

Scrapy教學--某網站前N篇文章抓取
一、前3000名人員清單頁
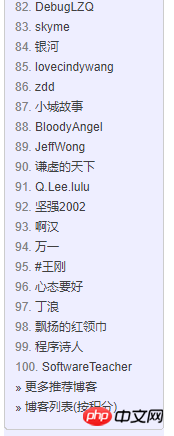

2)分析頁面結構:每一個td都是,一個人員。
第一個small為排名
第二個a標籤是暱稱和用戶名,以及首頁的博客地址。使用者名稱透過位址截取取得
第四個small標籤是,部落格數量以及積分,透過字串分離後可以逐個取得。
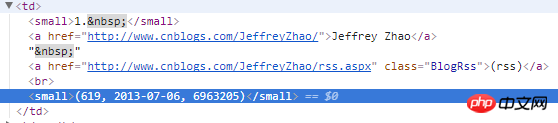
3)程式碼:使用xpath取得標籤及相關的內容,取得到首頁部落格位址後,傳送請求。
def parse(self, response):
for i in response.xpath("//table[@width='90%']//td"):## = CnblogsItem()
item['top'] = i.xpath(
"./small[1]/text()").extract()[0]. 2].strip()
item['nickName'] = i.xpath("./a[1]//text()").extract()[0].strip()
'userName'] = i.xpath(
"./a[1]/@href").extract()[0].split('/')[-2].strip()## = i.xpath(
"./small[2]//text()").extract()[0].lstrip('(').rstrip(')').split(',')
item['score'] = totalAndScore[2].strip()
# print(top)# userName)
# print(total)
# print(score)
# print(score)
## print(score)
## print(score)
## print(score)
## 中 中 return
中使用': 1, 'item': item},
callback=self.parse_page)
二、各人员博客列表页
1)页面结构:通过分析,每篇博客的a标签id中都包含“TitleUrl”,这样就可以获取到每篇博客的地址了。每页面地址,加上default.html?page=2,page跟着变动就可以了。

2)代码:置顶的文字会去除掉。
def parse_page(self, response):
# print(response.meta['nickName'])
#//a[contains(@id,'TitleUrl')]
urlArr = response.url.split('default.aspx?')
if len(urlArr) > 1:
baseUrl = urlArr[-2]
else:
baseUrl = response.url
list = response.xpath("//a[contains(@id,'TitleUrl')]")
for i in list:
item = CnblogsItem()
item['top'] = int(response.meta['item']['top'])
item['nickName'] = response.meta['item']['nickName']
item['userName'] = response.meta['item']['userName']
item['score'] = int(response.meta['item']['score'])
item['pageLink'] = response.url
item['title'] = i.xpath(
"./text()").extract()[0].replace(u'[置顶]', '').replace('[Top]', '').strip()
item['articleLink'] = i.xpath("./@href").extract()[0]
yield scrapy.Request(i.xpath("./@href").extract()[0], meta={'item': item}, callback=self.parse_content)
if len(list) > 0:
response.meta['page'] += 1
yield scrapy.Request(baseUrl + 'default.aspx?page=' + str(response.meta['page']), meta={'page': response.meta['page'], 'item': response.meta['item']}, callback=self.parse_page)
3)对于每篇博客的内容,这里没有抓取。也很简单,分析页面。继续发送请求,找到id为cnblogs_post_body的div就可以了。
def parse_content(self, response):
content = response.xpath("//div[@id='cnblogs_post_body']").extract()
item = response.meta['item']if len(content) == 0:
item['content'] = u'该文章已加密'else:
item['content'] = content[0]yield item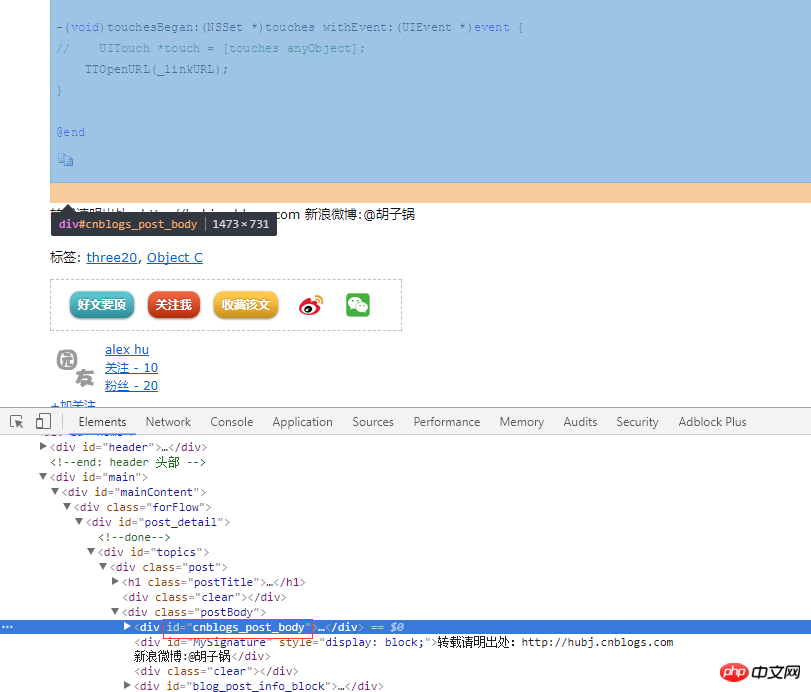
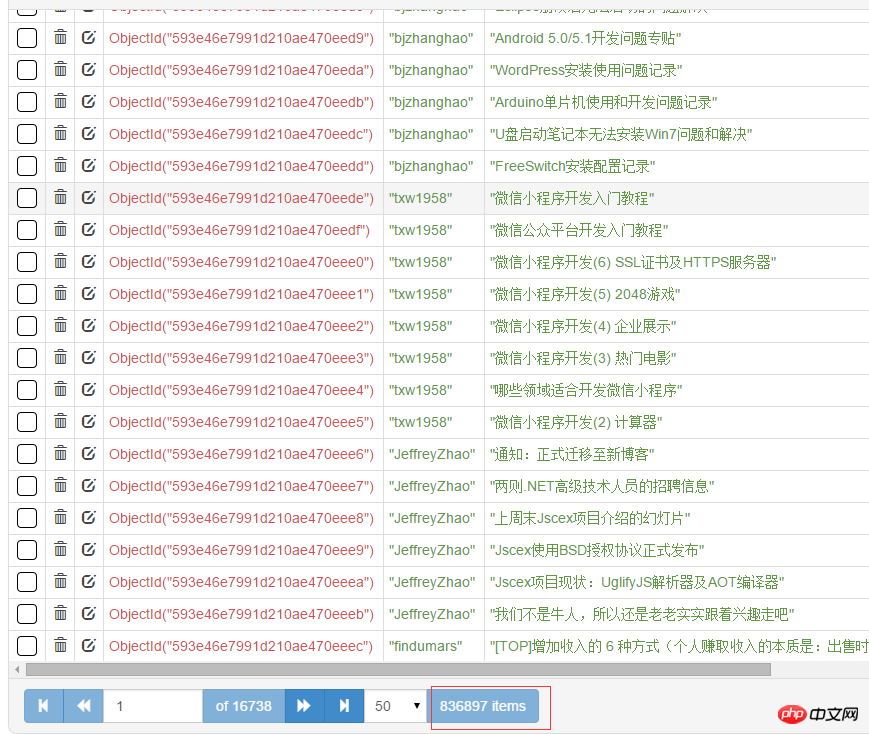
三、数据存储MongoDB
这一部分没什么难的。记着安装pymongo,pip install pymongo。总共有80+万篇文章。
from cnblogs.items import CnblogsItemimport pymongoclass CnblogsPipeline(object):def __init__(self): client = pymongo.MongoClient(host='127.0.0.1', port=27017) dbName = client['cnblogs'] self.table = dbName['articles'] self.table.createdef process_item(self, item, spider):if isinstance(item, CnblogsItem): self.table.insert(dict(item))return item
四、代理及Model类
scrapy中的代理,很简单,自定义一个下载中间件,指定一下代理ip和端口就可以了。
def process_request(self, request, spider): request.meta['proxy'] = 'http://117.143.109.173:80'
Model类,存放的是对应的字段。
class CnblogsItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# 排名top = scrapy.Field() nickName = scrapy.Field() userName = scrapy.Field()# 积分score = scrapy.Field()# 所在页码地址pageLink = scrapy.Field()# 文章标题title = scrapy.Field()# 文章链接articleLink = scrapy.Field()
# 文章内容
content = scrapy.Field()
五、wordcloud词云分析
对每个人的文章进行词云分析,存储为图片。wordcloud的使用用,可参考园内文章。
这里用了多线程,一个线程用来生成分词好的txt文本,一个线程用来生成词云图片。生成词云大概,1秒一个。

# coding=utf-8import sysimport jiebafrom wordcloud import WordCloudimport pymongoimport threadingfrom Queue import Queueimport datetimeimport os
reload(sys)
sys.setdefaultencoding('utf-8')class MyThread(threading.Thread):def __init__(self, func, args):
threading.Thread.__init__(self)
self.func = func
self.args = argsdef run(self):
apply(self.func, self.args)# 获取内容 线程def getTitle(queue, table):for j in range(1, 3001):# start = datetime.datetime.now()list = table.find({'top': j}, {'title': 1, 'top': 1, 'nickName': 1})if list.count() == 0:continuetxt = ''for i in list:
txt += str(i['title']) + '\n'name = i['nickName']
top = i['top']
txt = ' '.join(jieba.cut(txt))
queue.put((txt, name, top), 1)# print((datetime.datetime.now() - start).seconds)def getImg(queue, word):for i in range(1, 3001):# start = datetime.datetime.now()get = queue.get(1)
word.generate(get[0])
name = get[1].replace('<', '').replace('>', '').replace('/', '').replace('\\', '').replace('|', '').replace(':', '').replace('"', '').replace('*', '').replace('?', '')
word.to_file('wordcloudimgs/' + str(get[2]) + '-' + str(name).decode('utf-8') + '.jpg')print(str(get[1]).decode('utf-8') + '\t生成成功')# print((datetime.datetime.now() - start).seconds)def main():
client = pymongo.MongoClient(host='127.0.0.1', port=27017)
dbName = client['cnblogs']
table = dbName['articles']
wc = WordCloud(
font_path='msyh.ttc', background_color='#ccc', width=600, height=600)if not os.path.exists('wordcloudimgs'):
os.mkdir('wordcloudimgs')
threads = []
queue = Queue()
titleThread = MyThread(getTitle, (queue, table))
imgThread = MyThread(getImg, (queue, wc))
threads.append(imgThread)
threads.append(titleThread)for t in threads:
t.start()for t in threads:
t.join()if __name__ == "__main__":
main()六、完整源码地址
附:mongodb内存限制windows:
以上是Scrapy教學--某網站前N篇文章抓取的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 得物使用教程
Mar 21, 2024 pm 01:40 PM
得物使用教程
Mar 21, 2024 pm 01:40 PM
得物APP是當前十分火爆品牌購物的軟體,但是多數的用戶不知道得物APP中功能如何的使用,下方會整理最詳細的使用教程攻略,接下來就是小編為用戶帶來的得物多功能使用教學匯總,有興趣的用戶快來一起看看吧!得物使用教學【2024-03-20】得物分期購怎麼使用【2024-03-20】得物優惠券怎麼獲得【2024-03-20】得物人工客服怎麼找【2024-03-20】得物取件碼怎麼查看【2024-03-20】得物求購在哪裡看【2024-03-20】得物vip怎麼開【2024-03-20】得物怎麼申請退換貨
 夸克瀏覽器使用教學課程
Feb 24, 2024 pm 04:10 PM
夸克瀏覽器使用教學課程
Feb 24, 2024 pm 04:10 PM
夸克瀏覽器是當前十分火爆的一款多功能的瀏覽器,但是多數的小伙伴不知道夸克瀏覽器如何使用其中的功能,下方會整理出來最使用的功能技巧,接下來就是小編為用戶帶來的夸克瀏覽器多功能使用教程匯總,有興趣的用戶快來一起看看吧!夸克瀏覽器使用教學【2024-01-09】:夸克如何掃描試卷看答案【2024-01-09】:夸克瀏覽器怎麼開啟成人模式【2024-01-09】:如何刪除夸克已用空間【2024 -01-09】:怎麼清理夸克網盤儲存空間【2024-01-09】:夸克怎麼取消備份【2024-01-09】:夸克
 升級numpy版本:詳細易學的指南
Feb 25, 2024 pm 11:39 PM
升級numpy版本:詳細易學的指南
Feb 25, 2024 pm 11:39 PM
如何升級numpy版本:簡單易懂的教程,需要具體程式碼範例引言:NumPy是一個重要的Python庫,用於科學計算。它提供了一個強大的多維數組物件和一系列與之相關的函數,可用於進行高效的數值運算。隨著新版本的發布,不斷有更新的特性和Bug修復可供我們使用。本文將介紹如何升級已安裝的NumPy函式庫,以取得最新特性並解決已知問題。步驟1:檢查目前NumPy版本在開始
 DisplayX(顯示器測試軟體)使用教學課程
Mar 04, 2024 pm 04:00 PM
DisplayX(顯示器測試軟體)使用教學課程
Mar 04, 2024 pm 04:00 PM
在購買顯示器的時候對其進行測試是必不可少的一環,能夠避免買到有損壞的,今天小編教大家來使用軟體對顯示器進行測試。方法步驟1.首先要在本站搜尋下載DisplayX這款軟體,安裝打開,會看到提供給用戶很多種檢測方法。 2.使用者點擊常規完全測試,首先是測試顯示器的亮度,使用者調整顯示器使得方框都能看得清楚。 3.之後點選滑鼠即可進入下一節,如果顯示器能夠分辨每個黑色白色區域那表示顯示器還是不錯的。 4.再次按一下滑鼠左鍵,會看到顯示器的灰階測試,顏色過渡越平滑表示顯示器越好。 5.另外在displayx軟體中我們
 夏天,一定要試試拍攝彩虹
Jul 21, 2024 pm 05:16 PM
夏天,一定要試試拍攝彩虹
Jul 21, 2024 pm 05:16 PM
夏天雨後,常常能見到美麗又神奇的特殊天氣景象-彩虹。這也是攝影中可遇而不可求的難得景象,非常出片。彩虹出現有這樣幾個條件:一是空氣中有充足的水滴,二是太陽以較低的角度照射。所以下午雨過天晴後的一段時間內,是最容易看到彩虹的時候。不過彩虹的形成受天氣、光線等條件的影響較大,因此一般只會持續一小段時間,而最佳觀賞、拍攝時間更為短暫。那麼遇到彩虹,怎樣才能合理地記錄下來並拍出質感呢? 1.尋找彩虹除了上面提到的條件外,彩虹通常出現在陽光照射的方向,即如果太陽由西向東照射,彩虹更有可能出現在東
 photoshopcs5是什麼軟體? -photoshopcs5使用教學課程
Mar 19, 2024 am 09:04 AM
photoshopcs5是什麼軟體? -photoshopcs5使用教學課程
Mar 19, 2024 am 09:04 AM
PhotoshopCS是PhotoshopCreativeSuite的縮寫,由Adobe公司出品的軟體,被廣泛用於平面設計和圖像處理,作為新手學習PS,今天就讓小編為您解答一下photoshopcs5是什麼軟體以及photoshopcs5使用教程。一、photoshopcs5是什麼軟體AdobePhotoshopCS5Extended是電影、視訊和多媒體領域的專業人士,使用3D和動畫的圖形和Web設計人員,以及工程和科學領域的專業人士的理想選擇。呈現3D影像並將它合併到2D複合影像中。輕鬆編輯視

 PHP教學:如何將int型別轉換為字串
Mar 27, 2024 pm 06:03 PM
PHP教學:如何將int型別轉換為字串
Mar 27, 2024 pm 06:03 PM
PHP教學:如何將int型別轉換為字串在PHP中,將整型資料轉換為字串是常見的操作。本教學將介紹如何使用PHP內建的函數將int型別轉換為字串,同時提供具體的程式碼範例。使用強制型別轉換:在PHP中,可以使用強制型別轉換的方式將整型資料轉換為字串。這種方法非常簡單,只需要在整型資料前加上(string)即可將其轉換為字串。下面是一個簡單的範例程式碼
