

利用Python抓取花瓣網美圖實例

一:前言
嘀嘀嘀,上车请刷卡。昨天看到了不错的图片分享网——花瓣,里面的图片质量还不错,所以利用selenium+xpath我把它的妹子的栏目下爬取了下来,以图片栏目名称给文件夹命名分类保存到电脑中。这个妹子主页 是动态加载的,如果想获取更多内容可以模拟下拉,这样就可以更多的图片资源。这种之前爬虫中也做过,但是因为网速不够快所以我就抓了19个栏目,一共500多张美图,也已经很满意了。
先看看效果:

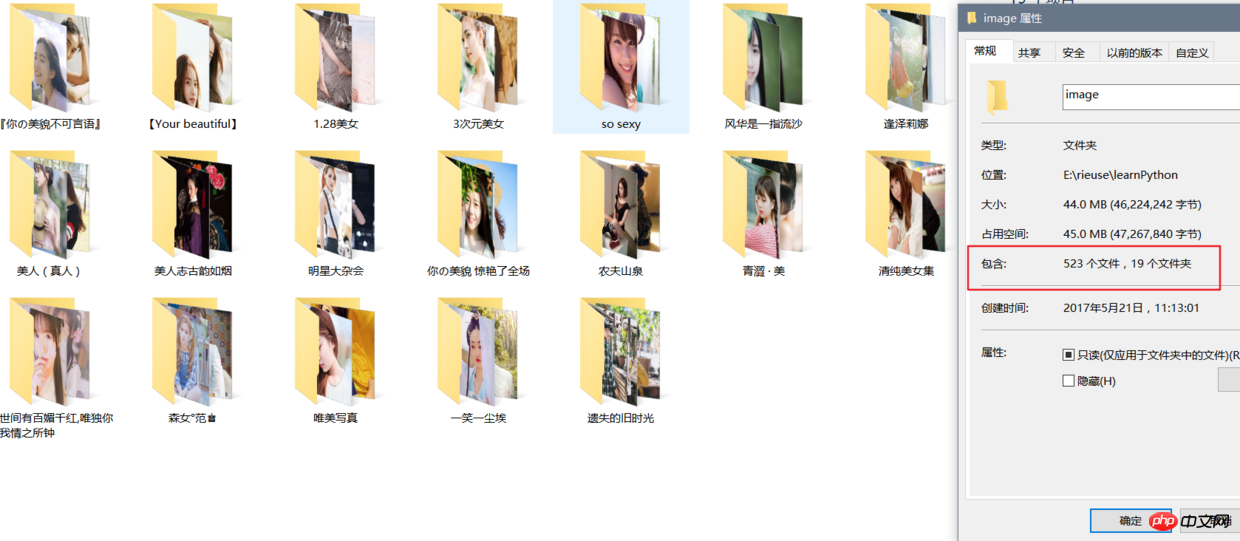
二:运行环境
IDE:Pycharm
Python3.6
lxml 3.7.2
Selenium 3.4.0
requests 2.12.4
三:实例分析
1.这次爬虫我开始做的思路是:进入这个网页然后来获取所有的图片栏目对应网址,然后进入每一个网页中去获取全部图片。(如下图所示)
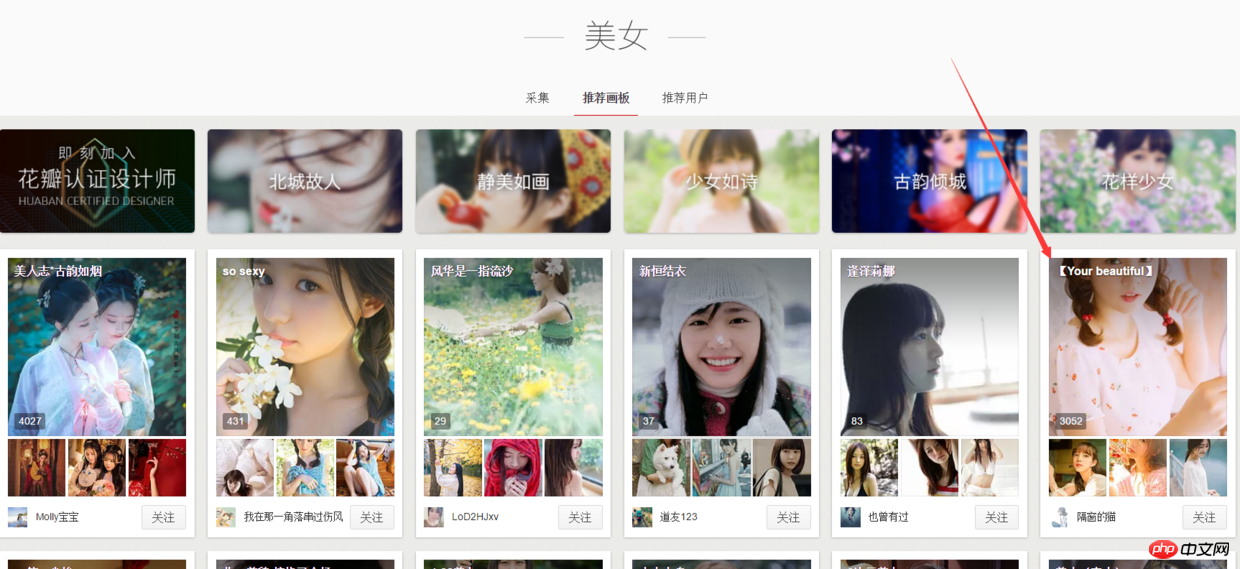
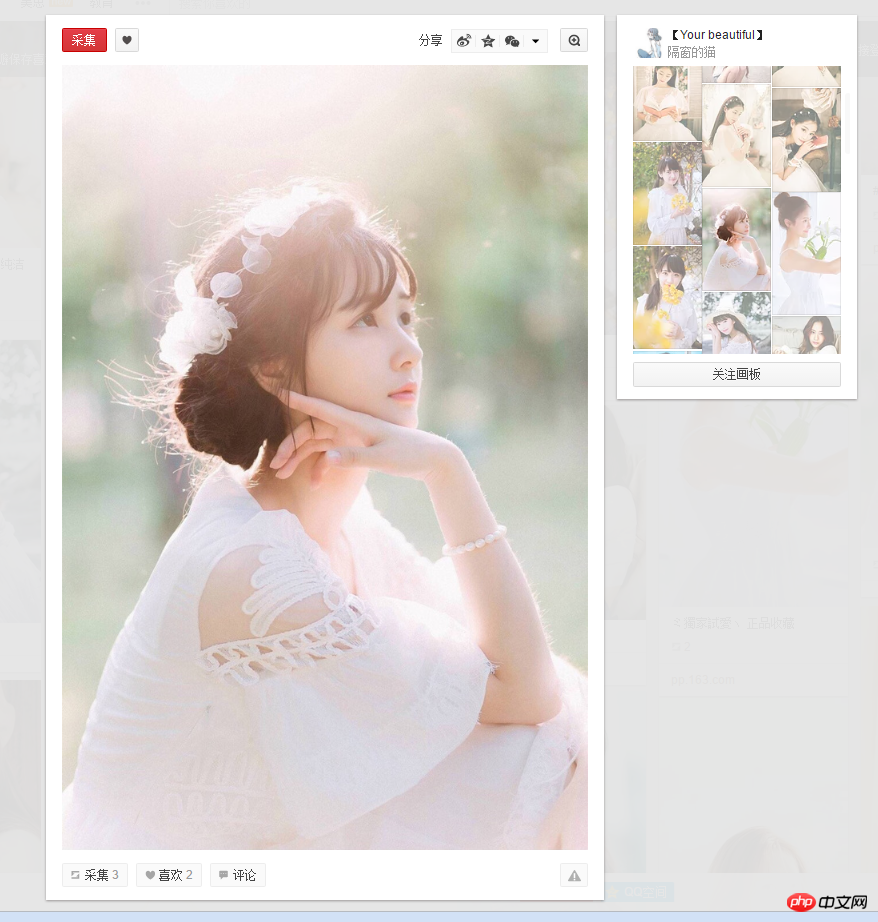
2.但是爬取获取的图片分辨率是236x354,图片质量不够高,但是那个时候已经是晚上1点30之后了,所以第二天做了另一个版本:在这个基础上再进入每个缩略图对应的网页,再抓取像下面这样高清的图片。
四:实战代码
1.第一步导入本次爬虫需要的模块
__author__ = '布咯咯_rieuse' from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.ui import WebDriverWait from selenium import webdriverimport requestsimport lxml.htmlimport os
2.下面是设置webdriver的种类,就是使用什么浏览器进行模拟,可以使用火狐来看它模拟的过程,也可以是无头浏览器PhantomJS来快速获取资源,['--load-images=false', '--disk-cache=true']这个意思是模拟浏览的时候不加载图片和缓存,这样运行速度会加快一些。WebDriverWait标明最大等待浏览器加载为10秒,set_window_size可以设置一下模拟浏览网页的大小。有些网站如果大小不到位,那么一些资源就不加载出来。
# SERVICE_ARGS = ['--load-images=false', '--disk-cache=true']# browser = webdriver.PhantomJS(service_args=SERVICE_ARGS)browser = webdriver.Firefox()wait = WebDriverWait(browser, 10)browser.set_window_size(1400, 900)
3.parser(url, param)这个函数用来解析网页,后面有几次都用用到这些代码,所以直接写一个函数会让代码看起来更整洁有序。函数有两个参数:一个是网址,另一个是显性等待代表的部分,这个可以是网页中的某些板块,按钮,图片等等...
def parser(url, param):
browser.get(url)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, param)))
html = browser.page_source
doc = lxml.html.fromstring(html)return doc4.下面的代码就是解析本次主页面 然后获取到每个栏目的网址和栏目的名称,使用xpath来获取栏目的网页时,进入网页开发者模式后,如图所示进行操作。之后需要用栏目名称在电脑中建立文件夹,所以在这个网页中要获取到栏目的名称,这里遇到一个问题,一些名称不符合文件命名规则要剔除,我这里就是一个 * 影响了。
def get_main_url():
print('打开主页搜寻链接中...')try:
doc = parser('http://huaban.com/boards/favorite/beauty/', '#waterfall')
name = doc.xpath('//*[@id="waterfall"]/div/a[1]/div[2]/h3/text()')
u = doc.xpath('//*[@id="waterfall"]/div/a[1]/@href')for item, fileName in zip(u, name):
main_url = 'http://huaban.com' + item
print('主链接已找到' + main_url)if '*' in fileName:
fileName = fileName.replace('*', '')
download(main_url, fileName)except Exception as e:
print(e)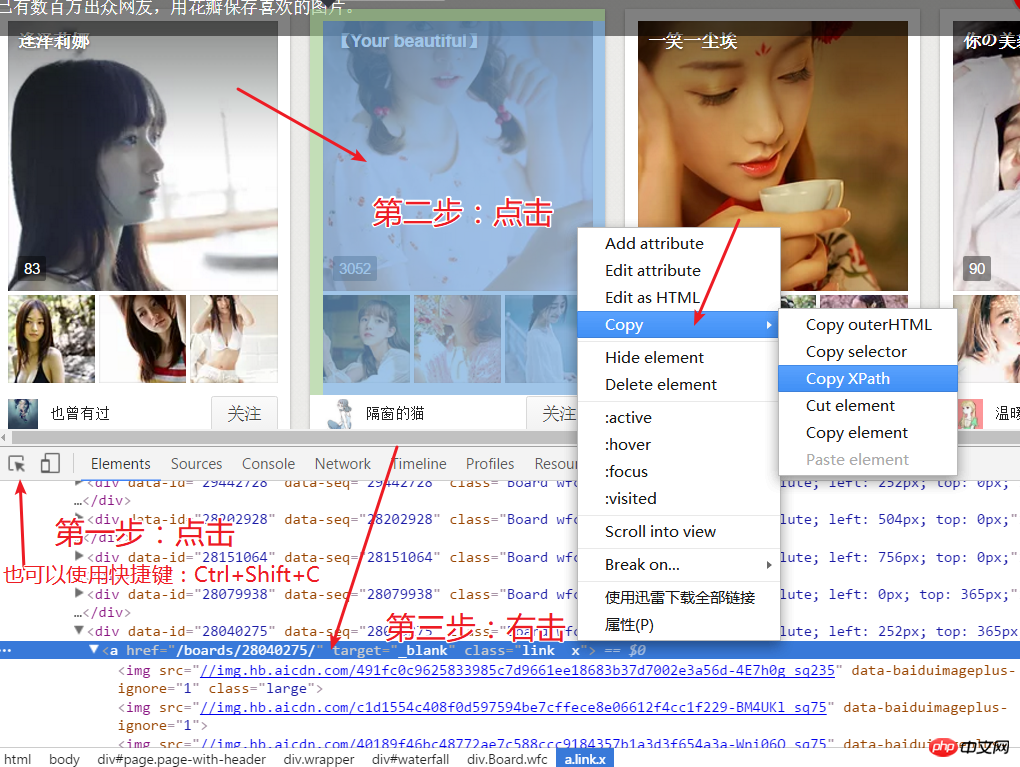
5.前面已经获取到栏目的网页和栏目的名称,这里就需要对栏目的网页分析,进入栏目网页后,只是一些缩略图,我们不想要这些低分辨率的图片,所以要再进入每个缩略图中,解析网页获取到真正的高清图片网址。这里也有一个地方比较坑人,就是一个栏目中,不同的图片存放dom格式不一样,所以我这样做
img_url = doc.xpath('//*[@id="baidu_image_holder"]/a/img/@src') img_url2 = doc.xpath('//*[@id="baidu_image_holder"]/img/@src')
这就把两种dom格式中的图片地址都获取了,然后把两个地址list合并一下。img_url +=img_url2
在本地创建文件夹使用filename = 'image\{}\'.format(fileName) + str(i) + '.jpg'表示文件保存在与这个爬虫代码同级目录image下,然后获取的图片保存在image中按照之前获取的栏目名称的文件夹中。
def download(main_url, fileName):
print('-------准备下载中-------')try:
doc = parser(main_url, '#waterfall')if not os.path.exists('image\\' + fileName):
print('创建文件夹...')
os.makedirs('image\\' + fileName)
link = doc.xpath('//*[@id="waterfall"]/div/a/@href')# print(link)
i = 0for item in link:
i += 1
minor_url = 'http://huaban.com' + item
doc = parser(minor_url, '#pin_view_page')
img_url = doc.xpath('//*[@id="baidu_image_holder"]/a/img/@src')
img_url2 = doc.xpath('//*[@id="baidu_image_holder"]/img/@src')
img_url +=img_url2try:
url = 'http:' + str(img_url[0])
print('正在下载第' + str(i) + '张图片,地址:' + url)
r = requests.get(url)
filename = 'image\\{}\\'.format(fileName) + str(i) + '.jpg'with open(filename, 'wb') as fo:
fo.write(r.content)except Exception:
print('出错了!')except Exception:
print('出错啦!')if __name__ == '__main__':
get_main_url()五:总结
这次爬虫继续练习了Selenium和xpath的使用,在网页分析的时候也遇到很多问题,只有不断练习才能把自己不会部分减少,当然这次爬取了500多张妹纸还是挺养眼的。
以上是利用Python抓取花瓣網美圖實例的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 PHP和Python:代碼示例和比較
Apr 15, 2025 am 12:07 AM
PHP和Python:代碼示例和比較
Apr 15, 2025 am 12:07 AM
PHP和Python各有優劣,選擇取決於項目需求和個人偏好。 1.PHP適合快速開發和維護大型Web應用。 2.Python在數據科學和機器學習領域佔據主導地位。
 CentOS上如何進行PyTorch模型訓練
Apr 14, 2025 pm 03:03 PM
CentOS上如何進行PyTorch模型訓練
Apr 14, 2025 pm 03:03 PM
在CentOS系統上高效訓練PyTorch模型,需要分步驟進行,本文將提供詳細指南。一、環境準備:Python及依賴項安裝:CentOS系統通常預裝Python,但版本可能較舊。建議使用yum或dnf安裝Python3併升級pip:sudoyumupdatepython3(或sudodnfupdatepython3),pip3install--upgradepip。 CUDA與cuDNN(GPU加速):如果使用NVIDIAGPU,需安裝CUDATool
 CentOS上PyTorch的GPU支持情況如何
Apr 14, 2025 pm 06:48 PM
CentOS上PyTorch的GPU支持情況如何
Apr 14, 2025 pm 06:48 PM
在CentOS系統上啟用PyTorchGPU加速,需要安裝CUDA、cuDNN以及PyTorch的GPU版本。以下步驟將引導您完成這一過程:CUDA和cuDNN安裝確定CUDA版本兼容性:使用nvidia-smi命令查看您的NVIDIA顯卡支持的CUDA版本。例如,您的MX450顯卡可能支持CUDA11.1或更高版本。下載並安裝CUDAToolkit:訪問NVIDIACUDAToolkit官網,根據您顯卡支持的最高CUDA版本下載並安裝相應的版本。安裝cuDNN庫:前
 docker原理詳解
Apr 14, 2025 pm 11:57 PM
docker原理詳解
Apr 14, 2025 pm 11:57 PM
Docker利用Linux內核特性,提供高效、隔離的應用運行環境。其工作原理如下:1. 鏡像作為只讀模板,包含運行應用所需的一切;2. 聯合文件系統(UnionFS)層疊多個文件系統,只存儲差異部分,節省空間並加快速度;3. 守護進程管理鏡像和容器,客戶端用於交互;4. Namespaces和cgroups實現容器隔離和資源限制;5. 多種網絡模式支持容器互聯。理解這些核心概念,才能更好地利用Docker。
 Python vs. JavaScript:社區,圖書館和資源
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript:社區,圖書館和資源
Apr 15, 2025 am 12:16 AM
Python和JavaScript在社區、庫和資源方面的對比各有優劣。 1)Python社區友好,適合初學者,但前端開發資源不如JavaScript豐富。 2)Python在數據科學和機器學習庫方面強大,JavaScript則在前端開發庫和框架上更勝一籌。 3)兩者的學習資源都豐富,但Python適合從官方文檔開始,JavaScript則以MDNWebDocs為佳。選擇應基於項目需求和個人興趣。
 CentOS下PyTorch版本怎麼選
Apr 14, 2025 pm 02:51 PM
CentOS下PyTorch版本怎麼選
Apr 14, 2025 pm 02:51 PM
在CentOS下選擇PyTorch版本時,需要考慮以下幾個關鍵因素:1.CUDA版本兼容性GPU支持:如果你有NVIDIAGPU並且希望利用GPU加速,需要選擇支持相應CUDA版本的PyTorch。可以通過運行nvidia-smi命令查看你的顯卡支持的CUDA版本。 CPU版本:如果沒有GPU或不想使用GPU,可以選擇CPU版本的PyTorch。 2.Python版本PyTorch
 minio安裝centos兼容性
Apr 14, 2025 pm 05:45 PM
minio安裝centos兼容性
Apr 14, 2025 pm 05:45 PM
MinIO對象存儲:CentOS系統下的高性能部署MinIO是一款基於Go語言開發的高性能、分佈式對象存儲系統,與AmazonS3兼容。它支持多種客戶端語言,包括Java、Python、JavaScript和Go。本文將簡要介紹MinIO在CentOS系統上的安裝和兼容性。 CentOS版本兼容性MinIO已在多個CentOS版本上得到驗證,包括但不限於:CentOS7.9:提供完整的安裝指南,涵蓋集群配置、環境準備、配置文件設置、磁盤分區以及MinI
 CentOS上PyTorch的分佈式訓練如何操作
Apr 14, 2025 pm 06:36 PM
CentOS上PyTorch的分佈式訓練如何操作
Apr 14, 2025 pm 06:36 PM
在CentOS系統上進行PyTorch分佈式訓練,需要按照以下步驟操作:PyTorch安裝:前提是CentOS系統已安裝Python和pip。根據您的CUDA版本,從PyTorch官網獲取合適的安裝命令。對於僅需CPU的訓練,可以使用以下命令:pipinstalltorchtorchvisiontorchaudio如需GPU支持,請確保已安裝對應版本的CUDA和cuDNN,並使用相應的PyTorch版本進行安裝。分佈式環境配置:分佈式訓練通常需要多台機器或單機多GPU。所
