

電腦程式的思考邏輯 (89) - 正規表示式 (中)
上节介绍了正则表达式的语法,本节介绍相关的Java API。
正则表达式相关的类位于包java.util.regex下,有两个主要的类,一个是Pattern,另一个是Matcher。Pattern表示正则表达式对象,它与要处理的具体字符串无关。Matcher表示一个匹配,它将正则表达式应用于一个具体字符串,通过它对字符串进行处理。
字符串类String也是一个重要的类,我们在29节专门介绍过String,其中提到,它有一些方法,接受的参数不是普通的字符串,而是正则表达式。此外,正则表达式在Java中是需要先以字符串形式表示的。
下面,我们先来介绍如何表示正则表达式,然后探讨如何利用它实现一些常见的文本处理任务,包括切分、验证、查找、和替换。
表示正则表达式
转义符 '\'
正则表达式由元字符和普通字符组成,字符'\'是一个元字符,要在正则表达式中表示'\'本身,需要使用它转义,即'\\'。
在Java中,没有什么特殊的语法能直接表示正则表达式,需要用字符串表示,而在字符串中,'\'也是一个元字符,为了在字符串中表示正则表达式的'\',就需要使用两个'\',即'\\',而要匹配'\'本身,就需要四个'\',即'\\\\',比如说,如下表达式:
<(\w+)>(.*)</\1>
对应的字符串表示就是:
"<(\\w+)>(.*)</\\1>"
一个简单规则是,正则表达式中的任何一个'\',在字符串中,需要替换为两个'\'。
Pattern对象
字符串表示的正则表达式可以被编译为一个Pattern对象,比如:
String regex = "<(\\w+)>(.*)</\\1>"; Pattern pattern = Pattern.compile(regex);
Pattern是正则表达式的面向对象表示,所谓编译,简单理解就是将字符串表示为了一个内部结构,这个结构是一个有穷自动机,关于有穷自动机的理论比较深入,我们就不探讨了。
编译有一定的成本,而且Pattern对象只与正则表达式有关,与要处理的具体文本无关,它可以安全地被多线程共享,所以,在使用同一个正则表达式处理多个文本时,应该尽量重用同一个Pattern对象,避免重复编译。
匹配模式
Pattern的compile方法接受一个额外参数,可以指定匹配模式:
public static Pattern compile(String regex, int flags)
上节,我们介绍过三种匹配模式:单行模式(点号模式)、多行模式和大小写无关模式,它们对应的常量分别为:Pattern.DOTALL,Pattern.MULTILINE和Pattern.CASE_INSENSITIVE,多个模式可以一起使用,通过'|'连起来即可,如下所示:
Pattern.compile(regex, Pattern.CASE_INSENSITIVE | Pattern.DOTALL)
还有一个模式Pattern.LITERAL,在此模式下,正则表达式字符串中的元字符将失去特殊含义,被看做普通字符。Pattern有一个静态方法:
public static String quote(String s)
quote()的目的是类似的,它将s中的字符都看作普通字符。我们在上节介绍过\Q和\E,\Q和\E之间的字符会被视为普通字符。quote()基本上就是在字符串s的前后加了\Q和\E,比如,如果s为"\\d{6}",则quote()的返回值就是"\\Q\\d{6}\\E"。
切分
简单情况
文本处理的一个常见需求是根据分隔符切分字符串,比如在处理CSV文件时,按逗号分隔每个字段,这个需求听上去很容易满足,因为String类有如下方法:
public String[] split(String regex)
比如:
String str = "abc,def,hello";
String[] fields = str.split(",");
System.out.println("field num: "+fields.length);
System.out.println(Arrays.toString(fields));输出为:
field num: 3[abc, def, hello]
不过,有一些重要的细节,我们需要注意。
转义元字符
split将参数regex看做正则表达式,而不是普通的字符,如果分隔符是元字符,比如. $ | ( ) [ { ^ ? * + \,就需要转义,比如按点号'.'分隔,就需要写为:
String[] fields = str.split("\\.");如果分隔符是用户指定的,程序事先不知道,可以通过Pattern.quote()将其看做普通字符串。
将多个字符用作分隔符
既然是正则表达式,分隔符就不一定是一个字符,比如,可以将一个或多个空白字符或点号作为分隔符,如下所示:
String str = "abc def hello.\n world";
String[] fields = str.split("[\\s.]+");fields内容为:
[abc, def, hello, world]
空白字符串
需要说明的是,尾部的空白字符串不会包含在返回的结果数组中,但头部和中间的空白字符串会被包含在内,比如:
String str = ",abc,,def,,";
String[] fields = str.split(",");
System.out.println("field num: "+fields.length);
System.out.println(Arrays.toString(fields));输出为:
field num: 4[, abc, , def]
找不到分隔符
如果字符串中找不到匹配regex的分隔符,返回数组长度为1,元素为原字符串。
切分数目限制
split方法接受一个额外的参数limit,用于限定切分的数目:
public String[] split(String regex, int limit)
不带limit参数的split,其limit相当于0。关于limit的含义,我们通过一个例子说明下,比如字符串是"a:b:c:",分隔符是":",在limit为不同值的情况下,其返回数组如下表所示:
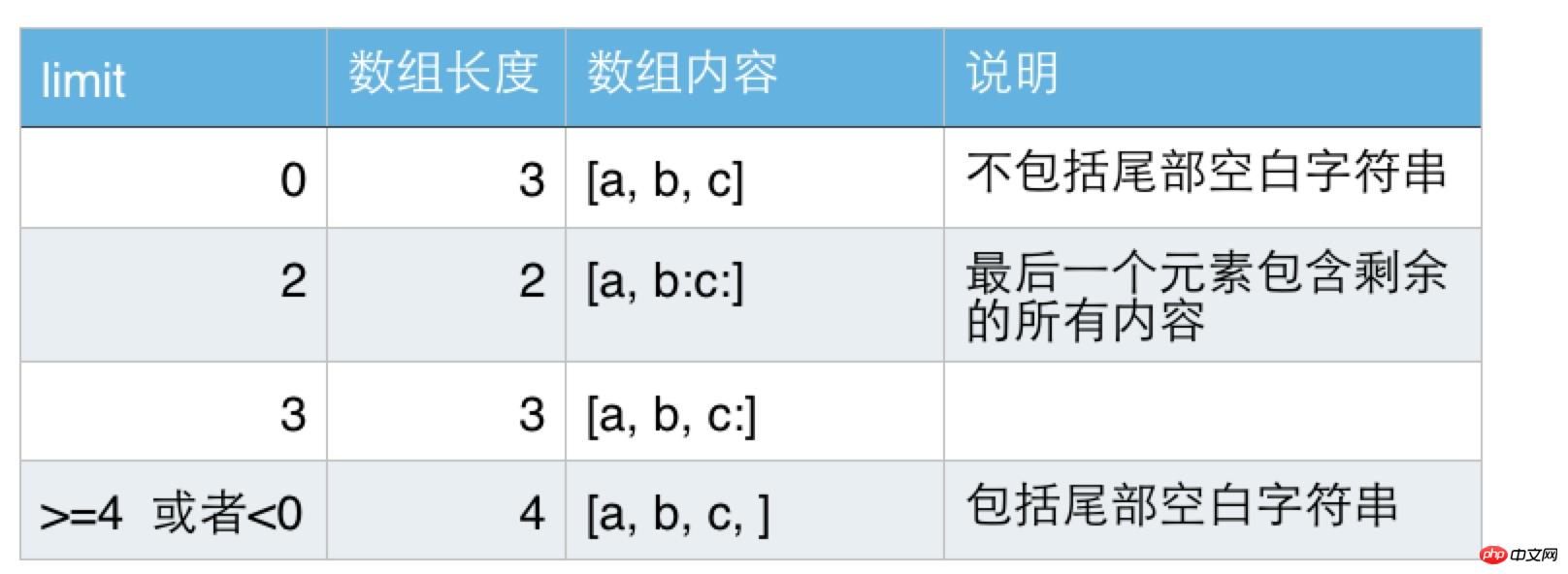
Pattern的split方法
Pattern也有两个split方法,与String方法的定义类似:
public String[] split(CharSequence input)public String[] split(CharSequence input, int limit)
与String方法的区别是:
Pattern接受的参数是CharSequence,更为通用,我们知道String, StringBuilder, StringBuffer, CharBuffer等都实现了该接口;
如果regex长度大于1或包含元字符,String的split方法会先将regex编译为Pattern对象,再调用Pattern的split方法,这时,为避免重复编译,应该优先采用Pattern的方法;
如果regex就是一个字符且不是元字符,String的split方法会采用更为简单高效的实现,所以,这时,应该优先采用String的split方法。
验证
验证就是检验输入文本是否完整匹配预定义的正则表达式,经常用于检验用户的输入是否合法。
String有如下方法:
public boolean matches(String regex)
比如:
String regex = "\\d{8}";
String str = "12345678";
System.out.println(str.matches(regex));检查输入是否是8位数字,输出为true。
String的matches实际调用的是Pattern的如下方法:
public static boolean matches(String regex, CharSequence input)
这是一个静态方法,它的代码为:
public static boolean matches(String regex, CharSequence input) {
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(input);return m.matches();
}就是先调用compile编译regex为Pattern对象,再调用Pattern的matcher方法生成一个匹配对象Matcher,Matcher的matches()返回是否完整匹配。
查找
查找就是在文本中寻找匹配正则表达式的子字符串,看个例子:
public static void find(){
String regex = "\\d{4}-\\d{2}-\\d{2}";
Pattern pattern = Pattern.compile(regex);
String str = "today is 2017-06-02, yesterday is 2017-06-01";
Matcher matcher = pattern.matcher(str);while(matcher.find()){
System.out.println("find "+matcher.group()+" position: "+matcher.start()+"-"+matcher.end());
}
}代码寻找所有类似"2017-06-02"这种格式的日期,输出为:
find 2017-06-02 position: 9-19find 2017-06-01 position: 34-44
Matcher的内部记录有一个位置,起始为0,find()方法从这个位置查找匹配正则表达式的子字符串,找到后,返回true,并更新这个内部位置,匹配到的子字符串信息可以通过如下方法获取:
//匹配到的完整子字符串public String group()//子字符串在整个字符串中的起始位置public int start()//子字符串在整个字符串中的结束位置加1public int end()
group()其实调用的是group(0),表示获取匹配的第0个分组的内容。我们在上节介绍过捕获分组的概念,分组0是一个特殊分组,表示匹配的整个子字符串。除了分组0,Matcher还有如下方法,获取分组的更多信息:
//分组个数public int groupCount()//分组编号为group的内容public String group(int group)//分组命名为name的内容public String group(String name)//分组编号为group的起始位置public int start(int group)//分组编号为group的结束位置加1public int end(int group)
比如:
public static void findGroup() {
String regex = "(\\d{4})-(\\d{2})-(\\d{2})";
Pattern pattern = Pattern.compile(regex);
String str = "today is 2017-06-02, yesterday is 2017-06-01";
Matcher matcher = pattern.matcher(str);while (matcher.find()) {
System.out.println("year:" + matcher.group(1)+ ",month:" + matcher.group(2)+ ",day:" + matcher.group(3));
}
}输出为:
year:2017,month:06,day:02year:2017,month:06,day:01
替换
replaceAll和replaceFirst
查找到子字符串后,一个常见的后续操作是替换。String有多个替换方法:
public String replace(char oldChar, char newChar)public String replace(CharSequence target, CharSequence replacement)public String replaceAll(String regex, String replacement)public String replaceFirst(String regex, String replacement)
第一个replace方法操作的是单个字符,第二个是CharSequence,它们都是将参数看做普通字符。而replaceAll和replaceFirst则将参数regex看做正则表达式,它们的区别是,replaceAll替换所有找到的子字符串,而replaceFirst则只替换第一个找到的,看个简单的例子,将字符串中的多个连续空白字符替换为一个:
String regex = "\\s+"; String str = "hello world good"; System.out.println(str.replaceAll(regex, " "));
输出为:
hello world good
在replaceAll和replaceFirst中,参数replacement也不是被看做普通的字符串,可以使用美元符号加数字的形式,比如$1,引用捕获分组,我们看个例子:
String regex = "(\\d{4})-(\\d{2})-(\\d{2})";
String str = "today is 2017-06-02.";
System.out.println(str.replaceFirst(regex, "$1/$2/$3"));输出为:
today is 2017/06/02.
这个例子将找到的日期字符串的格式进行了转换。所以,字符'$'在replacement中是元字符,如果需要替换为字符'$'本身,需要使用转义,看个例子:
String regex = "#"; String str = "#this is a test"; System.out.println(str.replaceAll(regex, "\\$"));
如果替换字符串是用户提供的,为避免元字符的的干扰,可以使用Matcher的如下静态方法将其视为普通字符串:
public static String quoteReplacement(String s)
String的replaceAll和replaceFirst调用的其实是Pattern和Matcher中的方法,比如,replaceAll的代码为:
public String replaceAll(String regex, String replacement) {return Pattern.compile(regex).matcher(this).replaceAll(replacement);
}边查找边替换
replaceAll和replaceFirst都定义在Matcher中,除了一次性的替换操作外,Matcher还定义了边查找、边替换的方法:
public Matcher appendReplacement(StringBuffer sb, String replacement)public StringBuffer appendTail(StringBuffer sb)
这两个方法用于和find()一起使用,我们先看个例子:
public static void replaceCat() {
Pattern p = Pattern.compile("cat");
Matcher m = p.matcher("one cat, two cat, three cat");
StringBuffer sb = new StringBuffer();int foundNum = 0;while (m.find()) {
m.appendReplacement(sb, "dog");
foundNum++;if (foundNum == 2) {break;
}
}
m.appendTail(sb);
System.out.println(sb.toString());
}在这个例子中,我们将前两个"cat"替换为了"dog",其他"cat"不变,输出为:
one dog, two dog, three cat
StringBuffer类型的变量sb存放最终的替换结果,Matcher内部除了有一个查找位置,还有一个append位置,初始为0,当找到一个匹配的子字符串后,appendReplacement()做了三件事情:
将append位置到当前匹配之前的子字符串append到sb中,在第一次操作中,为"one ",第二次为", two ";
将替换字符串append到sb中;
更新append位置为当前匹配之后的位置。
appendTail将append位置之后所有的字符append到sb中。
模板引擎
利用Matcher的这几个方法,我们可以实现一个简单的模板引擎,模板是一个字符串,中间有一些变量,以{name}表示,如下例所示:
String template = "Hi {name}, your code is {code}.";这里,模板字符串中有两个变量,一个是name,另一个是code。变量的实际值通过Map提供,变量名称对应Map中的键,模板引擎的任务就是接受模板和Map作为参数,返回替换变量后的字符串,示例实现为:
private static Pattern templatePattern = Pattern.compile("\\{(\\w+)\\}");public static String templateEngine(String template, Map<String, Object> params) {
StringBuffer sb = new StringBuffer();
Matcher matcher = templatePattern.matcher(template);while (matcher.find()) {
String key = matcher.group(1);
Object value = params.get(key);
matcher.appendReplacement(sb, value != null ?Matcher.quoteReplacement(value.toString()) : "");
}
matcher.appendTail(sb);return sb.toString();
}代码寻找所有的模板变量,正则表达式为:
\{(\w+)\}'{'是元字符,所以要转义,\w+表示变量名,为便于引用,加了括号,可以通过分组1引用变量名。
使用该模板引擎的示例代码为:
public static void templateDemo() {
String template = "Hi {name}, your code is {code}.";
Map params = new HashMap();
params.put("name", "老马");
params.put("code", 6789);
System.out.println(templateEngine(template, params));
} 输出为:
Hi 老马, your code is 6789.
小结
本节介绍了正则表达式相关的主要Java API,讨论了如何在Java中表示正则表达式,如何利用它实现文本的切分、验证、查找和替换,对于替换,我们演示了一个简单的模板引擎。
下一节,我们继续探讨正则表达式,讨论和分析一些常见的正则表达式。
以上是電腦程式的思考邏輯 (89) - 正規表示式 (中)的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 如何在iPhone中使Google地圖成為預設地圖
Apr 17, 2024 pm 07:34 PM
如何在iPhone中使Google地圖成為預設地圖
Apr 17, 2024 pm 07:34 PM
iPhone上的預設地圖是Apple專有的地理位置供應商「地圖」。儘管地圖越來越好,但它在美國以外的地區運作不佳。與谷歌地圖相比,它沒有什麼可提供的。在本文中,我們討論了使用Google地圖成為iPhone上的預設地圖的可行性步驟。如何在iPhone中使Google地圖成為預設地圖將Google地圖設定為手機上的預設地圖應用程式比您想像的要容易。請依照以下步驟操作–先決條件步驟–您必須在手機上安裝Gmail。步驟1–開啟AppStore。步驟2–搜尋“Gmail”。步驟3–點選Gmail應用程式旁
 遠端桌面無法驗證遠端電腦的身份
Feb 29, 2024 pm 12:30 PM
遠端桌面無法驗證遠端電腦的身份
Feb 29, 2024 pm 12:30 PM
Windows遠端桌面服務允許使用者遠端存取計算機,對於需要遠端工作的人來說非常方便。然而,當使用者無法連線到遠端電腦或遠端桌面無法驗證電腦身分時,會遇到問題。這可能是由網路連線問題或憑證驗證失敗引起的。在這種情況下,使用者可能需要檢查網路連線、確保遠端電腦是線上的,並嘗試重新連線。另外,確保遠端電腦的身份驗證選項已正確配置也是解決問題的關鍵。透過仔細檢查和調整設置,通常可以解決Windows遠端桌面服務中出現的這類問題。由於存在時間或日期差異,遠端桌面無法驗證遠端電腦的身份。請確保您的計算
 2024 CSRankings全美電腦科學排名發布! CMU霸榜,MIT跌出前5
Mar 25, 2024 pm 06:01 PM
2024 CSRankings全美電腦科學排名發布! CMU霸榜,MIT跌出前5
Mar 25, 2024 pm 06:01 PM
2024CSRankings全美電腦科學專業排名,剛剛發布了!今年,全美全美CS最佳大學排名中,卡內基美隆大學(CMU)在全美和CS領域均名列前茅,而伊利諾大學香檳分校(UIUC)則連續六年穩定地位於第二。佐治亞理工學院則排名第三。然後,史丹佛大學、聖迭戈加州大學、密西根大學、華盛頓大學並列世界第四。值得注意的是,MIT排名下跌,跌出前五名。 CSRankings是由麻省州立大學阿姆赫斯特分校電腦與資訊科學學院教授EmeryBerger發起的全球院校電腦科學領域排名計畫。該排名是基於客觀的
 如何透過C++編寫一個簡單的倒數計時程式?
Nov 03, 2023 pm 01:39 PM
如何透過C++編寫一個簡單的倒數計時程式?
Nov 03, 2023 pm 01:39 PM
C++是一種廣泛使用的程式語言,在編寫倒數計時器方面非常方便且實用。倒數計時程式是一種常見的應用,它能為我們提供非常精確的時間計算和倒數功能。本文將介紹如何使用C++來寫一個簡單的倒數計時程式。實現倒數程序的關鍵就是使用計時器來計算時間的流逝。在C++中,我們可以使用time.h頭檔中的函數來實作計時器的功能。下面是一個簡單的倒數計時程式的程式碼
 iPhone中缺少時鐘應用程式:如何修復
May 03, 2024 pm 09:19 PM
iPhone中缺少時鐘應用程式:如何修復
May 03, 2024 pm 09:19 PM
您的手機中缺少時鐘應用程式嗎?日期和時間仍將顯示在iPhone的狀態列上。但是,如果沒有時鐘應用程序,您將無法使用世界時鐘、碼錶、鬧鐘等多項功能。因此,修復時鐘應用程式的缺失應該是您的待辦事項清單的首位。這些解決方案可以幫助您解決此問題。修復1–放置時鐘應用程式如果您錯誤地從主畫面中刪除了時鐘應用程序,您可以將時鐘應用程式放回原位。步驟1–解鎖iPhone並開始向左側滑動,直到到達「應用程式庫」頁面。步驟2–接下來,在搜尋框中搜尋「時鐘」。步驟3–當您在搜尋結果中看到下方的「時鐘」時,請按住它並
 如何使用任務規劃程式開啟網站
Oct 02, 2023 pm 11:13 PM
如何使用任務規劃程式開啟網站
Oct 02, 2023 pm 11:13 PM
您是否每天在大約相同的時間頻繁地造訪同一網站?這可能會導致花費大量時間打開多個瀏覽器選項卡,並在執行日常任務時使瀏覽器充滿混亂。好吧,打開它而不必手動啟動瀏覽器怎麼樣?這非常簡單,不需要您下載任何第三方應用程序,如下所示。如何設定任務計劃程序以開啟網站?按鍵,在搜尋框中鍵入任務計劃程序,然後按一下開啟。 Windows在右側側邊欄上,按一下「建立基本任務」選項。在名稱欄位中,輸入要開啟的網站的名稱,然後按一下下一步。接下來,在觸發器下,按一下時間頻率並點擊下一步。選擇您希望活動重複多長時間並點擊下一步。選擇啟
 未能開啟這台電腦上的群組原則對象
Feb 07, 2024 pm 02:00 PM
未能開啟這台電腦上的群組原則對象
Feb 07, 2024 pm 02:00 PM
使用電腦時,作業系統偶爾也會故障。今天遇到的問題是在存取gpedit.msc時,系統提示無法開啟群組原則對象,因為可能缺乏正確的權限。未能開啟這台電腦上的群組原則對象解決方法:1、存取gpedit.msc時,系統提示無法開啟該電腦上的群組原則對象,因為缺乏權限。詳細資訊:系統無法定位指定的路徑。 2、用戶點擊關閉按鈕後,就彈出如下錯誤視窗。 3.立即查看日誌記錄,並結合記錄信息,發現問題出在C:\Windows\System32\GroupPolicy\Machine\registry.pol文件
 iOS 17:如何在「訊息」中組織iMessage應用程式
Sep 18, 2023 pm 05:25 PM
iOS 17:如何在「訊息」中組織iMessage應用程式
Sep 18, 2023 pm 05:25 PM
在iOS17中,蘋果不僅增加了幾個新的訊息功能,而且還調整了訊息應用程式的設計,使其外觀更乾淨。現在,所有iMessage應用程式和工具(如相機和照片選項)都可以透過點擊鍵盤上方和文字輸入欄位左側的「+」按鈕來存取。點擊“+”按鈕會彈出一個選單列,該列具有預設的選項順序。從頂部開始,有相機,照片,貼紙,現金(如果可用),音訊和位置。最底部是一個「更多」按鈕,點擊該按鈕時會顯示任何其他已安裝的訊息應用程式(您也可以向上滑動以顯示此隱藏清單)。如何重新組織您的iMessage應用程式您可以透過以下方
