊。
現在我們用Python 提供的最原始API socket 模組來模擬向伺服器發起一個HTTP 請求
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
# 1. 与服务器建立连接
s.connect(("www.seriot.ch", 80))
# 2. 构建请求行,请求资源是 index.php
request_line = b"GET /index.php HTTP/1.1"
# 3. 构建请求首部,指定主机名
headers = b"Host: seriot.ch"
# 4. 用空行标记请求首部的结束位置
blank_line = b"\r\n"
# 请求行、首部、空行这3部分内容用换行符分隔,组成一个请求报文字符串
# 发送给服务器
message = b"\r\n".join([request_line, headers, blank_line])
s.send(message)
# 服务器返回的响应内容稍后进行分析
response = s.recv(1024)
print(response)HTTP 回應
#服務端接收請求並處理後,返回回應內容給客戶端,同樣地,回應內容也必須遵循固定的格式瀏覽器才能正確解析。 HTTP 回應也由3部分組成,分別是:回應行、回應首部、回應體,與 HTTP 的請求格式是相對應的。
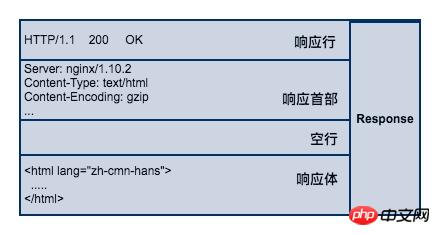
响应行
响应行同样也是3部分组成,由服务端支持的 HTTP 协议版本号、状态码、以及对状态码的简短原因描述组成。
状态码是响应行中很重要的一个字段。通过状态码,客户端可以知道服务器是否正常处理的请求。如果状态码是200,说明客户端的请求处理成功,如果是500,说明服务器处理请求的时候出现了异常。404 表示请求的资源在服务器找不到。除此之外,HTTP 协议还很定义了很多其他的状态码,不过它不是本文的讨论范围。
响应首部
响应首部和请求首部类似,用于对响应内容的补充,在首部里面可以告知客户端响应体的数据类型是什么?响应内容返回的时间是什么时候,响应体是否压缩了,响应体最后一次修改的时间。
响应体
响应体(body)是服务器返回的真正内容,它可以是一个HTML页面,或者是一张图片、一段视频等等。
我们继续沿用前面那个例子来看看服务器返回的响应结果是什么?因为我只接收了前1024个字节,所以有一部分响应内容是看不到的。
b'HTTP/1.1 200 OK\r\n Date: Tue, 04 Apr 2017 16:22:35 GMT\r\n Server: Apache\r\n Expires: Thu, 19 Nov 1981 08:52:00 GMT\r\n Set-Cookie: PHPSESSID=66bea0a1f7cb572584745f9ce6984b7e; path=/\r\n Transfer-Encoding: chunked\r\n Content-Type: text/html; charset=UTF-8\r\n\r\n118d\r\n <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">\n\n <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">\n <head>\n\t <meta http-equiv="Content-Type" content="text/html;charset=iso-8859-1" /> \n\t <meta http-equiv="content-language" content="en" />\n\t ... </html>
从结果来看,它与协议中规范的格式是一样的,第一行是响应行,状态码是200,表明请求成功。第二部分是响应首部信息,由多个首部组成,有服务器返回响应的时间,Cookie信息等等。第三部分就是真正的响应体 HTML 文本。
至此,你应该对 HTTP 协议有一个总体的认识了,爬虫的行为本质上就是模拟浏览器发送HTTP请求,所以要想在爬虫领域深耕细作,理解 HTTP 协议是必须的。
【相关推荐】
1. python爬虫入门(4)--详解HTML文本的解析库BeautifulSoup
2. python爬虫入门(3)--利用requests构建知乎API
3. python爬虫入门(2)--HTTP库requests
以上是python爬蟲入門(1)--快速理解HTTP協定的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP主要是過程式編程,但也支持面向對象編程(OOP);Python支持多種範式,包括OOP、函數式和過程式編程。 PHP適合web開發,Python適用於多種應用,如數據分析和機器學習。
 在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
PHP適合網頁開發和快速原型開發,Python適用於數據科學和機器學習。 1.PHP用於動態網頁開發,語法簡單,適合快速開發。 2.Python語法簡潔,適用於多領域,庫生態系統強大。
 Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP起源於1994年,由RasmusLerdorf開發,最初用於跟踪網站訪問者,逐漸演變為服務器端腳本語言,廣泛應用於網頁開發。 Python由GuidovanRossum於1980年代末開發,1991年首次發布,強調代碼可讀性和簡潔性,適用於科學計算、數據分析等領域。
 vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
VS Code可以在Windows 8上運行,但體驗可能不佳。首先確保系統已更新到最新補丁,然後下載與系統架構匹配的VS Code安裝包,按照提示安裝。安裝後,注意某些擴展程序可能與Windows 8不兼容,需要尋找替代擴展或在虛擬機中使用更新的Windows系統。安裝必要的擴展,檢查是否正常工作。儘管VS Code在Windows 8上可行,但建議升級到更新的Windows系統以獲得更好的開發體驗和安全保障。
 visual studio code 可以用於 python 嗎
Apr 15, 2025 pm 08:18 PM
visual studio code 可以用於 python 嗎
Apr 15, 2025 pm 08:18 PM
VS Code 可用於編寫 Python,並提供許多功能,使其成為開發 Python 應用程序的理想工具。它允許用戶:安裝 Python 擴展,以獲得代碼補全、語法高亮和調試等功能。使用調試器逐步跟踪代碼,查找和修復錯誤。集成 Git,進行版本控制。使用代碼格式化工具,保持代碼一致性。使用 Linting 工具,提前發現潛在問題。
 notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
在 Notepad 中運行 Python 代碼需要安裝 Python 可執行文件和 NppExec 插件。安裝 Python 並為其添加 PATH 後,在 NppExec 插件中配置命令為“python”、參數為“{CURRENT_DIRECTORY}{FILE_NAME}”,即可在 Notepad 中通過快捷鍵“F6”運行 Python 代碼。
 sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
在 Sublime Text 中運行 Python 代碼,需先安裝 Python 插件,再創建 .py 文件並編寫代碼,最後按 Ctrl B 運行代碼,輸出會在控制台中顯示。
